scrapy (四)基本配置
scrapy使用细节配置
一、建立项目
1、scrapy startproject 项目名字
2、进入项目:
scrapy genspider 名字 不带http的根网址
3、默认模板(或改变模板)
默认模板:class HuaSpider(scrapy.Spider):
改变模板:scapy genspider -t crwal 名字(hua2) 不带http的根网址:
(class Hua2Spider(CrawlSpider)
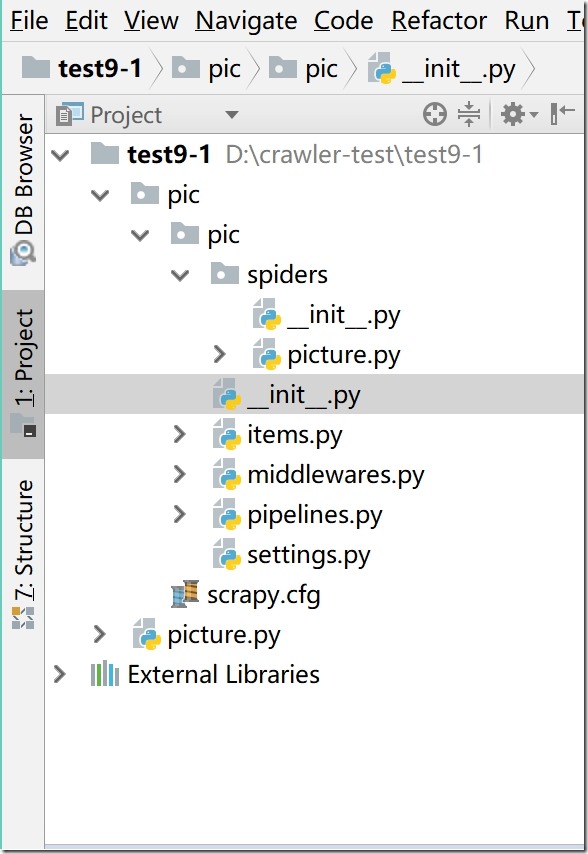
4、目录结构
二、setting基本设置
1、log日志输出的级别:
INFO、ERROR......
LOG_LEVEL = 'ERROR'
2、将log写到文件中(自动创建log.txt)
LOG_FILE = './log.txt'
3、robots
是否遵守各大网站的爬虫规则(robots),默认是True,为了得到我们想要的数据,设置ROBOTSTXT_OBEY为F alse: ROBOTSTXT_OBEY = False
查看各大网站的规则:根网址+/robots.txt,例如https://www.baidu.com/robots.txt
4、设置代理middlewares.py
下载中间件设置:
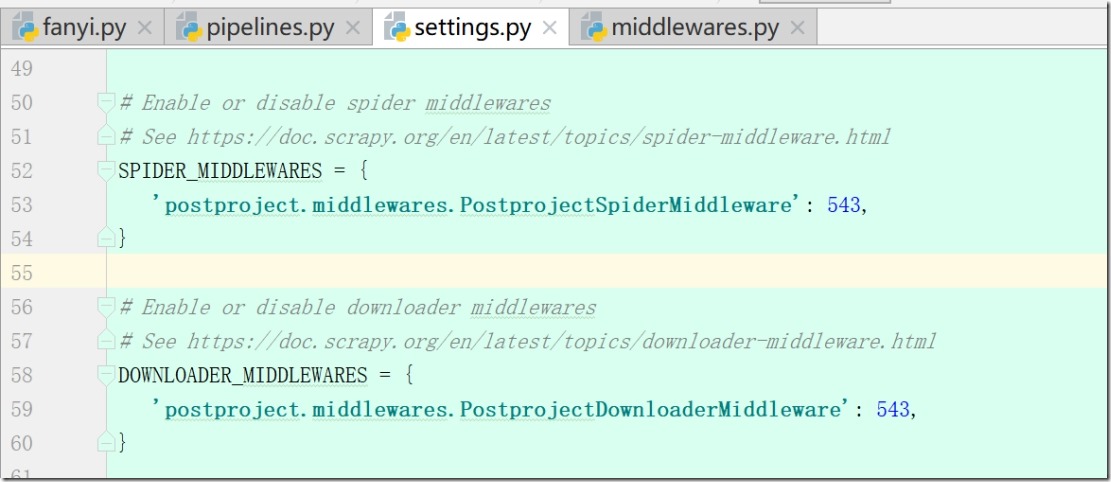
1) 在setting中打开以下配置
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.PostprojectDownloaderMiddleware': 543,
}
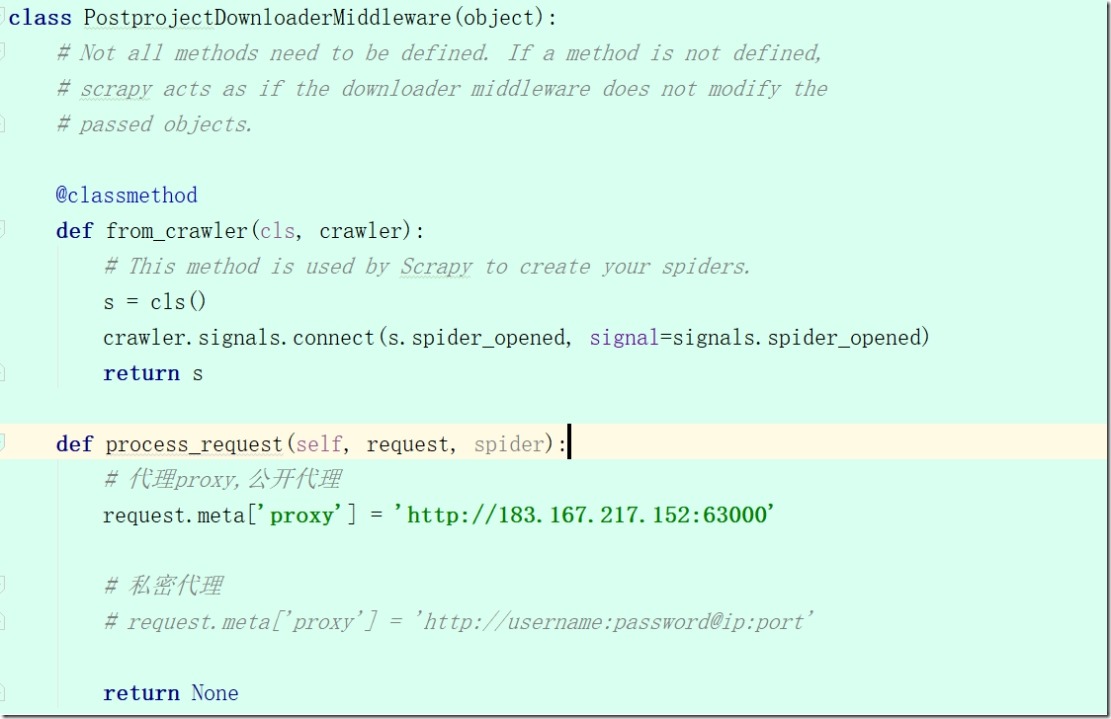
2)在middlewares.py中添加代理
在class PostprojectDownloaderMiddleware(object):
def process_request(self, request, spider):
公开代理格式:request.meta['proxy'] ='http://ip:port'
私密代理格式:request.meta['proxy'] = 'http://username:password@ip:port'
3)回到setting,解开下载中间件DOWNLOADER_MIDDLEWARES
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


scrapy (四)基本配置的更多相关文章
- 第三篇——第二部分——第四文 配置SQL Server镜像——非域环境
原文:第三篇--第二部分--第四文 配置SQL Server镜像--非域环境 本文为非域环境搭建镜像演示,对于域环境搭建,可参照上文:http://blog.csdn.net/dba_huangzj/ ...
- Nginx教程(四) Location配置与ReWrite语法
Nginx教程(四) Location配置与ReWrite语法 1 Location语法规则 1.1 Location规则 语法规则: location [=|~|~*|^~] /uri/ {- } ...
- centOS7 mini配置linux服务器(四) 配置jdk
这里简单写一下centos7Mini 安装jdk1.8的全过程. 一.下载jdk,linux版本. 地址:http://www.oracle.com/technetwork/java/javase/ ...
- CAS 5.1.x 的搭建和使用(四)—— 配置使用HTTP协议访问的服务端
CAS单点登录系列: CAS 5.1.x 的搭建和使用(一)—— 通过Overlay搭建服务端 CAS5.1.x 的搭建和使用(二)—— 通过Overlay搭建服务端-其它配置说明 CAS5.1.x ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 使用亚马逊云服务器EC2做深度学习(四)配置好的系统镜像
这是<使用亚马逊云服务器EC2做深度学习>系列的第四篇文章. (一)申请竞价实例 (二)配置Jupyter Notebook服务器 (三)配置TensorFlow (四)配置好的系统 ...
- scrapy框架中间件配置代理
scrapy框架中间件配置代理import random#代理池PROXY_http = [ '106.240.254.138:80', '211.24.102.168:80',]PROXY_http ...
- Scrapy笔记10- 动态配置爬虫
Scrapy笔记10- 动态配置爬虫 有很多时候我们需要从多个网站爬取所需要的数据,比如我们想爬取多个网站的新闻,将其存储到数据库同一个表中.我们是不是要对每个网站都得去定义一个Spider类呢? 其 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Cisco基础(四):配置标准ACL、配置扩展ACL、配置标准命名ACL、配置扩展命名ACL
一.配置标准ACL 目标: 络调通后,保证网络是通畅的.同时也很可能出现未经授权的非法访问.企业网络既要解决连连通的问题,还要解决网络安全的问题. 配置标准ACL实现拒绝PC1(IP地址为192.16 ...
随机推荐
- HDU2389(KB10-F 二分图最大匹配Hopcroft_Karp)
Rain on your Parade Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 655350/165535 K (Java/Ot ...
- deferred对象详解
什么是Deferred对象 defer,推迟:延期.含义就是”延迟”到未来某个点再执行. 在开发中,我们经常遇到某些耗时很长的javascript操作.其中,既有异步的操作(比如ajax读取服务器数 ...
- MySQL两种存储引擎: MyISAM和InnoDB
MySQL两种存储引擎: MyISAM和InnoDB 简单总结 MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Me ...
- 初识DOM(文档对象模型)
什么是DOM 什么叫做DOM呢? • DOM的全称是Document Object Model 文档对象模型,DOM定义了表示和修改文档所需的对象.这些对象的行为和属性以及这些对象之间的关系. • D ...
- canvas与svg特性和使用对比
什么是 Canvas? HTML5 的 canvas 元素使用 JavaScript 在网页上绘制图像. 画布是一个矩形区域,您可以控制其每一像素. canvas 拥有多种绘制路径.矩形.圆形.字符以 ...
- 学习ES6的全部特性
ES6 简介 ECMAScript 6 简称 ES6,是 JavaScript 语言的下一代标准,已经在2015年6月正式发布了.它的目标是使得 JavaScript 语言可以用来编写复杂的大型应用程 ...
- Dynamics 365Online Server-Side OAuth身份认证
在上篇演示了在html页面中通过调用online的OAuth身份验证后再通过web api取10条客户数据并展示,本篇继续讲述如何在server-side程序中调用online的OAuth认证再通过w ...
- cordova app强制横屏
非常简单,只需要在config.xml里加上这行: <preference name="Orientation" value="landscape" /& ...
- 前端构建工具Gulp使用总结
1.安装准备 1.1 Node.js安装 在安装Gulp之前首先的安装Node.js, 安装教程详见Node.js 安装配置 1.2 npm安装 在安装node的时候会自动安装npm模块管理器,详见n ...
- 2016年度最受欢迎的100个 Java 库
[编者按]本文作者为 Henn Idan,主要介绍基于 GitHub 中的数据分析,得出的2016年度最受欢迎的100个 Java 库.本文系国内 ITOM 管理平台 OneAPM 编译呈现. 谁拔得 ...