MySql 索引 查询 优化
官方文档:
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_rows type:
连接类型
system 表只有一行
const 表最多只有一行匹配,通用用于主键或者唯一索引比较时。如将主键置于where列表中,MySQL就能将该查询转换为一个常量
eq_ref 每次与之前的表合并行都只在该表读取一行,这是除了system,const之外最好的一种,特点是使用=,而且索引的所有部分都参与join且索引是主键或非空唯一键的索引
ref 如果每次只匹配少数行,那就是比较好的一种,使用=或<=>,可以是左覆盖索引或非主键或非唯一键
fulltext 全文搜索
ref_or_null 与ref类似,但包括NULL
index_merge 表示出现了索引合并优化(包括交集,并集以及交集之间的并集),但不包括跨表和全文索引。 这个比较复杂,目前的理解是合并单表的范围索引扫描(如果成本估算比普通的range要更优的话)
unique_subquery 在in子查询中,就是value in (select...)把形如“select unique_key_column”的子查询替换。PS:所以不一定in子句中使用子查询就是低效的!
index_subquery 同上,但把形如”select non_unique_key_column“的子查询替换
range 常数值的范围(索引范围扫描),对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
index a.当查询是索引覆盖的,即所有数据均可从索引树获取的时候(Extra中有UsingIndex);
b.以索引顺序从索引中查找数据行的全表扫描(无 UsingIndex);
c.如果Extra中Using Index与Using Where同时出现的话,则是利用索引查找键值的意思;
d.如单独出现,则是用读索引来代替读行,但不用于查找
all 遍历全表以找到匹配的行
null:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引结果值从好到坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
explain 执行计划分类。
摘自:
https://blog.csdn.net/q936889811/article/details/72576182
抛问题:
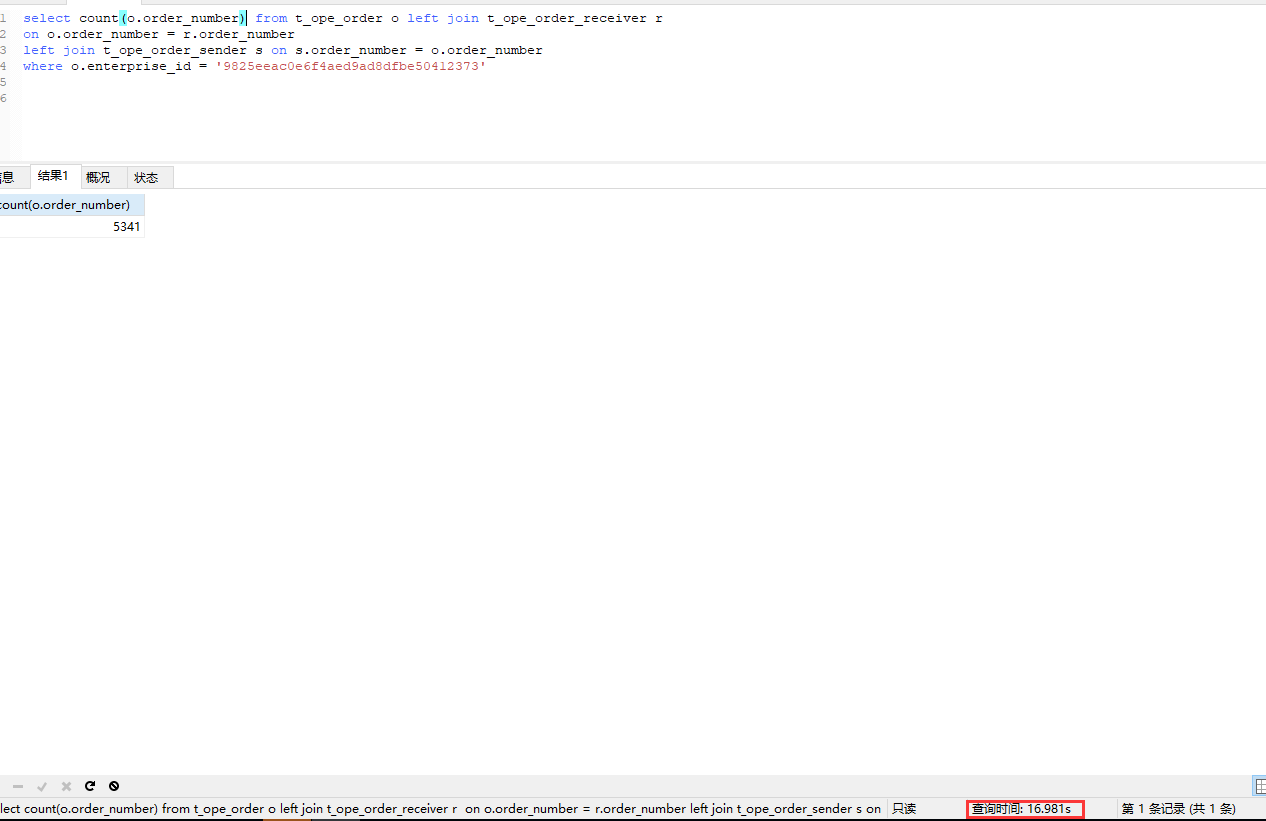
三个表每个表大概数据在5300左右。
做一个统计都要17S。有很大的优化空间。简单的办法就是加索引。具体走单索引还是组合索引。具体看业务情况这里走的是
单索引。
开测:先给三个表加索引。
添加索引:三个表类似 order_number用于on字段 e_id 用于where条件。
先试试JOIN写法
查询时间:0.022S 从17S优化到0.022S. 看一下执行计划:
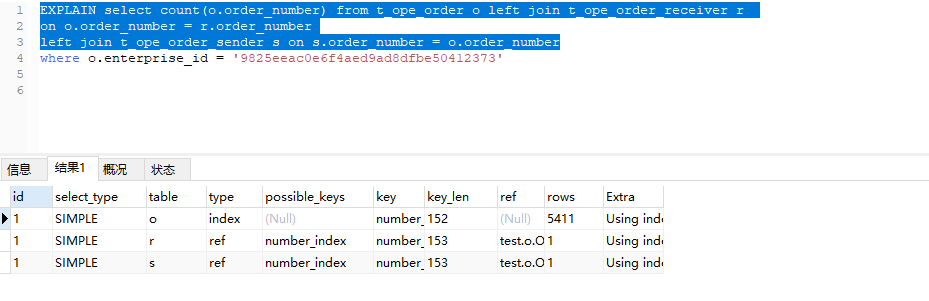
这条SQL我没有执行WHERE 条件 。也就是没有使用之前建的e_id_index索引。
主要看执行计划的 type 对比下
还有优化的空间。o表走的index 没有把索引的作用发挥到极致。现在加上where 看一下
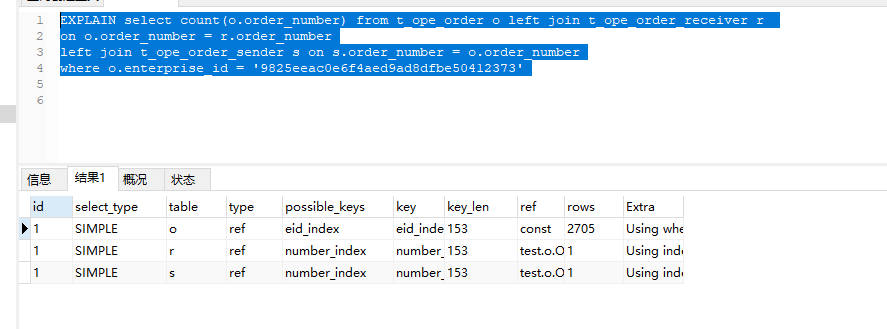
注意: o表的index从变成了ref: rows 从5411变成了2705
ref:如果每次只匹配少数行,那就是比较好的一种,使用=或<=>,可以是左覆盖索引或非主键或非唯一键
index a.当查询是索引覆盖的,即所有数据均可从索引树获取的时候(Extra中有UsingIndex);
b.以索引顺序从索引中查找数据行的全表扫描(无 UsingIndex);
c.如果Extra中Using Index与Using Where同时出现的话,则是利用索引查找键值的意思;
d.如单独出现,则是用读索引来代替读行,但不用于查找
从返回时间上来,区别是不大的。但从优化的角度上说后者更佳 再看看IN EXISTS的区别 ,很多人说IN不走索引 走的全表扫描
IN
EXISTS
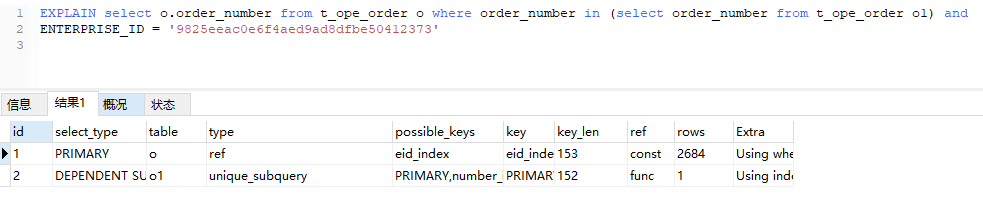
o表索引都引用的eid_index 没啥子大区别。
主要看o1索引 从un_index变成了eq_ref
对于un_index的说明看官方说明
不做翻译
相比之下,exists比in更能发挥索引的作用并不是in性能就差这里只是简单测试一下。
并不能完全保存exists就能优势于in.需要去更多的业务环境下发现,实践。 再看看LIKE走没走索引。LIKE很多人认为性能差,看计划上区别上大不大。这里只做简单分析不做深入。 全LIKE


左原则这两个写法都是用到了索引区别不是很大。这边用的单索引。没有用组合索引。 再看看select * 跟单个字段的区别
between ...and .... 等同于 <> != 非等值
再看看隐式转换的区别
隐式转换
正常写法加了单引。
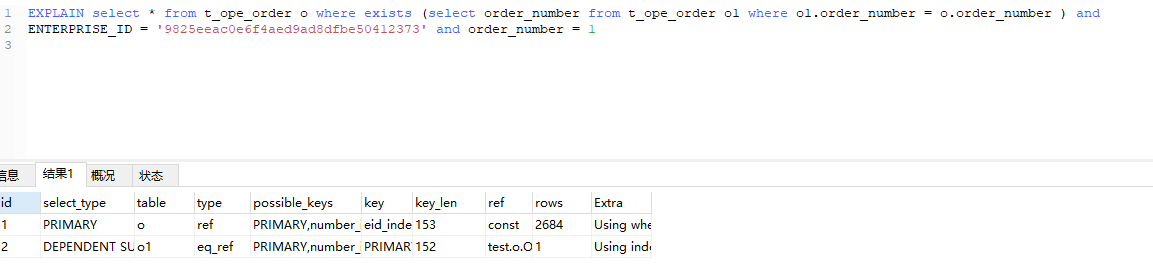
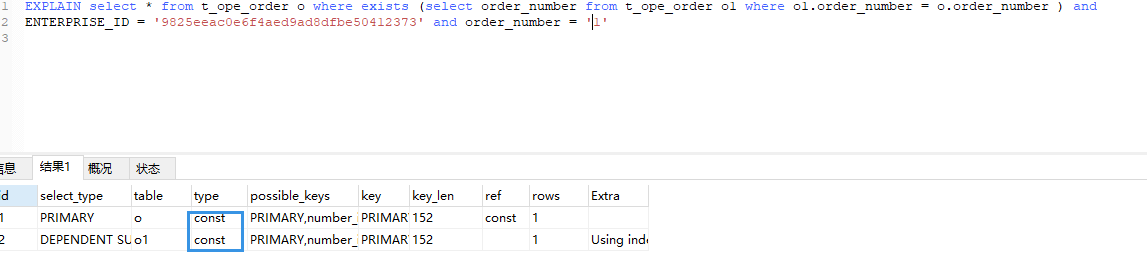
这里直接从ref eq_ref 升级成const const. 当数据量大的时候 ,返回时间是有很大区别的。
所以说平时写SQL一定要注意格式。千万别偷懒
效果是一样的。个人理解除了IO的消耗,没感觉哪里有区别。也不知道为什么很多人都说* 性能差。但又说不出来个所以然。
对于SQL优化简单总结一下:
1.避免字段NULL 用not null default 'xxx'填充。这里NULL值,我并没有去实践小懒一下。个人理解这可能跟索引的本身的数据结构有关系
2.能用等值操作就用等值操作。
3.业务条件允许的情况下能不用LIKE就不用 用第三方的 es solr 搜索引擎代替。
4.避免隐式转换
5.把ON字段关联加上索引
6.尽量用where强制使用索引
7.尽量用EXISTS 代替IN 。相比之下IN可读性高。EXISTS性能略胜IN。并不是说EXISTS绝对比IN好,需要在更多的业务环境实践。自行体会。
8.避免用* 减小IO消耗
9.字段设计 char varchar nvarch text / int bigint tinyint 能小则小。
10.表设计尽量使用物理外键可以用逻辑外键。
11.因为MYSQL没有 with as cte写法这里没有做演示 。在MSSQL ORACLE都是有的。性能相对来说比较好。走内存。
12.充分利用临时表,变量表,
13.UNION ALL UNAION 区别在于一个去重一个不去重。看业务场景。能不用就不用。把每个查询结果做重处理。避免UNION ALL
14.如果表关联过多,可以通过程序去拆分。不要一条SQL写的贼长。并不是SQL写的长就是叼。装逼有罪。
15.SQL很强大,多多练习 。
MySql 索引 查询 优化的更多相关文章
- 理解MySQL——索引与优化
转自:理解MySQL——索引与优化 写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存 ...
- mysql索引的优化
MySQL索引的优化 上面都在说使用索引的好处,但过多的使用索引将会造成滥用.因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT.UPDATE和DEL ...
- 【真·干货】MySQL 索引及优化实战
热烈推荐:超多IT资源,尽在798资源网 声明:本文为转载文章,为防止丢失所以做此备份. 本文来自公众号:GitChat精品课 原文地址:https://mp.weixin.qq.com/s/6V7h ...
- MySQL数据库索引类型、MySQL索引的优化及MySQL索引案例
关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车.对于没有索引的表,单表查询可能几十万数据就是瓶颈,而通常大型 ...
- MySQL索引及优化(1)存储引擎和底层数据结构
在昨天的面试中问到了MySQL索引怎么优化(查询很慢怎么办),回答的很不理想,所以今天来总结几篇关于MySQL索引的知识. 1.什么是索引? 首先我们一定要明确什么是索引?我自己的总结就是索引是一种数 ...
- mysql索引与优化
mysql 索引与优化 http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
- MySQL索引和优化查询
索引和优化查询 恰当的索引可以加快查询速度,可以分为四种类型:主键.唯一索引.全文索引.普通索引. 主键:唯一且没有null值. create table pk_test(f1 int not nul ...
- Mysql索引降维 优化查询 提高效率
在前一篇文章中,我们已经介绍了索引.索引的优化规则等等 原文链接:Siam博客 mysql索引优化 在其中我们有引申出组合索引,多个单字段索引冲突两个知识点. 本文章主要是与后者有关联. 在原文中,我 ...
- mysql 索引与优化like查询
索引与优化like查询 1. like %keyword 索引失效,使用全表扫描.但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描. 2. like key ...
随机推荐
- Kafka Stream
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature(当前:1.0.0-rc0,参见:https://github.com/apache/kafka/releas ...
- 【java】标示符
java的标示符由数字0-9,字母a-zA-Z,_$组成.(java是严格区分大小写的) 标示符的规则: 1.不能以数字开头 2.不能使用关键字 一般的命名规则: 包名:多个单词组成时,所有字母全部小 ...
- WebGL和ThreeJs学习5--ThreeJS基本功能控件
Threejs 2017年6月6日 15:06 Stats: new Stats();性能监视器,性能测试的方法,引入 Stats.js http://www.hewebgl.com ...
- esp8266尝鲜
请将当前用户添加到dialout组,否则会提示打开/dev/ttyUSB0权限不足 sudo usermod -a -G dialout `whoami` dmeg查看驱动安装信息 dmesg | g ...
- Java 中统计文件中出现单词的次数练习
统计英文article.txt文件中出现hello这个单词的次数 这个是article.txt文件内容 { hello The Royal Navy is trying hello to play h ...
- 使用socket.io client 开发时兼容IE低版本的办法
使用socket.io client 开发时兼容IE低版本的办法 socket.io提供了针对各个版本浏览器的‘socket’功能的封转:websocket,长连接,流,flash什么的.给你格式化下 ...
- 【linux】常用命令-端口
端口操作 手动更改配置文件开放端口 vim /etc/sysconfig/iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 81 ...
- 使用RetionalRose根据现有的java工程逆向生成类图
1.进入RetionalRose选择J2EE模板 2.在菜单栏选择tools->java/j2EE->reverse engineer 3.编辑路径Edit CLASSPATH选择要生成类 ...
- JAVA代码模板总结
静态工厂方法+服务提供者框架模板 构造器模板 事件通知模板 单元素枚举类型singleton模块 私有构造器不可实例化类模板
- 搭建DUBBO项目解决DUBBO.XML标签报错的问题(转载)
https://www.cnblogs.com/ajax-li/p/7856393.html 报错内容: Multiple annotations found at this line: - cvc- ...