Java HashSet和HashMap源码剖析
转自:
Java HashSet和HashMap源码剖析
总体介绍
之所以把HashSet和HashMap放在一起讲解,是因为二者在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说HashSet里面有一个HashMap(适配器模式)。因此本文将重点分析HashMap。
HashMap实现了Map接口,允许放入null元素,除该类未实现同步外,其余跟Hashtable大致相同,跟TreeMap不同,该容器不保证元素顺序,根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个HashMap的顺序可能会不同。
根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。JavaHashMap采用的是冲突链表方式。
从上图容易看出,如果选择合适的哈希函数,put()和get()方法可以在常数时间内完成。但在对HashMap进行迭代时,需要遍历整个table以及后面跟的冲突链表。因此对于迭代比较频繁的场景,不宜将HashMap的初始大小设的过大。
有两个参数可以影响HashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
方法剖析
get()
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是算法的核心。
算法思想是首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。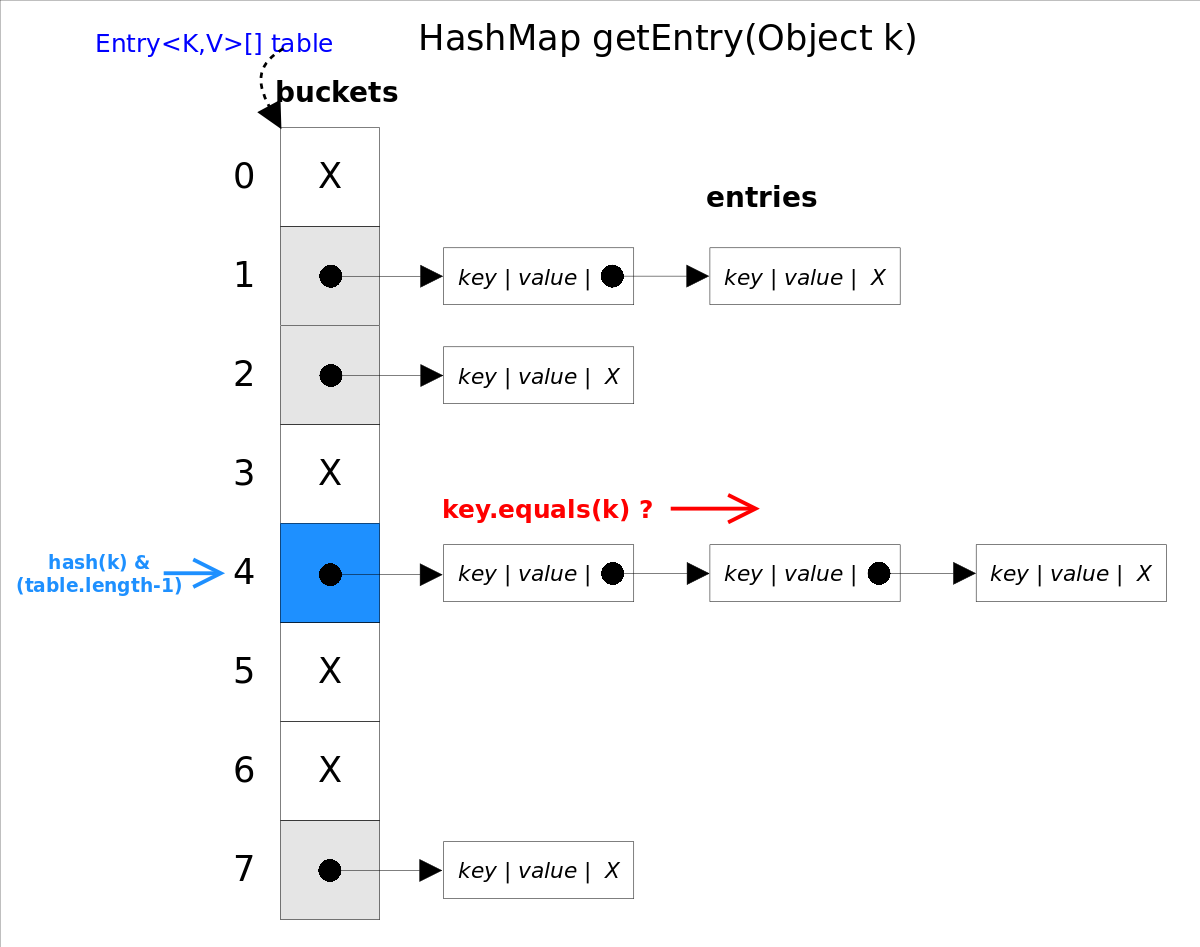
上图中hash(k)&(table.length-1)等价于hash(k)%table.length,原因是HashMap要求table.length必须是2的指数,因此table.length-1就是二进制低位全是1,跟hash(k)相与会将哈希值的高位全抹掉,剩下的就是余数了。
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式为头插法。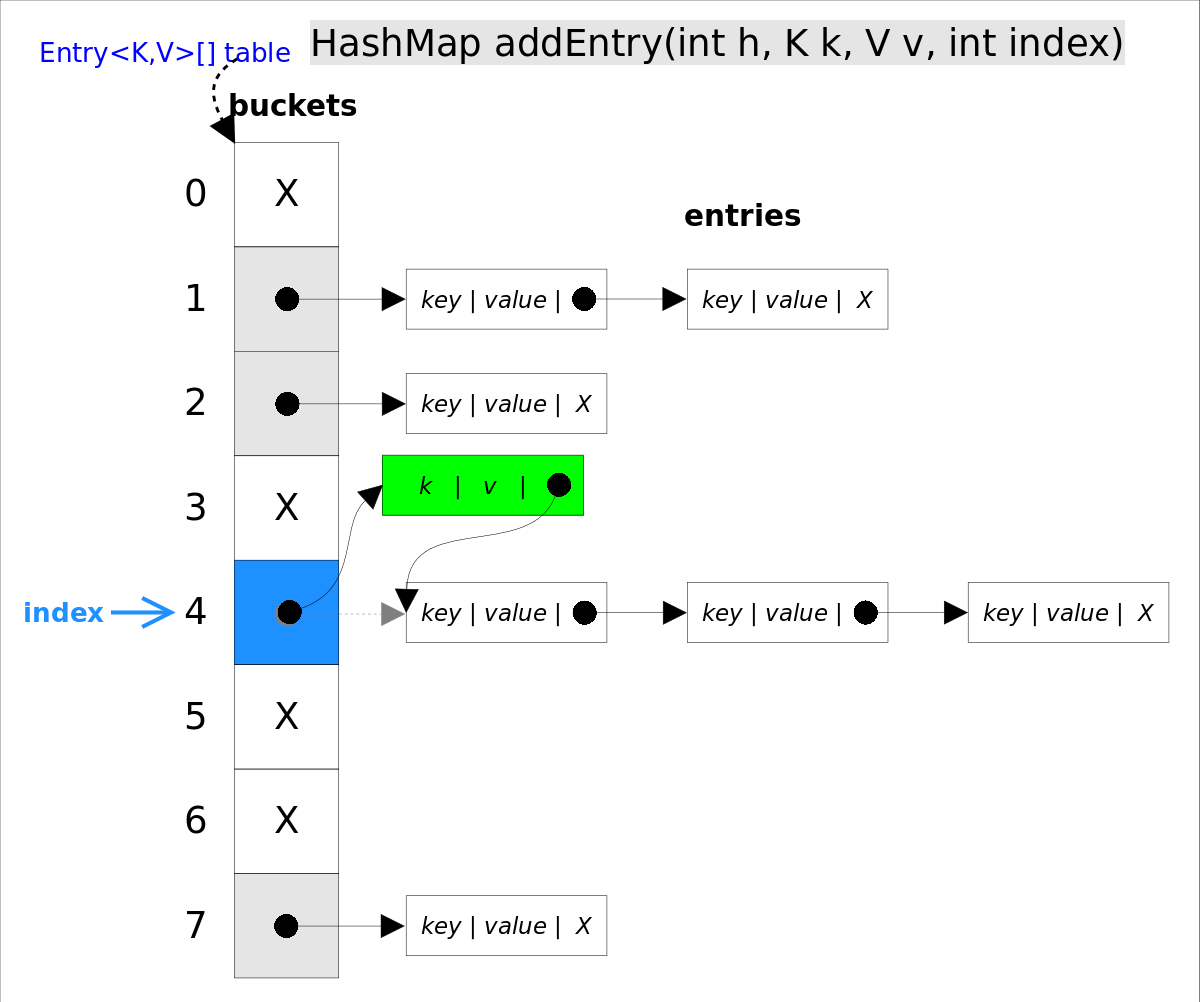
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应指针)。查找过程跟getEntry()过程类似。
//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}HashSet
前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}Java Collections Framework概览
Java ArrayDeque源码剖析
Java LinkedList源码剖析
Java HashSet和HashMap源码剖析
史上最清晰的红黑树讲解(上)
Java HashSet和HashMap源码剖析的更多相关文章
- 【转】Java集合:HashMap源码剖析
Java集合:HashMap源码剖析 一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调 ...
- Java集合:HashMap源码剖析
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- 转:【Java集合源码剖析】HashMap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- 【Java集合源码剖析】HashMap源码剖析
转载出处:http://blog.csdn.net/ns_code/article/details/36034955 HashMap简介 HashMap是基于哈希表实现的,每一个元素是一个key-va ...
- HashMap源码剖析
HashMap源码剖析 无论是在平时的练习还是项目当中,HashMap用的是非常的广,真可谓无处不在.平时用的时候只知道HashMap是用来存储键值对的,却不知道它的底层是如何实现的. 一.HashM ...
- 死磕Java之聊聊HashMap源码(基于JDK1.8)
死磕Java之聊聊HashMap源码(基于JDK1.8) http://cmsblogs.com/?p=4731 为什么面试要问hashmap 的原理
- Java集合---HashMap源码剖析
一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调整大小 5.数据读取 ...
- [转载] Java集合---HashMap源码剖析
转载自http://www.cnblogs.com/ITtangtang/p/3948406.html 一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射 ...
- Java集合:TreeMap源码剖析
一.概念 TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
随机推荐
- nginx configure fastdfs + SSL
./configure \ --prefix=/usr/local/nginx \ --with-http_stub_status_module \ --with-http_ssl_module \ ...
- Vivado+FPGA:如何使用Debug Cores(ILA)在线调试(烧录到flash里可以直接启动)
在Vivado下在线调试是利用ILA进行的,Xilinx官方给出了一个视频,演示了如何使用Vivado的debug cores,下面我根据这个官方视频的截图的来演示一下: 官方的视频使用的软件版本为2 ...
- Xilinx官网查询各个版本软件的手册
在Xilinx官网查询各个版本软件的手册需要点击 See All Versions
- CCFollow
// CCFollow // 作用:创建一个跟随动作 // 参数1:跟随的目标对象 // 跟随范围,离开范围就不再跟随 //创建一个参照物spT // CCSprite ...
- adb无线网络调试
1.如果已经可以用usb连接adb,那么可以通过以下命令切换到无线连接方式. adb tcpip 5555 adb connect 192.168.0.101:5555 通过下面的命令可以切 ...
- 移动WEB开发基础入门
什么是移动WEB开发,我个人理解就是,将网页更好的显示在移动端的一些设置,简单来说就两点如下: 1.流式布局,即百分比自适应布局 将body下的div容器的样式设置如下: div{ width:100 ...
- 【Android】Gesture Detector
Gesture detector Android Touch Screen 与传统Click Touch Screen不同,会有一些手势(Gesture),例如Fling,Scroll等等. 这些Ge ...
- Git详解之Git分支
Git 分支 几乎每一种版本控制系统都以某种形式支持分支.使用分支意味着你可以从开发主线上分离开来,然后在不影响主线的同时继续工作.在很多版本控制系统中,这是个昂贵的过程,常常需要创建一个源代码目录的 ...
- 监听的instance status blocked分析
对于处于NOMOUNT状态的数据库,PMON还没有将服务注册到监听上,这个时候服务的状态是BLOCKED的,对于来自远程的任何连接都会报ORA-12528错误.如下: [oracle@dbtest ~ ...
- Mac在Finder中显示/usr、/tmp、/var等隐藏目录
Finder中默认是不显示/usr./tmp./var等隐藏目录的,通过在终端中输入一下命令来另其显示: #开启 defaults write com.apple.Finder AppleShowAl ...