SQL SERVER技术内幕之8 分组集
分组集就是分组(GROUP BY子句)使用的一组属性,在传统的SQL中,一个聚合查询只能定义一个分组集:
假设现在不想生成4个单独的结果集,而是希望生成一个统一的结果集,其中包含所有4个分组集的聚合 数据,下面是经过调整后的代码:
虽然设法得到了期望的结果,但这种解决方案存在两个主要 问题:代码长度和性能。
1.GROUPING SETS从属子句
借助该从属子句,就可以在同一查询中定义多个分组集。只要简单地在GROUPING SETS从属子句的圆括号内列出想要定义的各分组集,分组集之间用逗号分隔开。以下是示例代码:

2.CUBE从属子句
在CUBE从属子句的圆括号内,只须要列出由逗号分隔开的元素成员,就可以得到基于输入成员而定义的所有可能的分组集。例如CUBE(a,b)与GROUPING SETS((a,b),(a),(b),())等价。以下是示例代码:
SELECT empid,custid,SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid,custid);
GROUP BY子句的CUBE从属子句是SQL Server2008引入的,SQL Server的早期版本支持一种非标准的CUBE选项,以下是示例代码:
SELECT empid,custid,SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid,custid
WITH CUBE;
3.ROLLUP从属子句
GROUP BY子句的ROLLUP从属子句也提供了一种定义多个分组集的简略方法。不过ROLLUP认为输入成员之间存在一定的层次关系,从而生成让这种层次关系有意义的所有分组集。换句话说,CUBE(a,b,c)生成由3个输入成员得到的所有8个可能的分组集,而ROLLUP认为这3个输入成员 存在a>b>c的层次关系,所以只生成4个分组集(a,b,c),(a,b),(a),();在早期的SQL Server版本中,应用的是WITH ROLLUP选项。
4.GROUPING 和GROUPING_ID函数
如果一个查询定义了多个分组集,可能还想能够把结果行和分组集关联起来,也就是说为每个结果行标识出它是和哪个分组集关联的。只要所有分组元素都定义为NOT NULL,实现这个要求并不难。
因为Orders表的empid和custid定义为NOT NULL,这些列中的NULL值只代表一个占位符,表示该列并不属于当前的分组集。所以,所有empid和custid均不为NULL的行都与分组集(empid,custid)相关联;所有empid不为NULL,custid为NULL的行都与分组集(empid)有关联,以此类推。
但是,如果表中的分组列定义为允许取NULL值,这时就无法区分结果庥中的NULL中来自原始数据还是占位符。如果想以确定性的方式来判断分组集的关联,一种方法是使用GROUPING函数,这个函数接受一个列名,如果该列是当前分组集的成员,就返回0否则返回1,以下是示例代码: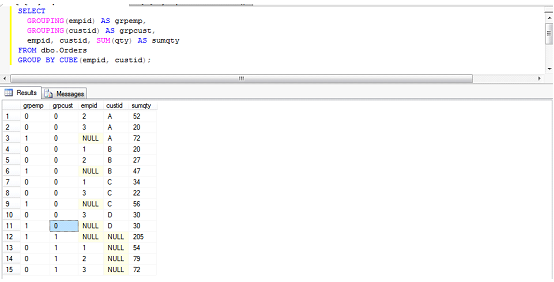
SQL Server 2008引入了一个名为GROUPING_ID的新函数,可以把任何分组集中的所有元素作为函数的输入,例如GROUPING_ID(a,b,c),分组集(a,b,c)可以用整数0
(0*4 + 0*2 + 0*1)表示,因为0代表属于,而分组集(a,c)则可以用整数2(0*4 + 1*2 + 0*1)表示。
SQL SERVER技术内幕之8 分组集的更多相关文章
- SQL Server技术内幕笔记合集
SQL Server技术内幕笔记合集 发这一篇文章主要是方便大家找到我的笔记入口,方便大家o(∩_∩)o Microsoft SQL Server 6.5 技术内幕 笔记http://www.cnbl ...
- 在SQL Server 2012中如何使用分组集
作者:Itzik Ben-Gan 翻译:张洪举 此文摘自作者的<Microsoft SQL Server 2012 T-SQL基础>. 分组集就是你据以分组的一个属性集.传统上,SQL中 ...
- SQL SERVER技术内幕之6 集合查询
1.定义 集合运算会对两个输入查询的结果集进行逐行比较,根据比较结果和所使用的集合运算来确定某一行是否应该包含在集合运算的结果中.因为集合运算是针对集合之间进行的计算,所以集合运算涉及的两个查询不能包 ...
- SQL SERVER技术内幕之5 表表达式
表表达式是一种命名的查询表达式,代表一个有效的关系表.可以像其他表一样,在数据处理语句中使用表表达式.SQL Server支持4种类型的表表达式:派生表(derived table).公用表表达式(C ...
- SQL SERVER技术内幕之10 可编程对象
一.变量 变量用于临时保存数据值,以供在声明它们的同一批处理语句中引用.例如,以下代码先声明一个数据类型为INT的变量@i,再将它赋值为10; DECLARE @i as INT; SET @i = ...
- SQL SERVER技术内幕之10 事务并发
1.事务 1.1事务的定义 事务是作为单个工作单元而执行的一系列操作.定义事务边界有显式和隐式两种.显式事务的定义以BEGIN TRAN作为开始,以COMMIT TRAN提交事务,以ROLLBACK ...
- SQL SERVER技术内幕之3 联接查询
JOIN表运算符对两个输入表进行操作.联接有三种基本类型:交叉联接.内联接和外联接.这三种联接的区别是它们采用的逻辑查询处理步骤各不相同,每种联接都有一套不同的步骤.交叉联接只有一个步骤----笛卡尔 ...
- SQL SERVER技术内幕之7 透视与逆透视
1.透视转换 透视数据(pivoting)是一种把数据从行的状态旋转为列的状态的处理,在这个过程中可能须要对值进行聚合. 每个透视转换将涉及三个逻辑处理阶段,每个阶段都有相关的元素:分组阶段处理相关的 ...
- SQL SERVER技术内幕之4 子查询
最外层查询的结果集会返回给调用者,称为外部查询.内部查询的结果是供外部查询使用的,也称为子查询.子查询可以分成独立子查询和相关子查询两类.独立子查询不依赖于它所属的外部查询,而相关子查询则须依赖它所属 ...
随机推荐
- Leecode刷题之旅-C语言/python-203移除链表元素
/* * @lc app=leetcode.cn id=203 lang=c * * [203] 移除链表元素 * * https://leetcode-cn.com/problems/remove- ...
- [BZOJ4552][Tjoi2016&Heoi2016]排序(二分答案+线段树)
二分答案mid,将>=mid的设为1,<mid的设为0,这样排序就变成了区间修改的操作,维护一下区间和即可 然后询问第q个位置的值,为1说明>=mid,以上 时间复杂度O(nlog2 ...
- 笔记-django- HttpRequest/Response
笔记-django- HttpRequest/Response 1. HttpRequest/Response When a page is requested, Django create ...
- Chrome浏览器保存微信公众号文章中的图片
用chrome浏览器打开微信公众号文章中时,另存为图片时保存的是640.webp,不是图片本身,用IE则没有此问题.大部分chrome插件也无法保存图片. 经过多番尝试,找到一款插件可以批量保存微信公 ...
- 【commons】字符串工具类——commons-lang3之StringUtils
类似工具见Hutool-StrUtil 一.起步 引入maven依赖 <!-- https://mvnrepository.com/artifact/org.apache.commons/com ...
- 上海Uber优步司机奖励政策(1月11日~1月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- JAVA面试中问及HIBERNATE与 MYBATIS的对比
第一方面:开发速度的对比 就开发速度而言,Hibernate的真正掌握要比Mybatis来得难些.Mybatis框架相对简单很容易上手,但也相对简陋些.个人觉得要用好Mybatis还是首先要先理解好H ...
- dubbo入门(一)
1.简介 Dubbo由阿里巴巴开源,是一个分布式服务框架,致力于提供高性能和透明化的RPC(远程过程调用)远程服务调用方案,以及SOA服务治理方案.如果没有分布式的需求,Dbubbo是不需要的,其本质 ...
- EF Core注意事项
流程:https://docs.microsoft.com/en-us/ef/core/get-started/aspnetcore/new-db 1.Both Entity Framework 6. ...
- dva框架之redux相关
dva封装了redux,减少很多重复代码比如action reducers 常量等,本文简单介绍dva redux操作流程. 利用官网的一个加减操作小实例来操作: dva所有的redux操作是放在mo ...