Python Tornado框架三(源码结构)
Tornado 是由 Facebook 开源的一个服务器“套装”,适合于做 python 的 web 或者使用其本身提供的可扩展的功能,完成了不完整的 wsgi 协议,可用于做快速的 web 开发,封装了 epoll 性能较好。文章主要以分析 tornado 的网络部分即异步事件处理与上层的 IOstream 类提供的异步IO,其他的模块如 web 的 tornado.web 以后慢慢留作分析。
下面开始我们的 Tornado 之旅,看源代码之前必定需要有一份源码了,大家可以去官网下载一份。这里分析的是4.4.2。
Tornado 的源码组织如下

tornado网络部分最核心的两个模块就是ioloop.py与iostream.py,我们主要分析的就是这两个部分。
- ioloop.py 主要的是将底层的epoll或者说是其他的IO多路复用封装作异步事件来处理。
- iostream.py主要是对于下层的异步事件的进一步封装,为其封装了更上一层的buffer(IO)事件。
我们先来看看 ioloop(文档地址:http://www.tornadoweb.org/en/stable/ioloop.html)
We use epoll (Linux) or kqueue (BSD and Mac OS X) if they are available, or else we fall back on select(). If you are implementing a system that needs to handle thousands of simultaneous connections, you should use a system that supports either epoll or kqueue.
Example usage for a simple TCP server:
import errno
import functools
import ioloop
import socket def connection_ready(sock, fd, events):
while True:
try:
connection, address = sock.accept()
except socket.error, e:
if e.args[0] not in (errno.EWOULDBLOCK, errno.EAGAIN):
raise
return
connection.setblocking(0)
handle_connection(connection, address) sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.setblocking(0)
sock.bind(("", port))
sock.listen(128) # 创建一个ioloop 实例
io_loop = ioloop.IOLoop.instance()
# connection_ready 的第一个参数为 sock,即 socket 的返回值
callback = functools.partial(connection_ready, sock)
# 注册函数,第一个参数是将 sock 转换为标准的描述符,第二个为回调函数,第三个是事件类型
io_loop.add_handler(sock.fileno(), callback, io_loop.READ)
io_loop.start()
可以看到在注释前都是使用了传统的创建服务器的方式,不用多介绍,注意就是把套接口设置为非阻塞方式。
创建ioloop实例,这里是使用了ioloop.IOLoop中的 instance()静态方法,以 @classmethod 方式包装。
在后面的add_handler中,程序为我们的监听套接口注册了一个回调函数和一个事件类型。工作方式是这样,在注册了相应的事件类型和回调函数以后,程序开始启动,如果在相应的套接口上有事件发生(注册的事件类型)那么调用相应的回调函数。
当监听套接口有可读事件发生,意味着来了一个新连接,在回调函数中就可以对这个套接口accept,并调用相应的处理函数,其实应该是处理函数也设置为异步的,将相应的连接套接口也加入到事件循环并注册相应的回调函数,只是这里没有展示出来。
在使用非阻塞方式的accept时候常常返回EAGAIN,EWOULDBLOCK 错误,这里采取的方式是放弃这个连接。
设计模型:
在深入到模块进行分析之前,首先来看看Tornado的设计模型。

从上面的图可以看出,Tornado 不仅仅是一个WEB框架,它还完整地实现了HTTP服务器和客户端,在此基础上提供WEB服务。它可以分为四层:
- 最底层的EVENT层处理IO事件;
- TCP层实现了TCP服务器,负责数据传输;
- HTTP/HTTPS层基于HTTP协议实现了HTTP服务器和客户端;
- 最上层为WEB框架,包含了处理器、模板、数据库连接、认证、本地化等等WEB框架需要具备的功能。
理解Tornado的核心框架之后,就能便于我们后续的理解。
Tornado核心文件解读
为了方便,约定$root指带tornado的根目录。总的来说,要用 Tornado 完成一个网站的构建,其实主要需要以下几个文件:
- $root/tornado/web.py
- $root/tornado/httpserver.py
- $root/tornado/tcpserver.py
- $root/tornado/ioloop.py
- $root/tornado/iostream.py
- $root/tornado/platfrom/epoll.py
- $root/app.py
另外可能还需要一些功能库的支持而需要引入的文件就不列举了,比如util和httputil之类的。来看看每个文件的作用。
- app.py 是自己写的,内容就如 tornado 的 readme 文档里给的示例一样,定义路由规则和 handler,然后创建 application,发起 server 监听,服务器就算跑起来了。
- 紧接着就是 web.py。其中定义了 Application 和 RequestHandler 类,在 app.py 里直接就用到了。Application 是个单例,总揽全局路由,创建服务器负责监听,并把服务器传回来的请求进行转发(__call__)。RequestHandler 是个功能很丰富的类,基本上 web 开发需要的它都具备了,比如redirect,flush,close,header,cookie,render(模板),xsrf,etag等等
- 从 web 跟踪到 httpserver.py 和 tcpserver.py。这两个文件主要是实现 http 协议,解析 header 和 body, 生成request,回调给 appliaction,一个经典意义上的 http 服务器(written in python)。众所周知,这是个很考究性能的一块(IO),所以它和其它很多块都连接到了一起,比如 IOLoop,IOStream,HTTPConnection 等等。这里 HTTPConnection 是实现了 http 协议的部分,它关注 Connection 嘛,这是 http 才有的。至于监听端口,IO事件,读写缓冲区,建立连接之类都是在它的下层--tcp里需要考虑的,所以,tcpserver 才是和它们打交道的地方,到时候分析起来估计很麻烦
- 先说这个IOStream。顾名思义,就是负责IO的。说到IO,就得提缓冲区和IO事件。缓冲区的处理都在它自个儿类里,IO事件的异步处理就要靠 IOLoop 了。
- 然后是 IOLoop。如果你用过 select/poll/epoll/libevent 的话,对它的处理模型应该相当熟悉。简言之,就是一个大大的循环,循环里等待事件,然后处理事件。这是开发高性能服务器的常见模型,tornado 的异步能力就是在这个类里得到保证的
- 最后是 epoll.py。其实这个文件也没干啥,就是声明了一下服务器使用 epoll。选择 select/poll/epoll/kqueue 其中的一种作为事件分发模型,是在 tornado 里自动根据操作系统的类型而做的选择,所以这几种接口是一样的(当然效率不一样),出于简化,直接就epoll吧^_^
- PS。如果你是一个细节控,可能会注意到 tornado 里的回调 callback 函数都不是直接使用的,而是使用 stack_context.wrap 进行了封装。但据我观察,封装前后没多大差别(指逻辑流程),函数的参数也不变。但根据它代码里的注释,这个封装还是相当有用的:
use this whenever saving a callback to be executed later in a different execution context (either in a different thread or asynchronously in the same thread).
所以,我猜,是使用了独有的context来保证在不同环境也能很好的执行。猜测而已,我也没细想,以后有时间再看好,最有用一个简单的流程来做结。d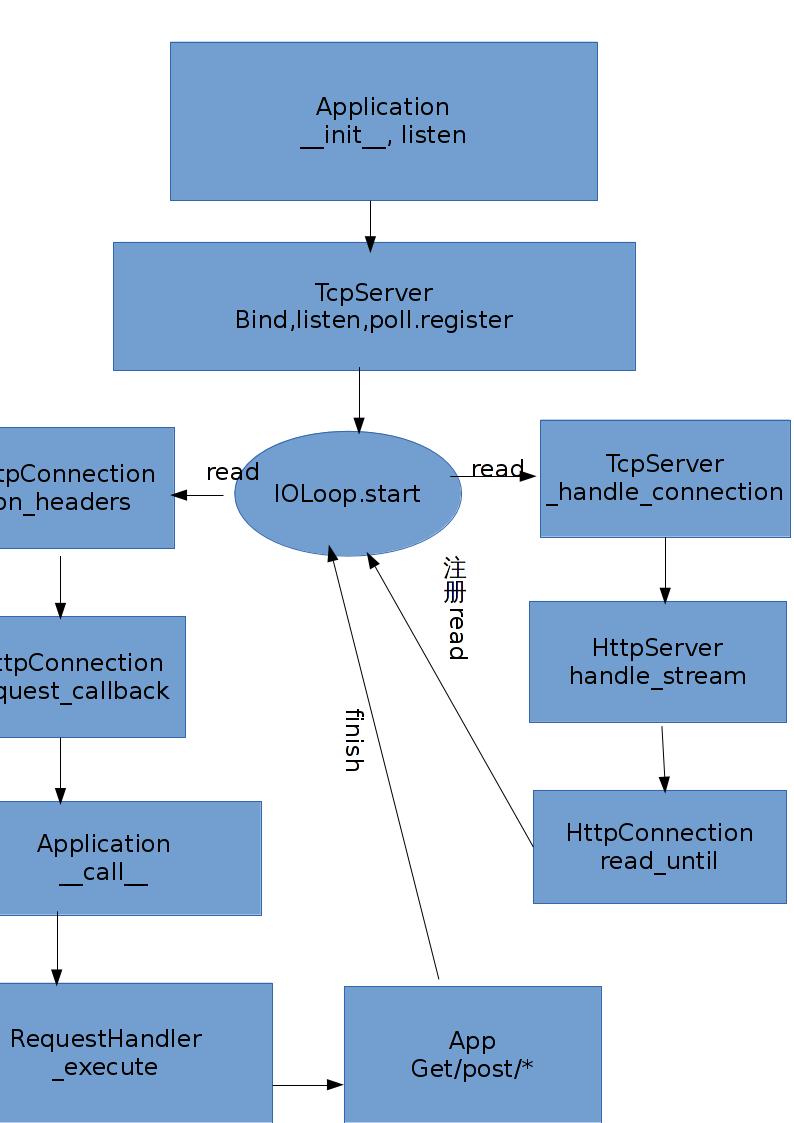
本小节介绍Tornado HTTP服务器的基本流程,分别分析httpserver, ioloop, iostream模块的代码来剖析Tornado底层I/O的内部实现。
httpserver.py中给出了一个简单的http服务器的demo,代码如下所示:
from tornado import httpserver
from tornado import ioloop def handle_request(request):
message = "You requested %s\n" % request.uri
request.write("HTTP/1.1 200 OK\r\nContent-Length: %d\r\n\r\n%s" % (
len(message), message))
request.finish() http_server = httpserver.HTTPServer(handle_request)
http_server.bind(8888)
http_server.start()
ioloop.IOLoop.instance().start()
该http服务器主要使用到IOLoop, IOStream, HTTPServer, HTTPConnection几大模块,分别在代码ioloop.py, iostream.py, httpserver.py中实现。工作的流程如下图所示

服务器的工作流程:首先按照socket->bind->listen顺序创建listen socket监听客户端,并将每个listen socket的fd注册到IOLoop的单例实例中;当listen socket可读时回调_handle_events处理客户端请求;在与客户端通信的过程中使用IOStream封装了读、写缓冲区,实现与客户端的异步读写。
HTTPServer分析
HTTPServer在httpserver.py中实现,继承自TCPServer(netutil.py中实现),是一个无阻塞、单线程HTTP服务器。支持HTTP/1.1协议keep-alive连接,但不支持chunked encoding。服务器支持'X-Real-IP'和'X-Scheme'头以及SSL传输,支持多进程为prefork模式实现。在源代码的注释中对以上描述比较详细的说明,这里就不再细说。
HTTPServer和TCPServer的类结构:
class TCPServer(object):
def __init__(self, io_loop=None, ssl_options=None):
def listen(self, port, address=""):
def add_sockets(self, sockets):
def bind(self, port, address=None, family=socket.AF_UNSPEC, backlog=128):
def start(self, num_processes=1):
def stop(self):
def handle_stream(self, stream, address):
def _handle_connection(self, connection, address):
文章开始部分创建HTTPServer的过程:首先需要定义处理request的回调函数,在tornado中通常使用tornado.web.Application封装。然后构造HTTPServer实例,注册回调函数。接下来监听端口,启动服务器。最后启动IOLoop。
def listen(self, port, address=""):
sockets = bind_sockets(port, address=address)
self.add_sockets(sockets) def bind_sockets(port, address=None, family=socket.AF_UNSPEC, backlog=128):
# 省略sockets创建,address,flags处理部分代码
for res in set(socket.getaddrinfo(address, port, family, socket.SOCK_STREAM,
0, flags)):
af, socktype, proto, canonname, sockaddr = res
# 创建socket
sock = socket.socket(af, socktype, proto)
# 设置socket属性,代码省略 sock.bind(sockaddr)
sock.listen(backlog)
sockets.append(sock)
return sockets def add_sockets(self, sockets):
if self.io_loop is None:
self.io_loop = IOLoop.instance() for sock in sockets:
self._sockets[sock.fileno()] = sock
add_accept_handler(sock, self._handle_connection,
io_loop=self.io_loop) def add_accept_handler(sock, callback, io_loop=None):
if io_loop is None:
io_loop = IOLoop.instance() def accept_handler(fd, events):
while True:
try:
connection, address = sock.accept()
except socket.error, e:
if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
return
raise
# 当有连接被accepted时callback会被调用
callback(connection, address)
io_loop.add_handler(sock.fileno(), accept_handler, IOLoop.READ) def _handle_connection(self, connection, address):
# SSL部分省略
try:
stream = IOStream(connection, io_loop=self.io_loop)
self.handle_stream(stream, address)
except Exception:
logging.error("Error in connection callback", exc_info=True)
这里分析HTTPServer通过listen函数启动监听,这种方法是单进程模式。另外可以通过先后调用bind和start(num_processes=1)函数启动监听同时创建多进程服务器实例,后文有关于此的详细描述。
bind_sockets在启动监听端口过程中调用,getaddrinfo返回服务器的所有网卡信息, 每块网卡上都要创建监听客户端的请求并返回创建的sockets。创建socket过程中绑定地址和端口,同时设置了fcntl.FD_CLOEXEC(创建子进程时关闭打开的socket)和socket.SO_REUSEADDR(保证某一socket关闭后立即释放端口,实现端口复用)标志位。sock.listen(backlog=128)默认设定等待被处理的连接最大个数为128。
返回的每一个socket都加入到IOLoop中同时添加回调函数_handle_connection,IOLoop添加对相应socket的IOLoop.READ事件监听。_handle_connection在接受客户端的连接处理结束之后会被调用,调用时传入连接和ioloop对象初始化IOStream对象,用于对客户端的异步读写;然后调用handle_stream,传入创建的IOStream对象初始化一个HTTPConnection对象,HTTPConnection封装了IOStream的一些操作,用于处理HTTPRequest并返回。至此HTTP Server的创建、启动、注册回调函数的过程分析结束。
HTTPConnection分析
该类用于处理http请求。在HTTPConnection初始化时对self.request_callback赋值为一个可调用的对象(该对象用于对http请求的具体处理和应答)。该类首先读取http请求中header的结束符b("\r\n\r\n"),然后回调self._on_headers函数。request_callback的相关实现在以后的系列中有详细介绍。
def __init__(self, stream, address, request_callback, no_keep_alive=False,
xheaders=False):
self.request_callback = request_callback
# some configuration code
self._header_callback = stack_context.wrap(self._on_headers)
self.stream.read_until(b("\r\n\r\n"), self._header_callback) def _on_headers(self, data):
# some codes
self.request_callback(self._request)
多进程HTTPServer
Tornado的HTTPServer是单进程单线程模式,同时提供了创建多进程服务器的接口,具体实现是在主进程启动HTTPServer时通过process.fork_processes(num_processes)产生新的服务器子进程,所有进程之间共享端口。fork_process的方法在process.py中实现,十分简洁。对fork_process详细的分析,可以参考 番外篇:Tornado的多进程管理分析。
FriendFeed使用nginx提供负载均衡、反向代理服务并作为静态文件服务器,在后端服务器上可以部署多个Tornado实例。一般可以通过Supervisor控制Tornado app,然后再通过nginx对Tornado的输出进行反向代理。 具体可以参考下这篇文章:Supervisord进程管理工具的安装使用。
Tornado RequestHandler和Application类
前面一小节提到了需要了解 web.py 这个文件,这个文件最关键的地方是定义了 Application 和 RequestHandler 类。我们再看看 Tornado 的 Hello World,我们再精简一下,下面是最简单的实例化并启动 Application 的方式:
import ioloop
import web application = web.Application([
(r'/', MainHandler),
])
application.listen(8888)
ioloop.IOLoop.instance().start()
从代码里可以看到的是:应用里定义了 URI 路由和对应的处理类,并以此构建了application对象,然后让这个对象监听在8888端口,最后由 ioloop 单例进入循环,不断分发事件。
这里的URI路由就是r"/",对应处理类就是 MainHandler,它们被放在同一个 tuple 里形成了关联。可以看到,application 是接受一个列表的,因此可以定义多个全局路由对应不同处理,往列表里 append 就是了。
如果只是在 tornado 的框架基础上进行开发,那就只需要不断定义不同的处理类,并把对应路由与其关联即可。
tornado.web 里的 RequestHandler 和 Application 类
Tornado 使用 web 模块的 Application 做URI转发,然后通过 RequestHandler处理请求。 Application 提供了一个 listen 方法作为 HTTPServer 中的 listen 的封装。
初始化 Application 时,一般将处理器直接传入,它会调用 add_handlers 添加这些处理器,初始化还包括 transforms (分块、压缩等)、UI模块、静态文件处理器的初始化。 add_handlers 方法负责添加URI和处理器的映射。
Application 实现 URI 转发时使用了一个技巧,它实现了 __call__ 方法,并将 Application 的实例传递给 HTTPServer ,当监听到请求时,它通过调用 Application 实例触发 __call__ 。 __call__ 方法中完成具体的URI转发工作,并调用已注册的处理器的 _execute 方法,处理请求。
def __call__(self, request):
transforms = [t(request) for t in self.transforms]
handler = None
args = []
kwargs = {}
handlers = self._get_host_handlers(request) # 取得请求的host的一组处理器
if not handlers:
handler = RedirectHandler(
self, request, url="http://" + self.default_host + "/")
else:
for spec in handlers:
match = spec.regex.match(request.path) # 匹配请求的URI
if match:
handler = spec.handler_class(self, request, **spec.kwargs) # 实例化
if spec.regex.groups: # 取得参数
...
if spec.regex.groupindex:
kwargs = dict(
(str(k), unquote(v))
for (k, v) in match.groupdict().iteritems())
else:
args = [unquote(s) for s in match.groups()]
break
if not handler: # 无匹配
handler = ErrorHandler(self, request, status_code=404)
...
handler._execute(transforms, *args, **kwargs) # 处理请求
return handler
RequestHandler 完成具体的请求,开发者需要继承它,并根据需要,覆盖 head 、 get 、 post 、 delete 、 patch 、 put 、 options 等方法,定义处理对应请求的业务逻辑。
RequestHandler 提供了很多钩子,包括 initialize 、 prepare 、 on_finish 、 on_connection_close 、 set_default_headers 等等。
下面是 _execute 的处理流程:
RequestHandler 中涉及到很多 HTTP 相关的技术,包括 Header、Status、Cookie、Etag、Content-Type、链接参数、重定向、长连接等等,还有和用户身份相关的XSRF和CSRF等等。这方面的知识可以参考《HTTP权威指南》。
Tornado默认实现了几个常用的处理器:
- ErrorHandler :生成指定状态码的错误响应。
- RedirectHandler :重定向请求。
- StaticFileHandler :处理静态文件请求。
- FallbackHandler :使可以在Tornado中混合使用其他HTTP服务器。
上面提到了 transform ,Tornado 使用这种机制来对输出做分块和压缩的转换,默认给出了 GZipContentEncoding 和 ChunkedTransferEncoding 。也可以实现自定义的转换,只要实现 transform_first_chunk 和 transform_chunk 接口即可,它们由 RequestHandler 中的 flush 调用。
总的来说,Application对象提供如下几个接口:
- __init__ 接受路由-处理器列表,制定路由转发规则
- listen 建立服务器并监听端口,是对httpserver的封装调用
- add_handlers 添加路由转发规则(包括主机名匹配)
- add_transform 添加输出过滤器。例如gzip,chunk
- __call__ 服务器连接的网关处理接口,一般是被服务器调用
最简单的应该算是 add_transform 了。将一个类添加到列表里就结束了。它会在输出时被调用,比较简单,略过不提。
然后是 listen。它接受端口,地址,其它参数。也很简单,用自身和参数构造 http 服务器,并让服务器监听在端口-地址上。其中涉及到底层 socket 的使用和 ioloop 事件绑定,放在以后再说。总之,可以认为产生了如下效果:在特定端口-地址上创建并监听 socket,并注册了该 socket 的可读事件到自身的__call__方法(亦即,每逢一个新连接到来时,__call__就会被调用)
接下来看 __call__ 方法。这是 python 的一个语法特性,这个函数使得 Application 可以直接被当成函数来使用。
这里有一个问题,为什么不直接定义一个函数例如 call 并在 listen 方法里把 self.call 传给服务器做回调函数,而是使用 self 呢?它们不都是函数吗?有什么区别呢?
区别还是有的。首先,如果使用self.call方法,那么它就是一个纯粹的函数,那么 application 的内部成员就不能用了(比如路由规则表)。而使用 self(也不是self.__call__)传递给服务器做回调,当这个对象被当作函数调用时,__call__会被自动调用,此时对象上下文就被保留下来了。python 里好像经常这么搞。。。
好,来看看__call__的参数:request,HttpRequest对象,在 httputil 里被定义,在这里被用到的是它的 host 和 path 成员,用在路由匹配。忽略错误情况,这个方法的执行流程如下:_get_host_handler(request) 得到该 host 对应的路径路由列表,默认情况下,任何 host 都会被匹配(原因详见__init__),返回的列表直接就是传递给构造 application 时的那个 tuple 列表,当然,对象变了,蛋内容是一样的。然后,对于路径路由列表中的每一个对象,用 request.path 来匹配,如果匹配上了,就生成 RequestHandler 对象,并根据正则表达式解析路径里的参数,可以用数字做键值也可以用字符串做键值。具体见 python 的 re.match.groups()。然后跳出列表,执行_execute() 方法,这个方法在 RequestHandler 里被定义,下次再说,简言之,它的作用是 根据 http 方法转到对应方法,路径正则表达式里解析到的参数也被原样保留传进去。
一直有个疑问,路由规则是什么时候建立的呢?为此,我们先看 add_handlers 方法,它接受两个参数,主机名正则,路径路由列表。同时,我们还要注意到,self.handlers 也是一个列表,是主机名路由列表,它的每个元素是一个 tuple,包含主机名和对应的路径路由列表。如图:

所以,add_handlers 的流程就很简单了:将路径路由列表和主机名合成一个 tuple 添加到 self.handlers 里,这样该主机名就会在_get_host_handler 里被检索,就可以根据主机名找到对应的路径路由规则了。这里需要注意的一个问题是:由于.*的特殊性(它会匹配任意字符),因此总是需要保证它被放置在列表的最后,所以就有了这段代码
if self.handlers and self.handlers[-1][0].pattern == '.*$':
self.handlers.insert(-1, (re.compile(host_pattern), handlers))
之前还说到,默认情况下,所有的主机名都会被匹配,那是因为在__init__方法里,它调用了 add_handlers(".*",handlers)。由于.*匹配所有主机名,所以构造 application 对象时传入的路径路由规则列表就是最终默认路由列表了。
最后看一下__init__方法的流程。它一般接受一个参数,handlers,亦即最终匹配主机的路径路由列表。先设定 transform 列表,再设定静态文件的路由,然后添加主机(.*)的路由列表。
好,回顾一下。Application 的__init__方法设定了.*主机的路径路由规则,listen 方法里开启了服务器并把自身作为回调。__call__方法在服务器 accept 到一个新连接时被调用,主要是根据路由规则转发请求到不同的处理器类,并在处理器里被分派到对应的具体方法中,到此完成请求的处理
RequestHandler的分析
从上一节的流程可以看出,RequestHandler 类把 _execute 方法暴露给了 application 对象,在这个方法里完成了请求的具体分发和处理。因此,我主要看这一方法(当然还包括__init__),其它方法在开发应用时自然会用到,还是比较实用的,比如header,cookie,get/post参数的getter/setter方法,都是必须的。
首先是__init__。负责对象的初始化,在对象被构造时一定会被调用的。
那对象什么时候被调用呢?从上一节可以看到,在.*主机的路径路由列表里,当路径正则匹配了当前请求的路由时,application 就会新建一个 RequestHandler 对象(实际上是子类对象),然后调用 _execute 方法。__init__ 方法接受3个参数 : application, request, **kwargs,分别是application单例,当前请求request 和 kwargs (暂时没被用上。不过可以覆盖initialize方法,里面就有它)。这个kwargs 是静态存储在路由列表里的,它最初是在给 application 设置路由列表时除了路径正则,处理器类之外的第三个对象,是一个字典,一般情况是空的。__init__ 方法也没做什么,就是建立了这个对象和 application, request 的关联就完了。构造器就应该是这样,对吧?
接下来会调用 _execute 方法。
该方法接受三个参数 transforms(相当于 application 的中间件吧,对流程没有影响),*args(用数字做索引时的正则 group),**kwargs(用字符串做键值时的正则 group,与__init__的类似但却是动态的)。该方法先设定好 transform(因为不管错误与否都算输出,因此中间件都必须到位)。然后,检查 http 方法是否被支持,然后整合路径里的参数,检查 XSRF 攻击。然后 prepare()。这总是在业务逻辑前被执行,在业务逻辑后还有个 finish()。业务逻辑代码被定义在子类的 get/post/put/delete 方法里,具体视详细情况而定。
还有一个 finish 方法,它在业务逻辑代码后被执行。缓冲区里的内容要被输出,连接总得被关闭,资源总得被释放,所以这些善后事宜就交给了 finish。与缓冲区相关的还有一个函数 flush,顾名思义它会调用 transforms 对输出做预处理,然后拼接缓冲区一次性输出 self.request.write(headers + chunk, callback=callback)。
以上,就是 handler 的分析。handler 的读与写,实际上都是依靠 request 对象来完成的,而 request 到底如何呢?且看下回分解。
Tornado的核心web框架tornado.web小总结
Tornado的web框架(tornado.web)在web.py中实现,主要包括RequestHandler类(本质为对http请求处理的封装)和Application类(是一些列请求处理的集合,构成的一个web-application,源代码注释不翻译更容易理解:A collection of request handlers that make up a web application)。
RequestHandler分析
RequestHandler提供了一个针对http请求处理的基类封装,方法比较多,主要有以下功能:
- 提供了GET/HEAD/POST/DELETE/PATCH/PUT/OPTIONS等方法的功能接口,具体开发时RequestHandler的子类重写这些方法以支持不同需求的请求处理。
- 提供对http请求的处理方法,包括对headers,页面元素,cookie的处理。
- 提供对请求响应的一些列功能,包括redirect,write(将数据写入输出缓冲区),渲染模板(render, reander_string)等。
- 其他的一些辅助功能,如结束请求/响应,刷新输出缓冲区,对用户授权相关处理等。
Application分析
源代码中的注释写的非常好:
A collection of request handlers that make up a web application. Instances of this class are callable and can be passed directly to HTTPServer to serve the application.
该类初始化的第一个参数接受一个(regexp, request_class)形式的列表,指定了针对不同URL请求所采取的处理方法,包括对静态文件请求的处理(web.StaticFileHandler)。Application类中实现 __call__ 函数,这样该类就成为可调用的对象,由HTTPServer来进行调用。比如下边是httpserver.py中HTTPConection类的代码,该处request_callback即为Application对象。
def _on_headers(self, data):
# some codes...
self.request_callback(self._request)
__call__函数会遍历Application的handlers列表,匹配到相应的URL后通过handler._execute进行相应处理;如果没有匹配的URL,则会调用ErrorHandler。
在Application初始时有一个debug参数,当debug=True时,运行程序时当有代码、模块发生修改,程序会自动重新加载,即实现了auto-reload功能。该功能在autoreload.py文件中实现,是否需要reload的检查在每次接收到http请求时进行,基本原理是检查每一个sys.modules以及_watched_files所包含的模块在程序中所保存的最近修改时间和文件系统中的最近修改时间是否一致,如果不一致,则整个程序重新加载。
def _reload_on_update(modify_times):
for module in sys.modules.values():
# module test and some path handles
_check_file(modify_times, path)
for path in _watched_files:
_check_file(modify_times, path)
Tornado的autoreload模块提供了一个对外的main接口,可以通过下边的方法实现运行test.py程序运行的auto-reload。但是测试了一下,功能有限,相比于django的autorelaod模块(具有较好的封装和较完善的功能)还是有一定的差距。最主要的原因是Tornado中的实现耦合了一些ioloop的功能,因而autoreload不是一个可独立的模块。
# tornado
python -m tornado.autoreload test.py [args...] # django
from django.utils import autoreload
autoreload.main(your-main-func)
asynchronous方法
该方法通常被用为请求处理函数的decorator,以实现异步操作,被@asynchronous修饰后的请求处理为长连接,在调用self.finish之前会一直处于连接等待状态。
总结
在前面小节 Tornado HTTP服务器的基本流程 中,给出了一张tornado httpserver的工作流程图,调用Application发生在HTTPConnection大方框的handle_request椭圆中。那篇文章里使用的是一个简单的请求处理函数handle_request,无论是handle_request还是application,其本质是一个函数(可调用的对象),当服务器接收连接并读取http请求header之后进行调用,进行请求处理和应答。
http_server = httpserver.HTTPServer(handle_request)
http_server = httpserver.HTTPServer(application)
Python Tornado框架三(源码结构)的更多相关文章
- 【Android 系统开发】Android框架 与 源码结构
一. Android 框架 Android框架层级 : Android 自下 而 上 分为 4层; -- Linux内核层; -- 各种库 和 Android运行环境层; -- 应用框架层; -- 应 ...
- Android框架 与 源码结构
一. Android 框架 Android框架层级 : Android 自下 而 上 分为 4层; -- Linux内核层; -- 各种库 和 Android运行环境层; -- 应用框架层; -- 应 ...
- Python 基于python实现的http接口自动化测试框架(含源码)
基于python实现的http+json协议接口自动化测试框架(含源码) by:授客 QQ:1033553122 欢迎加入软件性能测试交流 QQ群:7156436 由于篇幅问题,采用百度网 ...
- OVS 总体架构、源码结构及数据流程全面解析
在前文「从 Bridge 到 OVS」中,我们已经对 OVS 进行了一番探索.本文决定从 OVS 的整体架构到各个组件都进行一个详细的介绍. OVS 架构 OVS 是产品级的虚拟交换机,大量应用在生产 ...
- 『TensorFlow Internals』笔记_源码结构
零.资料集合 知乎专栏:Bob学步 知乎提问:如何高效的学习 TensorFlow 代码?. 大佬刘光聪(Github,简书) 开源书:TensorFlow Internals,强烈推荐(本博客参考书 ...
- JUC同步器框架AbstractQueuedSynchronizer源码图文分析
JUC同步器框架AbstractQueuedSynchronizer源码图文分析 前提 Doug Lea大神在编写JUC(java.util.concurrent)包的时候引入了java.util.c ...
- Java8集合框架——LinkedList源码分析
java.util.LinkedList 本文的主要目录结构: 一.LinkedList的特点及与ArrayList的比较 二.LinkedList的内部实现 三.LinkedList添加元素 四.L ...
- [译] 给PHP开发者的PHP源码-第一部分-源码结构
文章来自:http://www.hoohack.me/2016/02/04/phps-source-code-for-php-developers-ch 原文:http://blog.ircmaxel ...
- 轻量级富文本编辑器wangEditor源码结构介绍
1. 引言 wangEditor——一款轻量级html富文本编辑器(开源软件) 网站:http://www.wangeditor.com/ demo演示:http://www.wangeditor.c ...
随机推荐
- Docker:通过Git部署
这是我翻译的国外博客,如需转载请注明出处和原文链接 我一直听说Docker是个很棒的新事物,但是我一直提不起兴趣,直到我遇到一个切实的问题: 如果通过Docker来部署 Scout ,这么做会轻松一些 ...
- Python_uuid 学习总结
1. 背景知识: UUID: 通用唯一标识符 ( Universally Unique Identifier ), 对于所有的UUID它可以保证在空间和时间上的唯一性. 它是通过MAC地址, 时间戳, ...
- 当您尝试再次安装 SQL Server 时,SQL Server 2008年安装将会失败
症状 当您尝试在一台服务器上安装 Microsoft SQL Server 2008年时,则安装将失败.当您尝试在同一台服务器上重新安装 SQL Server 2008年的相同副本时,此安装也将失败. ...
- poj 2503 Babelfish(字典树或着STL)
Babelfish Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 35828 Accepted: 15320 Descr ...
- html5 webwork
在Web开发的时候经常会遇到浏览器不响应事件进入假死状态,甚至弹出“脚本运行时间过长“的提示框,如果出现这种情况说明你的脚本已经失控了. 一个浏览器至少存在三个线程:js引擎线程(处理js).GUI渲 ...
- iOS #import和@class 区别
@class和#import相似. 1.@class用于 forward-class declaration,只能使用@class, @class class2 @interface class1 { ...
- python入门(五):面向对象
面向对象术语 类(Class): 用来描述具有相同的属性和方法的对象的集合.它定义了该集合中每个对象所共有的属性和方法.对象是类的实例. 类变量:类变量在整个实例化的对象中是公用的.类变量定义在类中且 ...
- 开源的Eclipse的文件转码插件,可以在不影响中文的情况下改变项目文件编
http://www.blogjava.net/lifesting/archive/2008/04/11/192250.html, 感谢此作者! 问题描述: 我们项目开发都统一采用utf-8格式编码, ...
- java关于Timer schedule执行定时任务 !!!!!!!!!
1.在应用开发中,经常需要一些周期性的操作,比如每5分钟执行某一操作等.对于这样的操作最方便.高效的实现方式就是使用java.util.Timer工具类. private java.util.Time ...
- 面试之Java持久层(十)
91,什么是ORM? 对象关系映射(Object-Relational Mapping,简称ORM)是一种为了解决程序的面向对象模型与数据库的关系模型互不匹配问题的技术: 简单的说,O ...