Linux 下的 core dump
$ ulimit -a
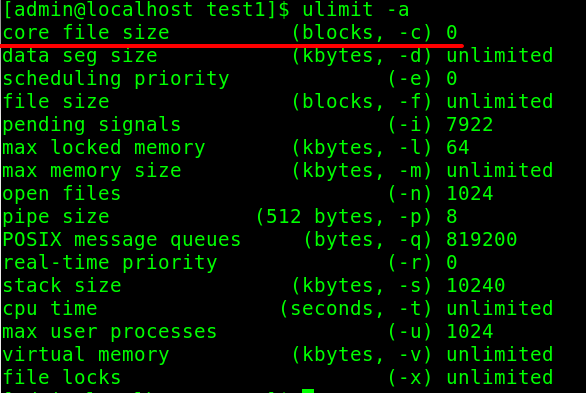
在开发调试阶段可以用 ulimit 命令改变这个限制 ,允许产生 core文件。
$ ulimit -c [size]
$ ulimit -c 1024

当然,如果不想生成core文件,可以使用命令: $ ulimit -c 0
实 例
SIGQUIT信号(键入Ctrl-\) 的默认处理动作是终止进程并且core dump!
写一个死循环程序,前台运行这个程序,然后键入 Ctrl-\ ,使该进程收到SIGQUIT信号后终止并产生core文件
/*************************************************************************
> File Name: test.c
> Author:Lynn-Zhang
> Mail: iynu17@yeah.net
> Created Time: Fri 15 Jul 2016 03:03:57 PM CST
************************************************************************/ #include<stdio.h>
int main()
{
printf("pid is :%d\n",getpid());
while(1);
return 0;
}
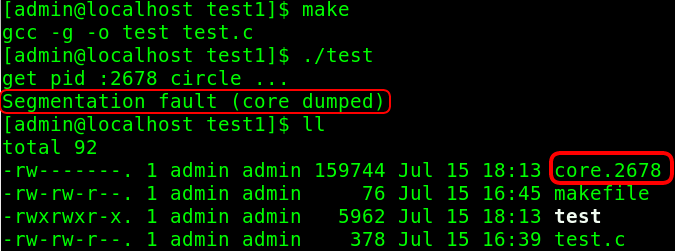
这里的core.2678就是该进程被down掉所对应的core文件,其中的2678是该进程的pid。

除此之外,core文件的内容是二进制的!
Linux 下的 core dump的更多相关文章
- linux下生成core dump文件方法及设置
linux下生成core dump文件方法及设置 from:http://www.cppblog.com/kongque/archive/2011/03/07/141262.html core ...
- linux下生成core dump文件方法
core 文件的简单介绍 当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”).我们可以认为 co ...
- linux下生成core dump文件方法及设置【转】
转自:http://blog.csdn.net/mrjy1475726263/article/details/44116289 源自:http://andyniu.iteye.com/blog/196 ...
- 什么是core dump linux下用core和gdb查询出现"段错误"的地方
什么是core dump linux下用core和gdb查询出现"段错误"的地方 http://blog.chinaunix.net/uid-26833883-id-31932 ...
- linux下用core和gdb查询出现"段错误"的地方【转】
转自:http://blog.chinaunix.net/uid-30091091-id-5754288.html 原文地址:linux下用core和gdb查询出现"段错误"的地方 ...
- Linux系统打开core dump的配置【转】
什么是core dump core dump又叫核心转储, 当程序运行过程中发生异常, 程序异常退出时, 由操作系统把程序当前的内存状况存储在一个core文件中, 叫core dump.core du ...
- 在Linux上利用core dump和GDB调试
段错误(segfault) "段错误"是程序试图操作不允许访问或试图访问的不允许内存的情况.可能导致段错误的原因主要有: 1.试图解引用空指针(你不允许访问内存地址0) 2.试图解 ...
- 在Linux上利用core dump和GDB调试segfault
时常会遇到段错误(segfault),调试非常费劲,除了单元测试和基本测试外,有些时候是在在线环境下,没有基本开发和测试工具,这就需要调试的技能.以前介绍过使用strace进行系统调试和追踪<l ...
- Linux中生成Core Dump系统异常信息记录文件的教程
Linux中生成Core Dump系统异常信息记录文件的教程 http://www.jb51.net/LINUXjishu/473351.html
随机推荐
- poj 1419(图的着色问题,搜索)
题目链接:http://poj.org/problem?id=1419 思路:只怪数据太弱!直接爆搜,按顺序搜索即可. #include<iostream> #include<cst ...
- Spring MVC multipart/form-data Controller 400
问题很简单是解析器定义问题 SpringMVC默认解析器 <bean id="multipartResolver" class="org.springframewo ...
- 面试题思考:java中快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
一:快速失败(fail—fast) 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加.删除.修改),则会抛出Concurrent Modification Exceptio ...
- javamail 发送邮件demo(文字与附件)
package com.get.one; import javax.mail.BodyPart; import javax.mail.Message; import javax.mail.Multip ...
- Less-css预处理Node and VS扩展编译
node编译 第一步:https://nodejs.org/en/ 到node官网下载最新的node 第二步:和普通软件一样把node安装好 第三步:运行-cmd,准备安装less 全局安装(整个电 ...
- Android 界面滑动卡顿分析与解决方案(入门)
Android 界面滑动卡顿分析与解决方案(入门) 导致Android界面滑动卡顿主要有两个原因: 1.UI线程(main)有耗时操作 2.视图渲染时间过长,导致卡顿 目前只讲第1点,第二点相对比较复 ...
- 回顾.NET Remoting分布式开发
记得在下第一次接触.NET Remoting分布式开发是在2003年,那时候是Framework1.0初次亮相之时,Remoting分布式开发是Framework1.0其中一个亮点.经过多年的发展,在 ...
- MySQL 1067
今天在云服务器上装mysql的时候,启动突然报了一个“1067 进程意外终止”的错误,这个错误之前是遇到过的,之前因为my.ini配置basedir路径的时候没有正确配置导致了这个错误,但是今天又出现 ...
- django之单表操作
1.查询方法: <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs ...
- HBA 卡和RAID 卡
HBA卡: 只从HBA的英文解释HOST BUS ADAPTER(主机总线适配器)就能看出来,他肯定是给主机用的,一般HBA就是给主机插上后,给主机扩展出更多的接口,来连接外部的设备.大多数讲到HBA ...