deeplearning.ai学习RNN
一、RNN基本结构

普通神经网络不能处理时间序列的信息,只能割裂的单个处理,同时普通神经网络如果用来处理文本信息的话,参数数目将是非常庞大,因为如果采用one-hot表示词的话,维度非常大。
RNN可以解决这两个问题:
1)RNN属于循环神经网络,当从左到右读取文本信息的时候,上一时刻的状态输出可以传递到下一时刻,例如上图的a表示状态,a(1)向下传递,这样就考虑了前面的信息,如果是双向RNN的话,上下文都考虑进去了。
2)RNN参数是共享的。为方便理解,上述图示是展开的RNN结构,其实RNN只有一个循环体,一组共享参数。
上述图是一个最基本的RNN结构,a<T>代表不同时刻的状态,a0是一个初始化的零时刻的状态,可以设置为零向量;x<T>代表不同时刻的输入,y<T>代表不同时刻的输出,计算公式如下:
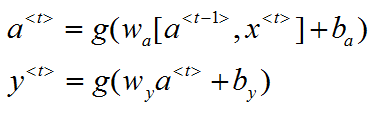
其中g为激活函数。
二、反向传播
1)计算损失
以命名实体识别作为例子,如果是地名就为1,不是地名就为0。输入是一句文本信息X=[he come from NewYork],输出一组Y=[0,0,0,1],X与Y的长度一致。模型预测的输出就是该输入x是地名的概率值,比如0.2,所以其实就是一个二分类问题,损失函数可以采用标准的逻辑回归损失或者说交叉熵损失。
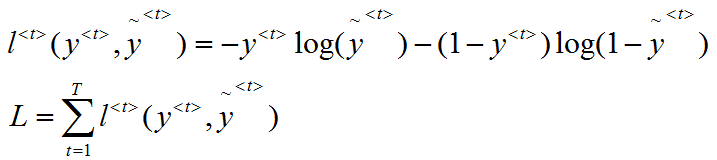
第一个是元素级别的损失,也就是单个时刻的损失,第二个是整体序列的损失。
2)反向传播更新参数
因为RNN是一个循环体,其展开形式就是上述图所示,因为后面的状态a与输出y都依赖于前面的计算得到的,所以在进行反向传播的时候,跟普通神经网络一样,需要一层层向后利用梯度下降法计算梯度,并更新参数。与普通神经网络更新参数不同的一点就是,RNN因为是共享参数,所以在进行反向传播的时候,每传播一层更新的都是同一组参数。
三、其它形式的RNN结构
之前讲的例子是属于many-to-many的形式,且输入X与输出Y的长度相等,这种形式适合解决序列标注问题。还有其它形式的RNN结构
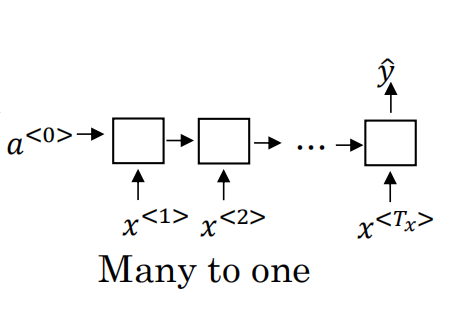
1)many-to-one (情感分析问题)
情感分析问题的输入是一个连续序列,例如对电影的描述“There is nothing to like in this movie”,而输出y=1/0,表示正面与负面;或者y=1,2,3,4,5表示对电影的评分等级,这种结构设计如下形式:
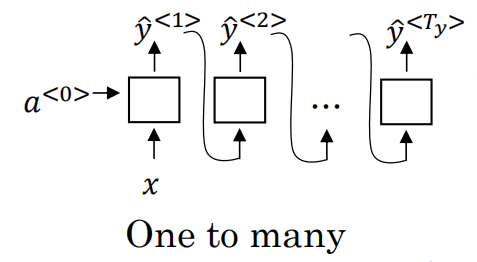
2)one-to-many(音乐生成)
输入x为一个整数,表示你想要的音乐类型或者是你想要的音乐的第一个音符;输出Y是一段生成的音乐。这种结构输入是一个x,输出是多个y。
3)many-to-many(机器翻译)
文章开头讲的结构也属于many-to-many形式,但是那种形式X与Y的长度是一致的,适合解决序列标注的问题。这次的many-to-many是输入X与Y长度不一致的情况,例如机器翻译。其结构如下:
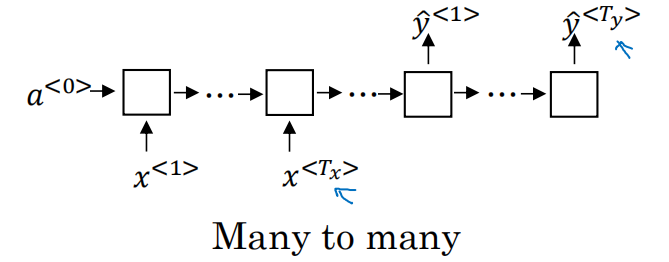
前面一部分叫做encoder,分别输入x和状态a;后面一部分叫做decoder,Y直到输出为EOS结束。
四、用RNN训练一个语言模型
所谓语言模型,就是输入一句话,能得出这句话出现的概率。例如下面的这句话:

在训练的时候会从左到右一个个读取:

每一个输出y<t>,会通过softmax函数得出长度为字典长度|v|的向量,表示预测为每一个词的概率。后面的输入为前面的一个词,例如x<2>的输入就是cat,表示在前一个词为cat,后一个词输出为average的概率是多少,因此每一个词的输出都考虑了前面词的信息。
输出y<t>已经经过softmax层了,所以采用交叉熵计算损失即可,如下:

第一个为单个元素损失,第二个为整个序列的损失。
整个模型训练完毕后,如果要计算p(y<1>,y<2>,y<3>)的概率,只需要把该序列像训练的时候带入模型,得出分别预测出来y<1>,y<2>,y<3>的概率,第一个输入x=0,得出y<1>的概率,第二个输入y<1>得出y<2>的概率,第三个输入y<2>得出y<3>的概率,最后连乘即可:

五、采样新序列
前面第四部分我们已经训练生成了一个语言模型,这样我们就可以采样新序列,或者说是利用语言模型来生成新的语句序列,其结构形式如下:
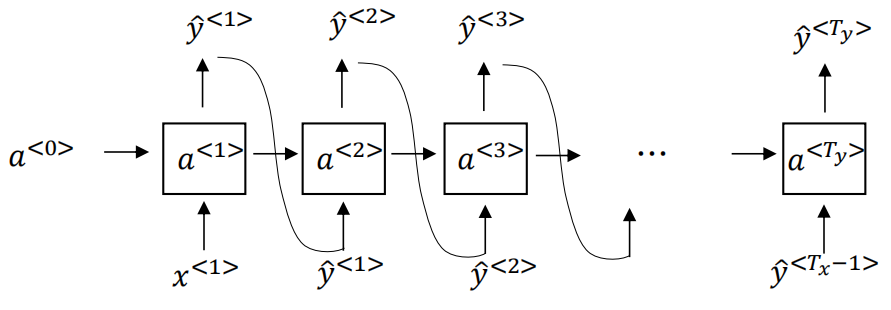
a<0>和x<1>输入都可以设置为零向量,每一层的输出都是一个softmax在字典|v|每个词的概率输出,可以利用np.random.choice随机进行采样选取一个词,作为第一个词。然后后面节点的输入就是前面节点的输出,后面每一层的输出都进行随机采样,直到到达设定的时间步或者输出为EOS为止,这样就可以生成新序列了。下面就是利用莎士比亚文章训练的语言模型生成的采样序列:

六、RNN的问题
梯度消失:
在反向传播的过程中,由于梯度消失的问题,RNN的输出很难受到序列靠前的输入的影响,因为不管输出是什么,无论输出是对还是错,这个区域都很难反向传播到序列的前面部分,因此网络也很难调整序列前面的计算,所以RNN就不擅长处理长期依赖的问题。
梯度爆炸:
随着网络深度的加深,参数呈指数级别增长,甚至出现数值溢出为Nan的情况,这就是梯度爆炸。解决办法就是采用梯度修剪,观察梯度向量,如果大于某一个阈值时候,就缩放梯度向量,保证不会太大,这种方式处理梯度爆炸鲁棒性比较好。
综合来说,梯度消失更难处理一些。
deeplearning.ai链接:https://mooc.study.163.com/learn/2001280005?tid=2001391038#/learn/content
deeplearning.ai学习RNN的更多相关文章
- DeepLearning.ai学习笔记汇总
第一章 神经网络与深度学习(Neural Network & Deeplearning) DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络 DeepLe ...
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week2机器学习策略(2)
一.进行误差分析 很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差.想法固然好,但是有点headlong~ 这节视频中吴大大介绍了一个比较科学的方法,具体的看下面的例子 还是以猫 ...
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络
介绍 DeepLearning课程总共五大章节,该系列笔记将按照课程安排进行记录. 另外第一章的前两周的课程在之前的Andrew Ng机器学习课程笔记(博客园)&Andrew Ng机器学习课程 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week1 循环序列模型
一.为什么选择序列模型 序列模型可以用于很多领域,如语音识别,撰写文章等等.总之很多优点... 二.数学符号 为了后面方便说明,先将会用到的数学符号进行介绍. 以下图为例,假如我们需要定位一句话中人名 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 序列模型和注意力机制
一.基础模型 假设要翻译下面这句话: "简将要在9月访问中国" 正确的翻译结果应该是: "Jane is visiting China in September" ...
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--Week2优化算法
1. Mini-batch梯度下降法 介绍 假设我们的数据量非常多,达到了500万以上,那么此时如果按照传统的梯度下降算法,那么训练模型所花费的时间将非常巨大,所以我们对数据做如下处理: 如图所示,我 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week1 卷积神经网络基础知识介绍
一.计算机视觉 如图示,之前课程中介绍的都是64* 64 3的图像,而一旦图像质量增加,例如变成1000 1000 * 3的时候那么此时的神经网络的计算量会巨大,显然这不现实.所以需要引入其他的方法来 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week2深度卷积神经网络 实例探究
一.为什么要进行实例探究? 通过他人的实例可以更好的理解如何构建卷积神经网络,本周课程主要会介绍如下网络 LeNet-5 AlexNet VGG ResNet (有152层) Inception 二. ...
随机推荐
- RYU 灭龙战 second day(内容大部分引自网络)
RYU 灭龙战 second day(内容大部分引自网络) 写好的markdown重启忘了保存...再写一次RLG 巨龙的稀有装备-RYU代码结构 RYU控制器代码结构的总结 RYU入门教程 RYU基 ...
- 团队作业(五)——旅游行业的手机App
首先是作业要求: 在PM 带领下, 每个团队深入分析下面行业的App, 找到行业的Top 5 (从下面的三个备选中,任选一个行业即可) 英语学习/词典App 笔记App 旅游行业的手机App 我们选择 ...
- Jmeter put 方法总结
1.百度到很多关于jmeter put 方法的使用 ,但觉得都完全 下面我大致总结下 : >1.放入 url 中 如:www.*****.com?a=1&b=2 ; >2.放入到p ...
- linux 解压文件
原文:android之常用解压缩指令 .tar解包:tar xvf FileName.tar打包:tar cvf FileName.tar DirName ---------------------- ...
- 深入理解Java反射+动态代理
答: 反射机制的定义: 是在运行状态中,对于任意的一个类,都能够知道这个类的所有属性和方法,对任意一个对象都能够通过反射机制调用一个类的任意方法,这种动态获取类信息及动态调用类对象方法的功能称为j ...
- .net 生成html文件后压缩成zip文件并下载
这里只做一个简单的实例 public ActionResult Index() { string path = Server.MapPath("/test/");//文件输出目录 ...
- Tether USDT 节点钱包的安装与使用-omni layer
1 什么是Omni Layer Omni Layer是一种通信协议,它使用比特币区块链实现智能合约,用户货币和分散式点对点交换等功能. Omni Core是基于比特币核心代码库的快速,便携式Omni层 ...
- (转)CS0016: 未能写入输出文件
转自:http://www.pageadmin.net/article/20130305/537.html 编译错误 说明: 在编译向该请求提供服务所需资源的过程中出现错误.请检查下列特定错误详细信息 ...
- 【BZOJ1090】[SCOI2003]字符串折叠(动态规划)
[BZOJ1090][SCOI2003]字符串折叠(动态规划) 题面 BZOJ 洛谷 题解 区间\(dp\).设\(f[i][j]\)表示压缩\([i,j]\)区间的最小长度.显然可以枚举端点转移.再 ...
- USACO Section 2.1 Sorting a Three-Valued Sequence 解题报告
题目 题目描述 给N个整数,每个整数只能是1,2,或3.现在需要对这个整数序列进行从小到大排序,问最少需要进行几次交换.N(1 <= N <= 1000) 样例输入 9 2 2 1 3 3 ...