Spark-自定义排序
一、自定义排序规则-封装类
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* 实现自定义的排序
*/
object MySort1 {
def main(args: Array[String]): Unit = {
//1.spark程序的入口
val conf: SparkConf = new SparkConf().setAppName("MySort1").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf) //2.创建数组
val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78") //3.转换RDD
val grdd1: RDD[String] = sc.parallelize(girl) //4.切分数据
val grdd2: RDD[Girl] = grdd1.map(line => {
val fields: Array[String] = line.split(",") //拿到每个属性
val name = fields(0)
val age = fields(1).toInt
val weight = fields(2).toInt //元组输出
//(name, age, weight)
new Girl(name, age, weight)
}) // val sorted: RDD[(String, String, Int)] = grdd2.sortBy(t => t._2, false)
// val r: Array[(String, String, Int)] = sorted.collect()
// println(r.toBuffer) val sorted: RDD[Girl] = grdd2.sortBy(s => s)
val r = sorted.collect()
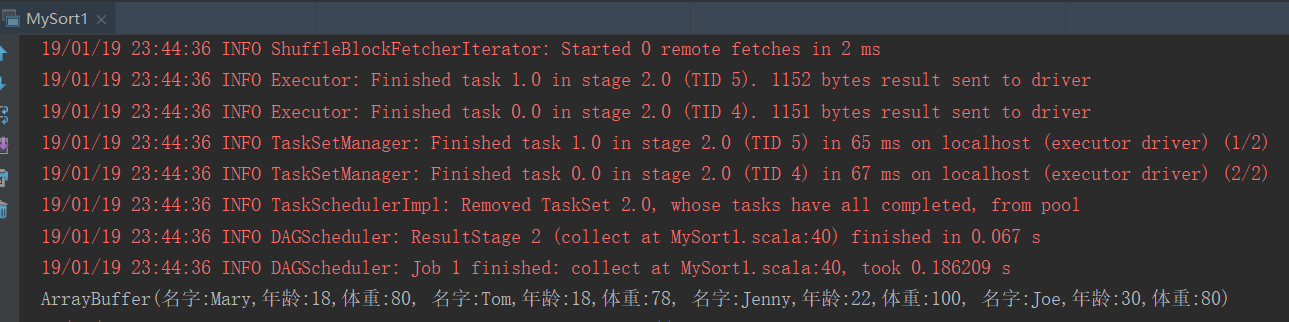
println(r.toBuffer)
sc.stop()
}
} //自定义类 scala Ordered
class Girl(val name: String, val age: Int, val weight: Int) extends Ordered[Girl] with Serializable {
override def compare(that: Girl): Int = {
//如果年龄相同 体重重的往前排
if(this.age == that.age){
//如果正数 正序 负数 倒序
-(this.weight - that.weight)
}else{
//年龄小的往前排
this.age - that.age
} }
override def toString: String = s"名字:$name,年龄:$age,体重:$weight"
}
结果:
 二、
二、
二、自定义排序规则-模式匹配
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object MySort2 {
def main(args: Array[String]): Unit = {
//1.spark程序的入口
val conf: SparkConf = new SparkConf().setAppName("MySort2").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
//2.创建数组
val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78")
//3.转换RDD
val grdd1: RDD[String] = sc.parallelize(girl)
//4.切分数据
val grdd2: RDD[(String, Int, Int)] = grdd1.map(line => {
val fields: Array[String] = line.split(",")
//拿到每个属性
val name = fields(0)
val age = fields(1).toInt
val weight = fields(2).toInt
//元组输出
(name, age, weight)
})
//5.模式匹配方式进行排序
val sorted = grdd2.sortBy(s => Girl2(s._1, s._2, s._3))
val r = sorted.collect()
println(r.toBuffer)
sc.stop()
}
}
//自定义类 scala Ordered
case class Girl2(val name: String, val age: Int, val weight: Int) extends Ordered[Girl2] {
override def compare(that: Girl2): Int = {
//如果年龄相同 体重重的往前排
if(this.age == that.age){
//如果正数 正序 负数 倒序
-(this.weight - that.weight)
}else{
//年龄小的往前排
this.age - that.age
}
}
override def toString: String = s"名字:$name,年龄:$age,体重:$weight"
}
结果:
 三、
三、
三、自定义排序规则-隐式转换
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//定义一个专门处理隐式的类
object ImplicitRules {
//定义隐式规则
implicit object OrderingGirl extends Ordering[Girl1]{
override def compare(x: Girl1, y: Girl1): Int = {
if(x.age == y.age){
//体重重的往前排
-(x.weight - y.weight)
}else{
//年龄小的往前排
x.age - y.age
}
}
}
}
object MySort3 {
def main(args: Array[String]): Unit = {
//1.spark程序的入口
val conf: SparkConf = new SparkConf().setAppName("MySort3").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
//2.创建数组
val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78")
//3.转换RDD
val grdd1: RDD[String] = sc.parallelize(girl)
//4.切分数据
val grdd2 = grdd1.map(line => {
val fields: Array[String] = line.split(",")
//拿到每个属性
val name = fields(0)
val age = fields(1).toInt
val weight = fields(2).toInt
//元组输出
(name, age, weight)
})
import ImplicitRules.OrderingGirl
val sorted = grdd2.sortBy(s => Girl1(s._1, s._2, s._3))
val r = sorted.collect()
println(r.toBuffer)
sc.stop()
}
}
//自定义类 scala Ordered
case class Girl1(val name: String, val age: Int, val weight: Int)
结果:

Spark-自定义排序的更多相关文章
- Spark(三)【RDD中的自定义排序】
在RDD中默认的算子sortBy,sortByKey只能真的值类型数据升序或者降序 现需要对自定义对象进行自定义排序. 一组Person对象 /** * Person 样例类 * @param nam ...
- 大数据学习day22------spark05------1. 学科最受欢迎老师解法补充 2. 自定义排序 3. spark任务执行过程 4. SparkTask的分类 5. Task的序列化 6. Task的多线程问题
1. 学科最受欢迎老师解法补充 day21中该案例的解法四还有一个问题,就是当各个老师受欢迎度是一样的时候,其排序规则就处理不了,以下是对其优化的解法 实现方式五 FavoriteTeacher5 p ...
- Spark基础排序+二次排序(java+scala)
1.基础排序算法 sc.textFile()).reduceByKey(_+_,).map(pair=>(pair._2,pair._1)).sortByKey(false).map(pair= ...
- spark高级排序彻底解秘
排序,真的非常重要! RDD.scala(源码) 在其,没有罗列排序,不是说它不重要! 1.基础排序算法实战 2.二次排序算法实战 3.更高级别排序算法 4.排序算法内幕解密 1.基础排序算法实战 启 ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- Java集合框架实现自定义排序
Java集合框架针对不同的数据结构提供了多种排序的方法,虽然很多时候我们可以自己实现排序,比如数组等,但是灵活的使用JDK提供的排序方法,可以提高开发效率,而且通常JDK的实现要比自己造的轮子性能更优 ...
- DataTable自定义排序
使用JQ DataTable 的时候,希望某列数据可以进行自定义排序,操作如下:(以中文排序和百分比排序为例) 1:定义排序类型: //百分率排序 jQuery.fn.dataTableExt.oSo ...
- 干货之UICollectionViewFlowLayout自定义排序和拖拽手势
使用UICollectionView,需要使用UICollectionViewLayout控制UICollectionViewCell布局,虽然UICollectionViewLayout提供了高度自 ...
- DataGridView 绑定List集合后实现自定义排序
这里只贴主要代码,dataList是已添加数据的全局变量,绑定数据源 datagridview1.DataSource = dataList,以下是核心代码. 实现点击列表头实现自定义排序 priva ...
- 【转】c++中Vector等STL容器的自定义排序
如果要自己定义STL容器的元素类最好满足STL容器对元素的要求 必须要求: 1.Copy构造函数 2.赋值=操作符 3.能够销毁对象的析构函数 另外: 1. ...
随机推荐
- [Ubuntu] 如何在 Lubuntu 安装 python-spidermonkey
SpiderMonkey 是由 Mozilla 开发的 Javascript 引擎,它由 C/C++ 编写而成.Mozilla 在其多个产品中使用了该引擎,包括 Firefox 浏览器. python ...
- 编写java的时候出现“编码GBK的不可映射字符”
今天在编写文件的时候,使用 javac ***.java 但是java文件里面会出现一些中文的信息,So:会报错 方法: 加参数-encoding UTF-8 例如:javac -encodig UT ...
- 关于VC中的附加进程调试
今天领导要求在服务端添加一个获取会议参数的功能接口,接口写好后要自己测试,但是没有客户端的源码,只有客户端安装程序和客户端与服务端发送信令的底层库KSYSClient.dll,而我修改了客户端需要底层 ...
- codeforces水题100道 第十五题 Codeforces Round #262 (Div. 2) A. Vasya and Socks (brute force)
题目链接:http://www.codeforces.com/problemset/problem/460/A题意:Vasya每天用掉一双袜子,她妈妈每m天给他送一双袜子,Vasya一开始有n双袜子, ...
- 关于使用Delphi XE10 进行android开发的一些总结
RAD,可以快速开发出来,但是问题较多最好别用 说实话 做出来的app 太!大!了! 十分的特别的占内存! FireMonkey 真心太大了... 太占内存了 开发一般应用还可 ...
- Qt编写可拖动对象+背景地图+多种样式+多种状态(开源)
在很多项目应用中,需要根据数据动态生成对象显示在地图上,比如地图标注,同时还需要可拖动对象到指定位置显示,能有多种状态指示,为此特意编写本控件,全部开源出来,欢迎大家提建议.同时多多支持整套自定义控件 ...
- 【Python系列】python关键字、符号、数据类型等分类
https://github.com/AndyFlower/Python/blob/master/sample/python前言如下部分为python关键字,操作符号,格式字符.转义字符等,以后有时间 ...
- 使用Struts时,JSP中如何取得各个会话中的参数值?
· request <s:property value="#request.req"/> 或者 ${requestScope.req} · session <s: ...
- LeetCode 17 Letter Combinations of a Phone Number (电话号码字符组合)
题目链接 https://leetcode.com/problems/letter-combinations-of-a-phone-number/?tab=Description HashMap< ...
- linux下find(文件查找)命令的用法总结
关联文章:http://blog.chinaunix.net/uid-24648486-id-2998767.html