Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署
前言
单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个namenode节点,一个为active状态,一个为standby状态。如下图: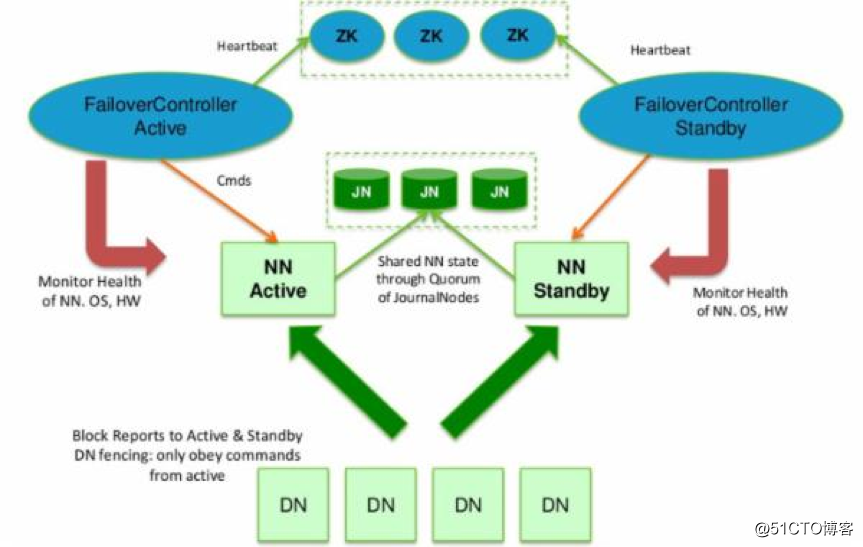
说明如下:
HDFS的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来同步FsEdits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的FsEdits信息,并更新自己内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的FsEdits,然后切换成Active状态。
使用HA的时候,不能启动
SecondaryNameNode,会出错。
集群的规划
ip 基本的软件 运行的进程
uplooking01 jdk、zk、hadoop NameNode、zkfc、zk、journalNode
uplooking02 jdk、zk、hadoop NameNode、zkfc、zk、journalNode、datanode、ResourceManager、NodeManager
uplooking03 jdk、zk、hadoop zk、journalNode、datanode、ResourceManager、NodeManagerzookeeper集群搭建
1、解压:
[uplooking@uplooking01 ~]$ tar -zxvf soft/zookeeper-3.4.6.tar.gz -C app/
2、重命名
[uplooking@uplooking01 ~]$ mv app/zookeeper-3.4.6 app/zookeeper
3、配置文件重命名
[uplooking@uplooking01 zookeeper]$ cp conf/zoo_sample.cfg conf/zoo.cfg
4、修改配置文件$ZOOKEEPER_HOME/conf/zoo.cfg
dataDir=/home/uplooking/app/zookeeper/data
dataLogDir=/home/uplooking/logs/zookeeper
server.101=uplooking01:2888:3888
server.102=uplooking02:2888:3888
server.103=uplooking03:2888:3888
启动server表示当前节点就是zookeeper集群中的一个server节点
server后面的.数字(不能重复)是当前server节点在该zk集群中的唯一标识
=后面则是对当前server的说明,用":"分隔开,
第一段是当前server所在机器的主机名
第二段和第三段以及2818端口
2181--->zookeeper服务器开放给client连接的端口
2888--->zookeeper服务器之间进行通信的端口
3888--->zookeeper和外部进程进行通信的端口
5、在dataDir=/home/uplooking/app/zookeeper/data下面创建一个文件myid
uplooking01机器对应的server.后面的101
uplooking02机器对应的server.后面的102
uplooking03机器对应的server.后面的103
6、需要将在uplooking01上面的zookeeper拷贝之uplooking02和uplooking03,这里使用scp远程拷贝
scp -r app/zookeeper uplooking@uplooking02:/home/uplooking/app
scp -r app/zookeeper uplooking@uplooking03:/home/uplooking/app
在拷贝的过程中需要设置ssh免密码登录
在uplooking02和uplooking03上面生成ssh密钥
ssh-keygen -t rsa
将密钥拷贝授权文件中
uplooking02:
ssh-keygen -t rsa
ssh-copy-id -i uplooking@uplooking02
uplooking03:
ssh-keygen -t rsa
ssh-copy-id -i uplooking@uplooking03
uplooking01:
ssh-copy-id -i uplooking@uplooking03
7、修改myid文件
[uplooking@uplooking02 ~]$ echo 102 > app/zookeeper/data/myid
[uplooking@uplooking03 ~]$ echo 103 > app/zookeeper/data/myid
8、同步环境变量文件
[uplooking@uplooking01 ~]$ scp .bash_profile uplooking@uplooking02:/home/uplooking/
[uplooking@uplooking01 ~]$ scp .bash_profile uplooking@uplooking03:/home/uplooking/
9、启动
在1、2、3分别执行zkServer.sh startHadoop分布式HA的部署
1、解压
[uplooking@uplooking01 ~]$ tar -zvxf soft/hadoop-2.6.4.tar.gz -C app/
2、重命名
[uplooking@uplooking01 ~]$ mv app/hadoop-2.6.4/ app/hadoop
3、修改配置文件
hadoop-env.sh、yarn-env.sh、hdfs-site.xml、core-site.xml、mapred-site.xml、yarn-site.xml、slaves
1°、hadoop-env.sh
export JAVA_HOME=/opt/jdk
2°、yarn-env.sh
export JAVA_HOME=/opt/jdk
3°、slaves
uplooking02
uplooking03
4°、hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>uplooking01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>uplooking01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>uplooking02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>uplooking02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://uplooking01:8485;uplooking02:8485;uplooking03:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/uplooking/data/hadoop/journal</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/uplooking/data/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/uplooking/data/hadoop/data</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/uplooking/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
5°、core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/uplooking/data/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>uplooking01:2181,uplooking02:2181,uplooking03:2181</value>
</property>
</configuration>
6°、mapred-site.xml
<configuration>
<!-- mr依赖的框架名称 yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mr转化历史任务的rpc通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>uplooking02:10020</value>
</property>
<!-- mr转化历史任务的http通信地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>uplooking02:19888</value>
</property>
<!-- 会在hdfs的根目录下面创建一个history的文件夹,存放历史任务的相关运行情况-->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/history</value>
</property>
<!-- map和reduce的日志级别-->
<property>
<name>mapreduce.map.log.level</name>
<value>INFO</value>
</property>
<property>
<name>mapreduce.reduce.log.level</name>
<value>INFO</value>
</property>
</configuration>
7°、yarn-site.xml
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>uplooking02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>uplooking03</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>uplooking01:2181,uplooking02:2181,uplooking03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4、准备hadoop所需要的几个目录
[uplooking@uplooking01 hadoop]$ mkdir -p /home/uplooking/data/hadoop/journal
[uplooking@uplooking01 hadoop]$ mkdir -p /home/uplooking/data/hadoop/name
[uplooking@uplooking01 hadoop]$ mkdir -p /home/uplooking/data/hadoop/data
[uplooking@uplooking01 hadoop]$ mkdir -p /home/uplooking/data/hadoop/tmp
5、同步到uplooking02和uplooking03
[uplooking@uplooking01 ~]$ scp -r data/hadoop uplooking@uplooking02:/home/uplooking/data/
[uplooking@uplooking01 ~]$ scp -r data/hadoop uplooking@uplooking03:/home/uplooking/data/ [uplooking@uplooking01 ~]$ scp -r app/hadoop uplooking@uplooking02:/home/uplooking/app/
[uplooking@uplooking01 ~]$ scp -r app/hadoop uplooking@uplooking03:/home/uplooking/app/
6、格式化&启动
1°、启动zk
2°、启动jouralnode
hadoop-deamon.sh start journalnode
3°、在uplooking01或者uplooking02中的一台机器上面格式化hdfs
hdfs namenode -format
18/03/02 11:16:20 INFO common.Storage: Storage directory /home/uplooking/data/hadoop/name has been successfully formatted.
说明格式化成功
将格式化后的namenode的元数据信息拷贝到另外一台namenode之上就可以了
将uplooking01上面产生的namenode的元数据信息,拷贝到uplooking02上面,
scp -r /home/uplooking/data/hadoop/name uplooking@uplooking02:/home/uplooking/data/hadoop/
4°、格式化zkfc
hdfs zkfc -formatZK
实际上是在zookeeper中创建一个目录节点/hadoop-ha/ns1
5°、启动hdfs
在uplooking01机器上面或者uplooking02上面启动、start-dfs.sh
6、启动yarn
在yarn配置的机器上面启动start-yarn.sh
在uplooking02上面启动start-yarn.sh
在uplooking03上面启动脚本
yarn-daemon.sh start resourcemanager(在3上没有resourcemanager进程,需要手动启动一下)
(hadoop的bug,在u2上启动yarn后,2上是有resourcemanager进程的,但是3上是没有的,所以3上面是需要手动启动的)
7°、要启动hdfs中某一个节点,使用脚本hadoop-daemon.sh start 节点进程名 (
Note:在保证已经格式化hdfs和zkfc后,可以直接使用start-dfs.sh start来启动,这时会依次启动:namenode datanode journalnode zkfc
Starting namenodes on [uplooking01 uplooking02]
uplooking01: starting namenode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-namenode-uplooking01.out
uplooking02: starting namenode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-namenode-uplooking02.out
uplooking03: starting datanode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-datanode-uplooking03.out
uplooking02: starting datanode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-datanode-uplooking02.out
Starting journal nodes [uplooking01 uplooking02 uplooking03]
uplooking03: starting journalnode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-journalnode-uplooking03.out
uplooking02: starting journalnode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-journalnode-uplooking02.out
uplooking01: starting journalnode, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-journalnode-uplooking01.out
18/03/04 01:00:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [uplooking01 uplooking02]
uplooking02: starting zkfc, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-zkfc-uplooking02.out
uplooking01: starting zkfc, logging to /home/uplooking/app/hadoop/logs/hadoop-uplooking-zkfc-uplooking01.out
) 7、访问和验证
1°、访问
web
hdfs
http://uplooking01:50070
http://uplooking02:50070
其中一个是active,一个是standby
yarn
http://uplooking02:8088
http://uplooking03:8088
在浏览的时候standby会重定向跳转之active对应的页面
shell
我们是无法操作standby对应的hdfs的,只能操作active的namenode
Operation category READ is not supported in state standby
2、ha的验证
NameNode HA
访问:
uplooking01:50070
uplooking02:50070
其中一个active的状态,一个是StandBy的状态
当访问standby的namenode时候:
Operation category READ is not supported in state standby 主备切换验证:
在uplooking01上kill -9 namenode的进程
这时访问uplooking02:50070发现变成了active的
然后在uplooking01上重新启动namenode,发现启动后状态变成standby的 Yarn HA
web访问:默认端口是8088
uplooking02:8088
uplooking03:8088
This is standby RM. Redirecting to the current active RM: http://uplooking02:8088/ 主备切换验证:
在uplooking02上kill -9 resourcemanager的进程
这时可以访问uplooking03:8088
然后在uplooking02上重新启动resourcemanager,再访问时就是跳转到uplooking03:8088
主备切换结论:
原来的主再恢复时,为了系统的稳定性,不会再进行主备的切换。 3、简单操作
cd /home/uplooking/app/hadoop/share/hadoop/mapreduce
[uplooking@uplooking01 mapreduce]$ yarn jar hadoop-mapreduce-examples-2.6.4.jar wordcount /hello /output/mr/wc
Hadoop分布式HA的安装部署的更多相关文章
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
- Hadoop的HA(ZooKeeper)安装与部署
非HA的安装步骤 https://www.cnblogs.com/live41/p/15467263.html 一.部署设定 1.服务器 c1 192.168.100.105 zk.name ...
- 高可用Hadoop平台-Ganglia安装部署
1.概述 最近,有朋友私密我,Hadoop有什么好的监控工具,其实,Hadoop的监控工具还是蛮多的.今天给大家分享一个老牌监控工具Ganglia,这个在企业用的也算是比较多的,Hadoop对它的兼容 ...
- hadoop 2.x HA(QJM)安装部署规划
一.主机服务规划: db01 db02 ...
- hadoop3.1.1 HA高可用分布式集群安装部署
1.环境介绍 涉及到软件下载地址:https://pan.baidu.com/s/1hpcXUSJe85EsU9ara48MsQ 服务器:CentOS 6.8 其中:2 台 namenode.3 台 ...
随机推荐
- django-response对象
HttpResponse 对象则需要 web 开发者自己创建,一般在视图函数中 return 回去.下面我们就来看看 HttpResponse 对象的各种细节 首先,这个对象由 HttpRespons ...
- Solr游标查询提高翻页效率
长期以来,我们一直有一个深分页问题.如果直接跳到很靠后的页数,查询速度会比较慢.这是因为Solr的需要为查询从开始遍历所有数据.直到Solr的4.7这个问题一直没有一个很好的解决方案.与最近发布的So ...
- vue获取dom
//使用ref属性来获取当前的div的dom属性 <div class="list" ref="wrapper"></div> //在j ...
- 关于python无法显示中文的问题:SyntaxError: Non-ASCII character '\xe4' in file test.py on line 3, but no encoding declared。
[已解决]关于python无法显示中文的问题:SyntaxError: Non-ASCII character '\xe4' in file test.py on line 3, but no enc ...
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
- Python之网络编程(Socket)
1.网络通信原理与互联网协议 详见:https://www.cnblogs.com/JackLi07/p/9218039.html 2.socket层 以上是tcp/ip五层协议的结构图,我们没有看到 ...
- AJAX发送 PUT和DELETE请求参数传递注意点,了解一下
ajax发送put 和 delete 请求时,需要传递参数,如果参数在url地址栏上,则可以正常使用, 如果在 data:中需要传递参数,(浏览器会使用表单提交的方式进行提交) 则需要注意此时应作如下 ...
- centos7 更新yum报错initscripts conflicts with centos-release-7-3.1611.el7.centos.x86_64
1.centos7的系统的yum 更新系统报错: --> 解决依赖关系完成错误:initscripts conflicts with centos-release-7-3.1611.el7.ce ...
- 42. oracle通过两张表的一个字段对应,update其中一张表的某个字段
update A a set a.A2 = (select b.B2 from B b where b.B1=a.A1) where exists (select 1 from B where B.B ...
- 设计模式、j2ee 部 分、EBJ 部 分
八. 软 件 工 程 与 设 计 模 式 1 .UML 方 面 标准建模语言 UML.用例图,静态图(包括类图.对象图和包图),行为图,交互图(顺序图,合作 图),实现图. 2 .j2ee 常 用 的 ...