mongodb之使用explain和hint性能分析和优化
当你第一眼看到explain和hint的时候,第一个反应就是mysql中所谓的这两个关键词,确实可以看出,这个就是在mysql中借鉴过来的,既然是借鉴
过来的,我想大家都知道这两个关键字的用处,话不多说,速速观看~~~
一:explain演示
1. 构建数据
为了方便演示,我需要create ten data to inventory,而且还是要在no index 的情况下,比如下面这样:
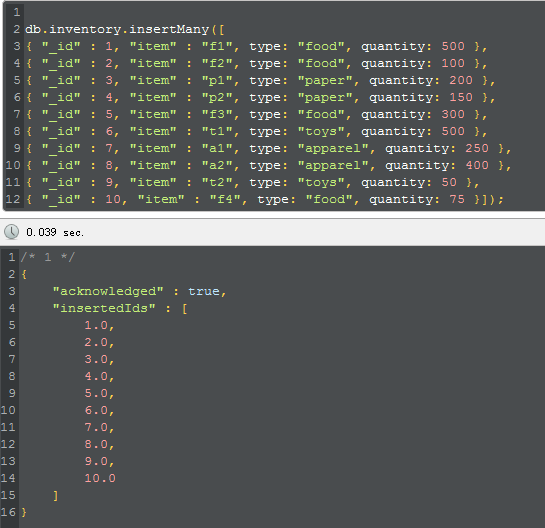
db.inventory.insertMany([
{ "_id" : , "item" : "f1", type: "food", quantity: },
{ "_id" : , "item" : "f2", type: "food", quantity: },
{ "_id" : , "item" : "p1", type: "paper", quantity: },
{ "_id" : , "item" : "p2", type: "paper", quantity: },
{ "_id" : , "item" : "f3", type: "food", quantity: },
{ "_id" : , "item" : "t1", type: "toys", quantity: },
{ "_id" : , "item" : "a1", type: "apparel", quantity: },
{ "_id" : , "item" : "a2", type: "apparel", quantity: },
{ "_id" : , "item" : "t2", type: "toys", quantity: },
{ "_id" : , "item" : "f4", type: "food", quantity: }]);
2. 无索引查询
db.inventory.find(
{ quantity: { $gte: , $lte: } }
).explain("executionStats")
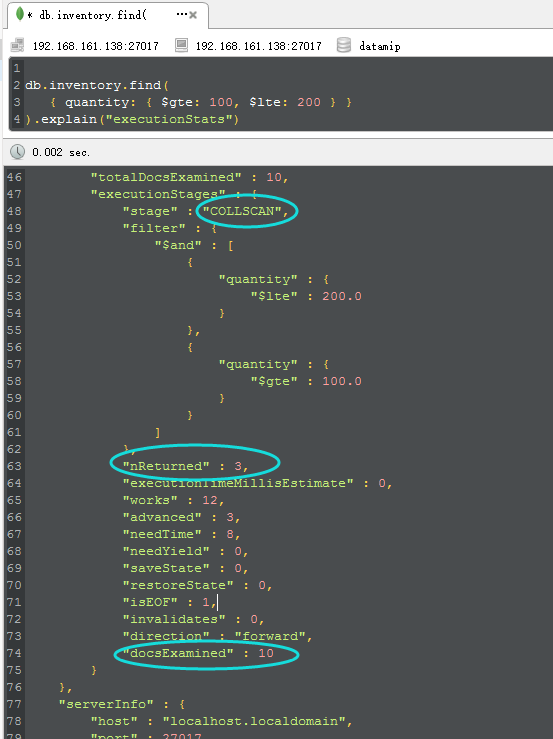
从上图中,我们看到了三个圈圈,这些都是我们在find中非常重要的信息,具体信息解释如下:
<1>COLLSCAN
这个是什么意思呢? 如果你仔细一看,应该知道就是CollectionScan,就是所谓的“集合扫描”,对不对,看到集合扫描是不是就可以直接map到
数据库中的table scan/heap scan呢??? 是的,这个就是所谓的性能最烂最无奈的由来。
<2> nReturned
这个很简单,就是所谓的numReturned,就是说最后返回的num个数,从图中可以看到,就是最终返回了三条。。。
<3> docsExamined
那这个是什么意思呢??就是documentsExamined,检查了10个documents。。。而从返回上面的nReturned。。。
ok,那从上面三个信息中,我们可以得出,原来我examine 10 条数据,最终才返回3条,说明做了7条数据scan的无用功,那么这个时候问题就来了,
如何减少examine的documents。。。
完整的plans如下:
/* 1 */
{
"queryPlanner" : {
"plannerVersion" : ,
"namespace" : "datamip.inventory",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [
{
"quantity" : {
"$lte" : 200.0
}
},
{
"quantity" : {
"$gte" : 100.0
}
}
]
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"$and" : [
{
"quantity" : {
"$lte" : 200.0
}
},
{
"quantity" : {
"$gte" : 100.0
}
}
]
},
"direction" : "forward"
},
"rejectedPlans" : []
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : ,
"executionTimeMillis" : ,
"totalKeysExamined" : ,
"totalDocsExamined" : ,
"executionStages" : {
"stage" : "COLLSCAN",
"filter" : {
"$and" : [
{
"quantity" : {
"$lte" : 200.0
}
},
{
"quantity" : {
"$gte" : 100.0
}
}
]
},
"nReturned" : ,
"executionTimeMillisEstimate" : ,
"works" : ,
"advanced" : ,
"needTime" : ,
"needYield" : ,
"saveState" : ,
"restoreState" : ,
"isEOF" : ,
"invalidates" : ,
"direction" : "forward",
"docsExamined" :
}
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : ,
"version" : "3.2.8",
"gitVersion" : "ed70e33130c977bda0024c125b56d159573dbaf0"
},
"ok" : 1.0
}
3. 使用single field 加速查找
知道前因后果之后,我们就可以进行针对性的建立索引,比如在quality字段之上,如下:
db.inventory.createIndex({ quantity: })
db.inventory.find(
{ quantity: { $gte: , $lte: } }
).explain("executionStats")
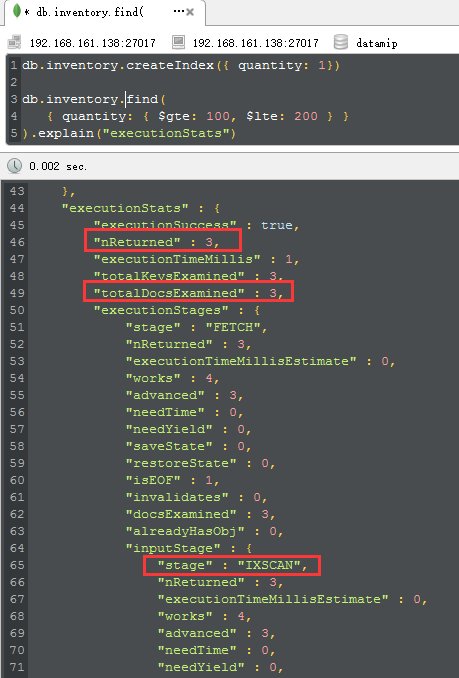
好了,这时候就有意思了,当我们执行完createindex之后,再次explain,4个重要的parameters就漂下来了:
<1> IXSCAN
这个时候再也不是所谓的COLLSCAN了,而是IndexScan,这就说明我们已经命中索引了。
<2> nReturned,totalDocsExamined,totalKeysExamined
从图中可以看到三个参数都是3,这就说明我们的mongodb查看了3个key,3个document,返回3个文档,这个就是所谓的高性能所在,对吧。
二:hint演示
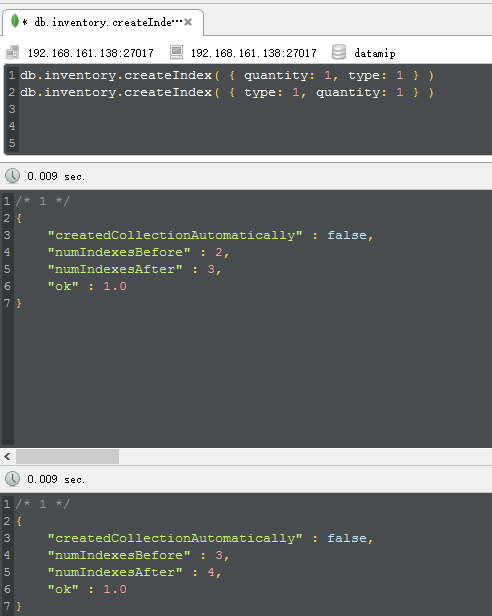
说到hint,我想大家也是知道的,很好玩的一个东西,就是用来force mongodb to excute special index,对吧,为了方便演示,我们做两组复合索
引,比如这次我们在quality和type上构建一下:
building完成之后,我们故意这一个这样的查询,针对quantity是一个范围,而type是一个定值的情况下,我们force mongodb去使用quantity开头
的复合索引,从而强制mongodb give up 那个以{type:1,quantity:1}的复合索引,很有意思哦,比如下图:
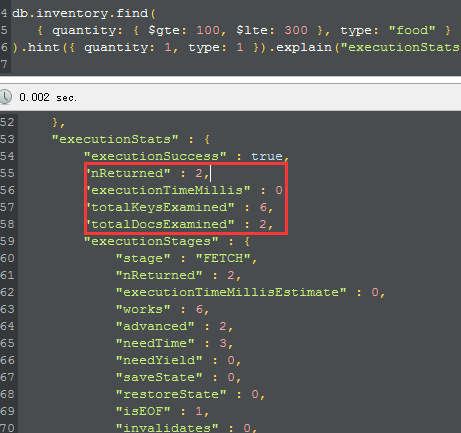
从图中,可以看到,我们检查了6个keys,而从最终找到了2个文档,现在我们就知道了,2和6之间还是有不足的地方等待我们去优化了,对吧,下面
我们不hint来看一下mongodb的最优的plan是怎么样的。

再看上面的图,你应该明白了,mongodb果然执行了那个最优的plan,是不是很好玩,好了,本篇就说到这里,希望对你有帮助~
mongodb之使用explain和hint性能分析和优化的更多相关文章
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- PostgreSQL CPU满(100%)性能分析及优化(转)
PostgreSQL CPU满(100%)性能分析及优化 转自:https://help.aliyun.com/knowledge_detail/43562.html 在数据库运维当中,一个DB ...
- 1.linux服务器的性能分析与优化
[教程主题]:1.linux服务器的性能分析与优化 [课程录制]: 创E [主要内容] [1]影响Linux服务器性能的因素 操作系统级 CPU 目前大部分CPU在同一时间只能运行一个线程,超线程的处 ...
- JDBC性能分析与优化
JDBC性能分析与优化V1.0http://www.docin.com/p-758600080.html
- JVM性能分析与优化
JVM性能分析与优化: http://www.docin.com/p-757199232.html
- 高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化
高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化 作为一名Linux系统管理员,最主要的工作是优化系统配置,使应用在系统上以最优的状态运行.但硬件问题.软件问题.网络环境等 ...
- linux服务器的性能分析与优化(十三)
[教程主题]:1.linux服务器的性能分析与优化 [主要内容] [1]影响Linux服务器性能的因素 操作系统级 Ø CPU 目前大部分CPU在同一时间只能运行一个线程,超线程的处理器可以在同一时间 ...
- Hive性能分析和优化方法
Hive性能分析和优化方法 http://wenku.baidu.com/link?url=LVrnj-mD0OB69-eUH-0b2LGzc2SN76hjLVsGfCdYjV8ogyyN-BSja5 ...
随机推荐
- 小丁带你走进git的世界二-工作区暂存区分支
小丁带你走进git的世界二-工作区暂存区分支 一.Git基本工作流程 1.初始化一个仓库 git init git clone git仓库分为两种情况: 第一种是在现有项目或目录下导入所有文件到 ...
- Android中自定义样式与View的构造函数中的第三个参数defStyle的意义
零.序 一.自定义Style 二.在XML中为属性声明属性值 1. 在layout中定义属性 2. 设置Style 3. 通过Theme指定 三.在运行时获取属性值 1. View的第三个构造函数的第 ...
- [转]keil使用详解
第一节 系统概述 Keil C51是美国Keil Software公司出品的51系列兼容单片机C语言软件开发系统,与汇编相比,C语言在功能上.结构性.可读性.可维护性上有明显的优势,因而易学易用.用过 ...
- 4.2w起步的软件公司创业历程
调查说,中国民营企业的生命期平均是2.8年,如今我的企业已走过近四年,而这一年却是我的迷茫期,不知道何去何从,现在写下 来与大家一起分享一下,写得较为凌乱,大家将就着看一下吧:) 先交待一下自己,我来 ...
- EntityFramework linq 多条件查询,不定条件查询
一.场景描述: 开发的时候,有些查询功能,往往查询的条件是不确定的,用户没有填的不参与到查询中去. 如图1所示,用户可能只要给根据名称来查询即可,有时候开始时间和结束时间并不需要填写. 图 1 二.解 ...
- 从零开始编写自己的C#框架(20)——框架异常处理及日志记录
最近很忙,杂事也多,所以开发本框架也是断断续续的,终于在前两天将前面设定的功能都基本完成了,剩下一些小功能遗漏的以后发现再补上.接下来的章节主要都是讲解在本框架的基础上进行开发的小巧. 本框架主要有四 ...
- YYModel 源码解读(一)之YYModel.h
#if __has_include(<YYModel/YYModel.h>) FOUNDATION_EXPORT double YYModelVersionNumber; FOUNDATI ...
- 自己封装了一个EF的上下文类.,分享一下,顺便求大神指点
using System; using System.Collections.Generic; using System.Configuration; using System.Data; using ...
- 一个简单的webservice的demo(下)winform异步调用webservice
绕了一大圈,又开始接触winform的项目来了,虽然很小吧.写一个winform的异步调用webservice的demo,还是简单的. 一个简单的Webservice的demo,简单模拟服务 一个简单 ...
- Basic Tutorials of Redis(8) -Transaction
Data play an important part in our project,how can we ensure correctness of the data and prevent the ...