001.hadoop及hbase部署
一 环境准备
1.1 相关环境
- 系统:CentOS 7
#CentOS 6.x系列也可参考,转换相关命令即可。
- hadoop包:hadoop-2.7.0.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/
- hbase包:hbase-1.0.3-bin.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/hbase
- java环境:jdk-8u111-linux-x64.tar.gz
#下载官方地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 其他:zookeeper-3.4.9.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/zookeeper/
1.2 网络环境
|
主机名
|
IP
|
|
master
|
172.24.8.12
|
|
slave01
|
172.24.8.13
|
|
slave02
|
172.24.8.14
|
二 基础环境配置
2.1 配置相关主机名
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# hostnamectl set-hostname slave01
[root@localhost ~]# hostnamectl set-hostname slave02
提示:三台主机都需要配置。
[root@localhost ~]# vi /etc/hosts
……
172.24.8.12 master
172.24.8.13 slave01
172.24.8.14 slave02
[root@localhost ~]# scp /etc/hosts root@slave01:/etc/hosts
[root@localhost ~]# scp /etc/hosts root@slave02:/etc/hosts
提示:直接将hosts文件复制到slave01和slave02。
2.2 防火墙及SELinux
[root@master ~]# systemctl stop firewalld.service #关闭防火墙
[root@master ~]# systemctl disable firewalld.service #禁止开机启动防火墙
[root@master ~]# vi /etc/selinux/config
……
SELINUX=disabled
[root@master ~]# setenforce 0
提示:三台主机都需要配置,配置相关的端口放行和SELinux上下文,也可不关闭。
2.3 时间同步
[root@master ~]# yum -y install ntpdate
[root@master ~]# ntpdate cn.ntp.org.cn
提示:三台主机都需要配置。
三 jdk安装配置
3.1 jdk环境安装
[root@master ~]# cd /usr/
[root@master usr]# tar -zxvf jdk-8u111-linux-x64.tar.gz
提示:三台都需要配置。
3.2 jdk系统变量增加
[root@master ~]# vi .bash_profile
……
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export PATH
export JAVA_HOME=/usr/jdk1.8.0_111
[root@master ~]# scp /root/.bash_profile root@slave01:/root/.bash_profile
[root@master ~]# scp /root/.bash_profile root@slave02:/root/.bash_profile
[root@master ~]# source /root/.bash_profile #重新加载环境变量
提示:
[root@master ~]# java -version #测试
[root@slave01 ~]# java -version #测试
[root@slave02 ~]# java -version #测试
四 SSH无密钥访问
4.1 master-slave01之间无密钥登录
[root@master ~]# ssh-keygen -t rsa
[root@slave01 ~]# ssh-keygen -t rsa
[root@slave02 ~]# ssh-keygen -t rsa
提示:三台都需要生成key密钥。
[root@slave01 ~]# scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave01.id_rsa.pub
#将slave01主机的公钥复制给master,并命名为slave01.id_rsa.pub。
[root@master ~]# cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys
[root@master ~]# cat /root/.ssh/slave01.id_rsa.pub >>/root/.ssh/authorized_keys
[root@master ~]# scp /root/.ssh/authorized_keys slave01:/root/.ssh/
#将master中关于master的公钥和slave01的公钥同时写入authorized_keys文件,并将此文件传送至slave01。
[root@slave02 ~]# scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave02.id_rsa.pub
#将slave02主机的公钥复制给master,并命名为slave02.id_rsa.pub。
[root@master ~]# cat /root/.ssh/id_rsa.pub >/root/.ssh/authorized_keys
注意:此处为防止slave之间互相登录,采用覆盖方式写入。
[root@master ~]# cat /root/.ssh/slave02.id_rsa.pub >>/root/.ssh/authorized_keys
[root@master ~]# scp /root/.ssh/authorized_keys slave02:/root/.ssh/
#将master中关于master的公钥和slave01的公钥同时写入authorized_keys文件,并将此文件传送至slave01。
#以上实现master<---->slave01双向无密钥登录。
[root@master .ssh]# cat slave01.id_rsa.pub >>authorized_keys
#为实现master和slave01、slave02双向无密钥登录,将slave01的公钥重新写入。
[root@master ~]# cat /root/.ssh/authorized_keys #存在master和slave01、slave02的三组公钥
[root@slave01 ~]# cat /root/.ssh/authorized_keys #存在master和slave01的公钥
[root@slave02 ~]# cat /root/.ssh/authorized_keys #存在master和slave02的公钥
五 安装hadoop及配置
5.1 解压hadoop
[root@master ~]# cd /usr/
[root@master usr]# tar -zxvf hadoop-2.7.0.tar.gz
5.2 创建相应目录
[root@master usr]# mkdir /usr/hadoop-2.7.0/tmp #存放集群临时信息
[root@master usr]# mkdir /usr/hadoop-2.7.0/logs #存放集群相关日志
[root@master usr]# mkdir /usr/hadoop-2.7.0/hdf #存放集群信息
[root@master usr]# mkdir /usr/hadoop-2.7.0/hdf/data #存储数据节点信息
[root@master usr]# mkdir /usr/hadoop-2.7.0/hdf/name #存储Name节点信息
5.3 master修改相关配置
5.3.1 修改slaves
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/slaves
slave01
slave02
#删除localhost,添加相应的主机名。
5.3.2 修改core-site.xml
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/core-site.xml
……
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop-2.7.0/tmp</value>
<description>
Abase for other temporary directories.
</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>master</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
5.3.3 修改hdfs-site.xml
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/hdfs-site.xml
……
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop-2.7.0/hdf/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop-2.7.0/hdf/name</value>
<final>true</final>
</property>
</configuration>
5.3.4 修改mapred-site.xml
[root@master ~]# cp /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml
……
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
5.3.5 修改yarn-site.xml
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/yarn-site.xml
<configuration>
……
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
5.4 slave节点安装hadoop
[root@master ~]# scp -r /usr/hadoop-2.7.0 root@slave01:/usr/
[root@master ~]# scp -r /usr/hadoop-2.7.0 root@slave02:/usr/
提示:直接将master的hadoop目录复制到slave01和slave02。
六 系统变量及环境修改
6.1 hadoop环境变量
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/jdk1.8.0_111
[root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/jdk1.8.0_111
6.2 系统环境变量
[root@master ~]# vi /root/.bash_profile
……
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export PATH
export JAVA_HOME=/usr/jdk1.8.0_111
export HADOOP_HOME=/usr/hadoop-2.7.0
export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
[root@master ~]# scp /root/.bash_profile root@slave01:/root/
[root@master ~]# scp /root/.bash_profile root@slave02:/root/
[root@master ~]# source /root/.bash_profile
[root@slave01 ~]# source /root/.bash_profile
[root@slave02 ~]# source /root/.bash_profile
七 格式化namenode并启动
[root@master ~]# cd /usr/hadoop-2.7.0/bin/
[root@master bin]# ./hadoop namenode -format #或者./hdfs namenode -format
提示:其他主机不需要格式化。
[root@master ~]# cd /usr/hadoop-2.7.0/sbin
[root@master sbin]# ./start-all.sh #启动
提示:其他节点不需要启动,主节点启动时,会启动其他节点,查看其他节点进程,slave也可以单独启动datanode和nodemanger进程即可,如下——
[root@slave01 ~]# cd /usr/hadoop-2.7.0/sbin
[root@slave01 ~]# hadoop-daemon.sh start datanode
[root@slave01 ~]# yarn-daemon.sh start nodemanager
八 检测hadoop
8.1 确认验证
http://172.24.8.12:8088/cluster
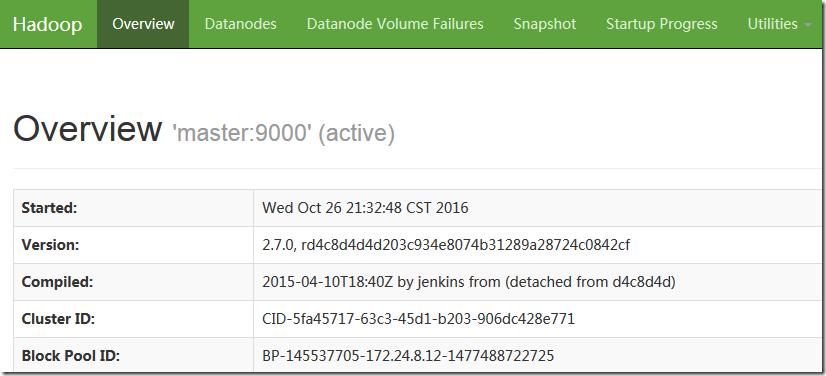
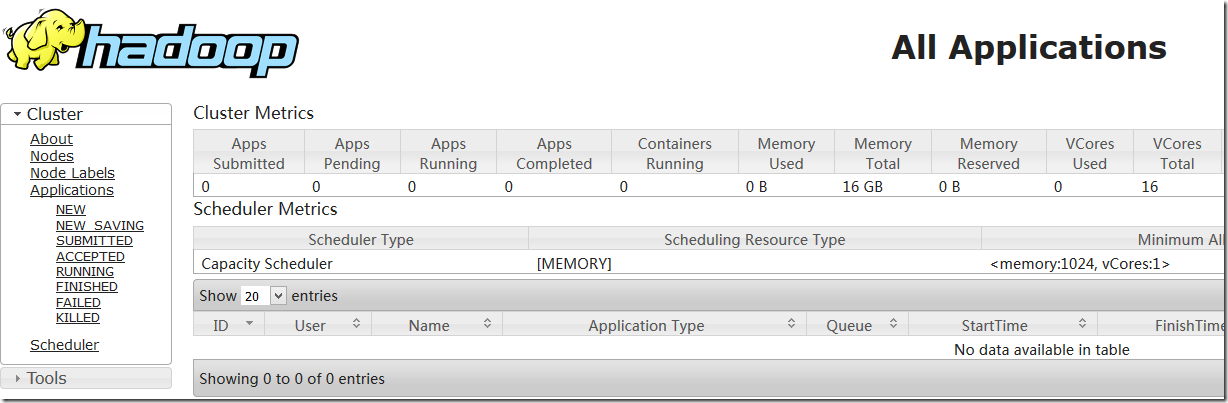
8.2 java检测
[root@master ~]# /usr/jdk1.8.0_111/bin/jps
21346 NameNode
21703 ResourceManager
21544 SecondaryNameNode
21977 Jps
[root@slave01 ~]# jps
16038 NodeManager
15928 DataNode
16200 Jps
15533 SecondaryNameNode
[root@slave02 ~]# jps
15507 SecondaryNameNode
16163 Jps
16013 NodeManager
15903 DataNode
九 安装Zookeeper
9.1 安装并配置zookeeper
[root@master ~]# cd /usr/
[root@master usr]# tar -zxvf zookeeper-3.4.9.tar.gz #解压zookeeper
[root@master usr]# mkdir /usr/zookeeper-3.4.9/data #创建zookeeper数据保存目录
[root@master usr]# mkdir /usr/zookeeper-3.4.9/logs #创建zookeeper日志保存目录
9.2 修改zookeeper相关配置项
[root@master ~]# cp /usr/zookeeper-3.4.9/conf/zoo_sample.cfg /usr/zookeeper-3.4.9/conf/zoo.cfg
#从模板复制zoo配置文件
[root@master ~]# vi /usr/zookeeper-3.4.9/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper-3.4.9/data
dataLogDir=/usr/zookeeper-3.4.9/logs
clientPort=2181
server.1=master:2888:3888
server.2=slave01:2888:3888
server.3=slave02:2888:3888
9.3 创建myid
[root@master ~]# vi /usr/zookeeper-3.4.9/data/myid
1
注意:此处创建的文件myid内容为zoo.cfg配置中server.n中的n。即master为1,slave01为2,slave02为3。
9.4 修改环境变量
[root@master ~]# vi /root/.bash_profile #修改环境变量
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin #增加zookeeper变量路径
export PATH
export JAVA_HOME=/usr/jdk1.8.0_111
export HADOOP_HOME=/usr/hadoop-2.7.0
export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export ZOOKEEPER_HOME=/usr/zookeeper-3.4.9/ #增加zookeeper路径
[root@master ~]# source /root/.bash_profile
9.5 Slave节点的zookeeper部署
[root@master ~]# scp -r /usr/zookeeper-3.4.9/ root@slave01:/usr/
[root@master ~]# scp -r /usr/zookeeper-3.4.9/ root@slave02:/usr/
[root@master ~]# scp /root/.bash_profile root@slave01:/root/
[root@master ~]# scp /root/.bash_profile root@slave02:/root/
提示:三台主机都需要配置,依次将zookeeper和环境变量文件profile复制到slave01和slave02。
9.6 Slave主机修改myid
[root@slave01 ~]# vi /usr/zookeeper-3.4.9/data/myid
2
[root@slave02 ~]# vi /usr/zookeeper-3.4.9/data/myid
3
9.7 启动zookeeper
[root@master ~]# cd /usr/zookeeper-3.4.9/bin/
[root@master bin]# ./zkServer.sh start
[root@slave01 ~]# cd /usr/zookeeper-3.4.9/bin/
[root@slave01 bin]# ./zkServer.sh start
[root@slave02 ~]# cd /usr/zookeeper-3.4.9/bin/
[root@slave02 bin]# ./zkServer.sh start
提示:三台主机都需要启动,命令方式一样。
十 安装及配置hbase
10.1 安装hbase
[root@master ~]# cd /usr/
[root@master usr]# tar -zxvf hbase-1.0.3-bin.tar.gz #解压hbase
[root@master ~]# mkdir /usr/hbase-1.0.3/logs #创建hbase的日志存放目录
[root@master ~]# mkdir /usr/hbase-1.0.3/temp #hbase的临时文件存放目录
[root@master ~]# mkdir /usr/hbase-1.0.3/temp/pid #hbase相关pid文件存放目录
10.2 修改环境变量
[root@master ~]# vi /root/.bash_profile
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin
export PATH
export JAVA_HOME=/usr/jdk1.8.0_111
export HADOOP_HOME=/usr/hadoop-2.7.0
export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export ZOOKEEPER_HOME=/usr/zookeeper-3.4.9/
export HBASE_HOME=/usr/hbase-1.0.3
export HBASE_LOG_DIR=$HBASE_HOME/logs
[root@master ~]# source /root/.bash_profile
[root@master ~]# scp /root/.bash_profile slave01:/root/
[root@master ~]# scp /root/.bash_profile slave02:/root/
提示:三台主机都需要配置,可直接将环境变量复制给slave01和slave02。
[root@master ~]# vi /usr/hbase-1.0.3/conf/hbase-env.sh
export JAVA_HOME=/usr/jdk1.8.0_111
export HBASE_MANAGES_ZK=true
export HBASE_CLASSPATH=/usr/hadoop-2.7.0/etc/hadoop/
export HBASE_PID_DIR=/usr/hbase-1.0.3/temp/pid
注意:分布式运行的一个Hbase依赖一个zookeeper集群。所有的节点和客户端都必须能够访问zookeeper。默认Hbase会管理一个zookeep集群,即HBASE_MANAGES_ZK=true,这个集群会随着 Hbase 的启动而启动。也可以采用独立的 zookeeper 来管理 hbase,即HBASE_MANAGES_ZK=false。
10.4 修改hbase-site.xml
[root@master ~]# vi /usr/hbase-1.0.3/conf/hbase-site.xml
……
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave01,slave02</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper-3.4.9/data</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/hbase-1.0.3/temp</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
</property>
<property>
<name>hbase.client.scanner.caching</name>
<value>200</value>
</property>
<property>
<name>hbase.balancer.period</name>
<value>300000</value>
</property>
<property>
<name>hbase.client.write.buffer</name>
<value>10485760</value>
</property>
<property>
<name>hbase.hregion.majorcompaction</name>
<value>7200000</value>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>67108864</value>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>1048576</value>
</property>
<property>
<name>hbase.server.thread.wakefrequency</name>
<value>30000</value>
</property>
</configuration>
#直接将imxhy01的相关配置传送给imxhy02即可。
[root@master ~]# scp -r /usr/hbase-1.0.3 root@imxhy02:/usr/
10.5 配置 regionservers
[root@master ~]# vi /usr/hbase-1.0.3/conf/regionservers
slave01
slave02
十一 启动hbase
[root@master ~]# cd /usr/hbase-1.0.3/bin/
[root@master bin]# ./start-hbase.sh
[root@slave01 ~]# cd /usr/hbase-1.0.3/bin/
[root@slave01 bin]# ./hbase-daemon.sh start regionserver
[root@slave02 ~]# cd /usr/hbase-1.0.3/bin/
[root@slave02 bin]# ./hbase-daemon.sh start regionserver
十二 测试
12.1 浏览器检测
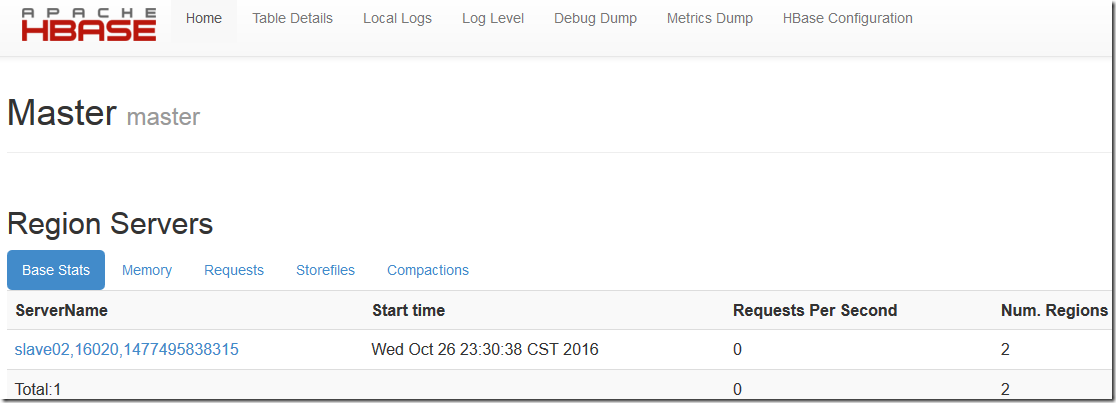
12.2 java检测
[root@master ~]# /usr/jdk1.8.0_111/bin/jps
21346 NameNode
23301 Jps
21703 ResourceManager
21544 SecondaryNameNode
22361 QuorumPeerMain
23087 HMaster
[root@slave01 ~]# jps
17377 HRegionServer
17457 Jps
16038 NodeManager
15928 DataNode
16488 QuorumPeerMain
15533 SecondaryNameNode
[root@slave02 ~]# jps
16400 QuorumPeerMain
15507 SecondaryNameNode
16811 HRegionServer
17164 Jps
16013 NodeManager
15903 DataNode
001.hadoop及hbase部署的更多相关文章
- Hadoop+Spark+Hbase部署整合篇
之前的几篇博客中记录的Hadoop.Spark和Hbase部署过程虽然看起来是没多大问题,但是之后在上面跑任务的时候出现了各种各样的配置问题.庆幸有将问题记录下来,可以整理出这篇部署整合篇. 确保集群 ...
- Hadoop及Hbase部署
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html作者:木二 目录 一 环境准备 1.1 相关环境 1.2 网络环境 二 基础环境配置 2.1 配置相 ...
- Zookeeper + Hadoop + Hbase部署备忘
网上类似的文章很多,本文只是记录下来备忘.本文分四大步骤: 准备工作.安装zookeeper.安装hadoop.安装hbase,下面分别详细介绍: 一 准备工作 1. 下载 zookeeper.had ...
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- 大数据【七】HBase部署
接着前面的Zookeeper部署之后,现在可以学习HBase了. HBase是基于Hadoop的开源分布式数据库,它以Google的BigTable为原型,设计并实现了具有高可靠性.高性能.列存储.可 ...
- Hadoop生态圈-Sqoop部署以及基本使用方法
Hadoop生态圈-Sqoop部署以及基本使用方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与 ...
- HBase部署与使用
HBase部署与使用 概述 HBase的角色 HMaster 功能: 监控RegionServer 处理RegionServer故障转移 处理元数据的变更 处理region的分配或移除 在空闲时间进行 ...
- 教你成为全栈工程师(Full Stack Developer) 四十五-一文读懂hadoop、hbase、hive、spark分布式系统架构
转载自http://www.shareditor.com/blogshow?blogId=96 机器学习.数据挖掘等各种大数据处理都离不开各种开源分布式系统,hadoop用于分布式存储和map-red ...
- 【Hadoop】HBase组件配置
目录 HBase实验步骤: 1.配置时间同步(所有节点) 2.部署HBase(master节点) 3.配置HBase(master节点) 4.拷贝文件到slave节点 5.修改权限,切换用户(所有节点 ...
随机推荐
- Ansible Role
Ansible Role 专题总揽 https://www.jianshu.com/p/1be92c3f65ec lework 关注 2017.03.02 12:57* 字数 629 阅读 1439评 ...
- java基础基础总结----- Math(随机数)
前言:math类中感觉最好玩的应该就是随机数 代码: package com.day13.math; import java.util.Random; /** * 类说明 :Math * @autho ...
- Spark记录-Scala字符串
Scala字符串 在Scala中的字符串和Java中的一样,字符串是一个不可变的对象,也就是一个不能修改的对象.可以修改的对象,如数组,称为可变对象.字符串是非常有用的对象,在本节的最后部分,我们将介 ...
- CSS-3 Transition 的使用
css的transition允许css的属性值在一定的时间区间内平滑地过渡.这种效果可以在鼠标单击.获得焦点.被点击或对元素任何改变中触发,并圆滑地以动画效果改变CSS的属性值." tran ...
- 20145234黄斐《Java程序设计》第八周
教材学习内容总结 第十四章-NIO与NIO2 NIO与IO的区别 NIO Channel继承框架 想要取得Channel的操作对象,可以使用Channels类,它定义了静态方法newChannel() ...
- ASP.NET程序发布
详细流程请参考文章:https://www.cnblogs.com/wangjiming/p/6286045.html 主要补充个人操作过程中遇到的问题: 1)网站发布完成后,站点下没有aspnet_ ...
- linux 图形配置网络
命令:setup 打开网络等系统信息的图形配置 yyp复制 vi /etc/sysconfig/network-scripts/ifcfg-eth0 配置网络参数 重启网卡:/etc/init.d/n ...
- Workflow规则收藏
豆瓣电影 查看电影评分等详细信息 查看图片EXIF 图铃机器人 快递查询 翻译 手机号码归属地 音乐视频下载 获取附近的免费WIFI
- flask基础之LocalProxy代理对象(八)
前言 flask框架自带的代理对象有四个,分别是request,session,g和current_app,各自的含义我们在前面已经详细分析过.使用代理而不是显式的对象的主要目的在于这四个对象使用太过 ...
- QTP图片验证/图片比较/二进制流对比法
图片验证主要是文件对比,其中我们可以利用二进制的方法读取图片信息,然后进行对比,达到对比的效果,本例子利用fso对象的文件流的方法实现,代码如下: Public Function CompareFil ...