CTC+pytorch编译配置warp-CTC
CTC
CTC可以生成一个损失函数,用于在序列数据上进行监督式学习,不需要对齐输入数据及标签,经常连接在一个RNN网络的末端,训练端到端的语音和文本识别系统。CTC论文地址:http://www.cs.toronto.edu/%7Egraves/icml_2006.pdf
CTC网络的输入
CTC网络的输入是一个样本(图像)经过网络(一般是CNN+RNN)计算后生成的特征向量(特征序列)。
特征序列里各个向量是按序排布的,是从图像样本上从左到右的一个个小的区间映射过来的,可以设置区间的大小(宽度),宽度越小,获得的特征序列里的特征向量个数越多,极端情况下,可以设置区间宽度为1,这样就会生成width(图像宽度)个特征向量。
CTC网络的计算过程
CTC网络的计算是为了得到特征序列最可能对应的标签对象,对语音识别是一段话,对文本识别是一段文字。
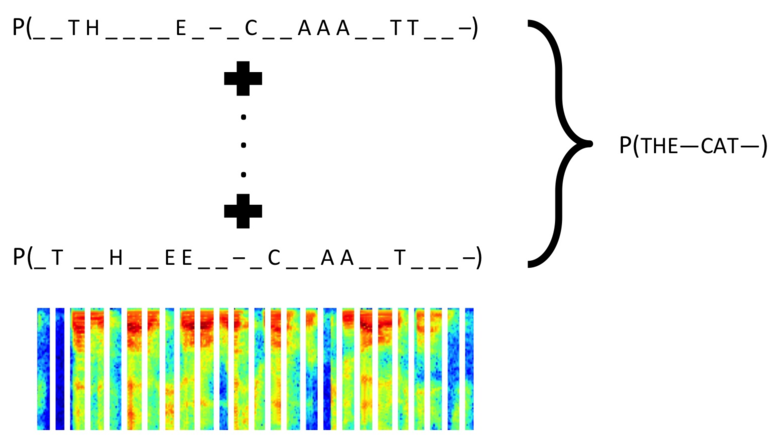
1. 计算特征序列里N个特征向量分别对应的n个可能结果的概率。如果当前的特征向量的预测结果不在样本标签列表里,就置预测结果为blank空格或下划线。计算结果从一个N维的特征序列,得到一个N×n的预测序列。
2. 计算N×n的预测序列对应的所有可能的结果的概率,中间涉及到去除重复字母和blank的操作。
N×n个特征向量对应的所有可能结果有n的N次方个,涉及到组合学,计算所有可能概率的成本会很高,但是CTC运用了动态规划以大幅降低计算的复杂性。
CTC网络的输出
对识别过程,取出最大概率对应的结果作为识别结果输出;
对训练过程,取最大概率对应的结果跟真实标签之间的差异(计算编辑距离等方法),作为训练Loss,反向传输给前端网络。
CTC计算过程示意图:
pytorch安装
GPU版本的:
conda install pytorch=0.3.0 cuda80 -c soumithCPU版本的:
conda install pytorch=0.3.0 -c soumith参考官网: https://pytorch.org/#pip-install-pytorch
warp-CTC安装
warp-CTC是百度开源的一个可以应用在CPU和GPU上高效并行的CTC代码库,对CTC算法进行了并行处理。
warp-CTC安装:
git clone https://github.com/SeanNaren/warp-ctc.git
cd warp-ctc
mkdir build; cd build
cmake ..
make
cd ../pytorch_binding
python setup.py install添加环境变量:
gedit ./.bashrc
export WARP_CTC_PATH=/home/xxx/warp-ctc/build验证pytorch中warp-CTC是否可用GPU例子:
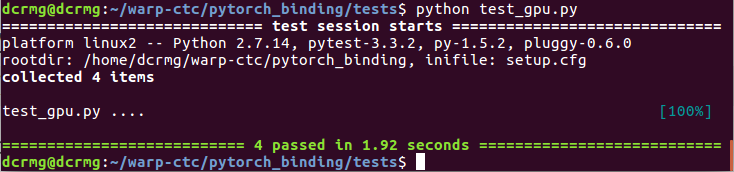
cd /home/xxx/warp-ctc/pytorch_binding/tests
python test_gpu.pyOK输出:
或:
import torch
from torch.autograd import Variable
from warpctc_pytorch import CTCLoss
ctc_loss = CTCLoss()
# expected shape of seqLength x batchSize x alphabet_size
probs = torch.FloatTensor([[[0.1, 0.6, 0.1, 0.1, 0.1], [0.1, 0.1, 0.6, 0.1, 0.1]]]).transpose(0, 1).contiguous()
labels = Variable(torch.IntTensor([1, 2]))
label_sizes = Variable(torch.IntTensor([2]))
probs_sizes = Variable(torch.IntTensor([2]))
probs = Variable(probs, requires_grad=True) # tells autograd to compute gradients for probs
cost = ctc_loss(probs, labels, probs_sizes, label_sizes)
cost.backward()
print('PyTorch bindings for Warp-ctc')PyTorch bindings for Warp-ctc参考:https://github.com/SeanNaren/warp-ctc
CTC+pytorch编译配置warp-CTC的更多相关文章
- Windows安装Pytorch并配置Anaconda与Pycharm
1 开发环境准备 Python 3.7+Anaconda3 5.3.1(64位)+CUDA+Pycharm Community 2 安装Anaconda 2.1 进入官网下载: 根据windows版本 ...
- 转载:Centos7 从零编译配置Memcached
序言 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. Memca ...
- [原创]Centos7 从零编译配置Memcached
序言 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. Memca ...
- Fast RCNN 训练自己数据集 (1编译配置)
FastRCNN 训练自己数据集 (1编译配置) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https:/ ...
- 大型项目使用Automake/Autoconf完成编译配置
http://www.cnblogs.com/xf-linux-arm-java-android/p/3590770.htmlhttp://blog.csdn.net/zengraoli/articl ...
- CentOS6.5 Nginx优化编译配置[续]
继续上文CentOS6.5 Nginx优化编译配置本文记录有关Nginx系统环境的一些细节设置,有关Nginx性能调整除了配置文件吻合服务器硬件之前就是关闭不必要的服务.磁盘操作.文件描述符.内核调整 ...
- 第4阶段——制作根文件系统之编译配置安装busybox(3)
在上一节分析出制作一个最小的根文件系统至少需要: (1)/dev/console(终端控制台, 提供标准输入.标准输出以及标准错误) /dev/null (为空的话就是/dev/null, 所有写到 ...
- Win10 下Cmake编译配置 Opencv3.1 + Cuda7.5 + VS2013
折腾了三天终于配置成功了,在此写下编译配置的全部步骤和遇到的很多坑. 整体介绍: OpenCV 中 CUDA 实现的函数还不是太多,使用前要在OpenCV的官网上确认以下你想要的功能是否已经实现,否则 ...
- qt5.11.2+vs2017环境下opencv3.4.1编译配置
OpenCV是一个开源的计算机库,它可以帮助视觉工作者做很多富有创造性的工作,在图像处理领域扮演着重要的角色.由于opencv3.x的存在,不管你是学生还是研究人员,是专家还是初学者,都可以快速的建立 ...
随机推荐
- hdu 1427 速算24点 dfs暴力搜索
速算24点 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Problem De ...
- poj 3468 A Simple Problem with Integers 线段树加延迟标记
A Simple Problem with Integers Description You have N integers, A1, A2, ... , AN. You need to deal ...
- Android中getLocationOnScreen和getLocationInWindow 获取屏幕大小
需要确定组件在父窗体中的坐标时,使用getLocationInWindow,需要获得组件在整个屏幕的坐标时,使用getLocationOnScreen. 其中location [0]代表x坐标,loc ...
- AngularJs filter 过滤器基础【转】
Filter Ng里的过滤器. currency:把一个数字格式化成货币模式(如$1,234.56).当没有提供任何货币符号时,默认使用当前区域的符号. 使用: HTML:{{ currency_ex ...
- Codeforces 388A - Fox and Box Accumulation
388A - Fox and Box Accumulation 思路: 从小到大贪心模拟. 代码: #include<bits/stdc++.h> using namespace std; ...
- 1月11日Atom 插件安装。
查看已安装的Atom插件(前提:已经安装Atom) 打开终端 输入apm ls命令,回车. 未安装任何插件时,显示如下 Built-in Atom packages (89) ...此处省略... / ...
- Confluence 6 自动添加用户到用户组
默认组成员(Default Group Memberships) 选项在 Confluence 3.5 及后续版本和 JIRA 4.3.3 及后续版本中可用.这字段将会在你选择 'Read Only, ...
- python-day7-数字类型的内置方法
#=====>part1:数字类型#掌握:int,float#了解:Long(在python2中才有),complex# num=10# num=int(10)# print(type(num) ...
- thinkphp if标签
1.thinkphp框架中的if标签,用于html页面中.在html中编写php代码 1).从控制器中得到数据在循环中if else 判断:<volist name="system_r ...
- 手动安装Silverlight 4 Tools for Visual Studio 2010
手动安装吧,将Silverlight 4 Tools for Visual Studio 2010.exe改成rar文件,解压缩,按照下面的步骤安装: 1.silverlight_developer. ...