Hbase数据读写流程
From:
https://blog.csdn.net/wuxintdrh/article/details/69056188
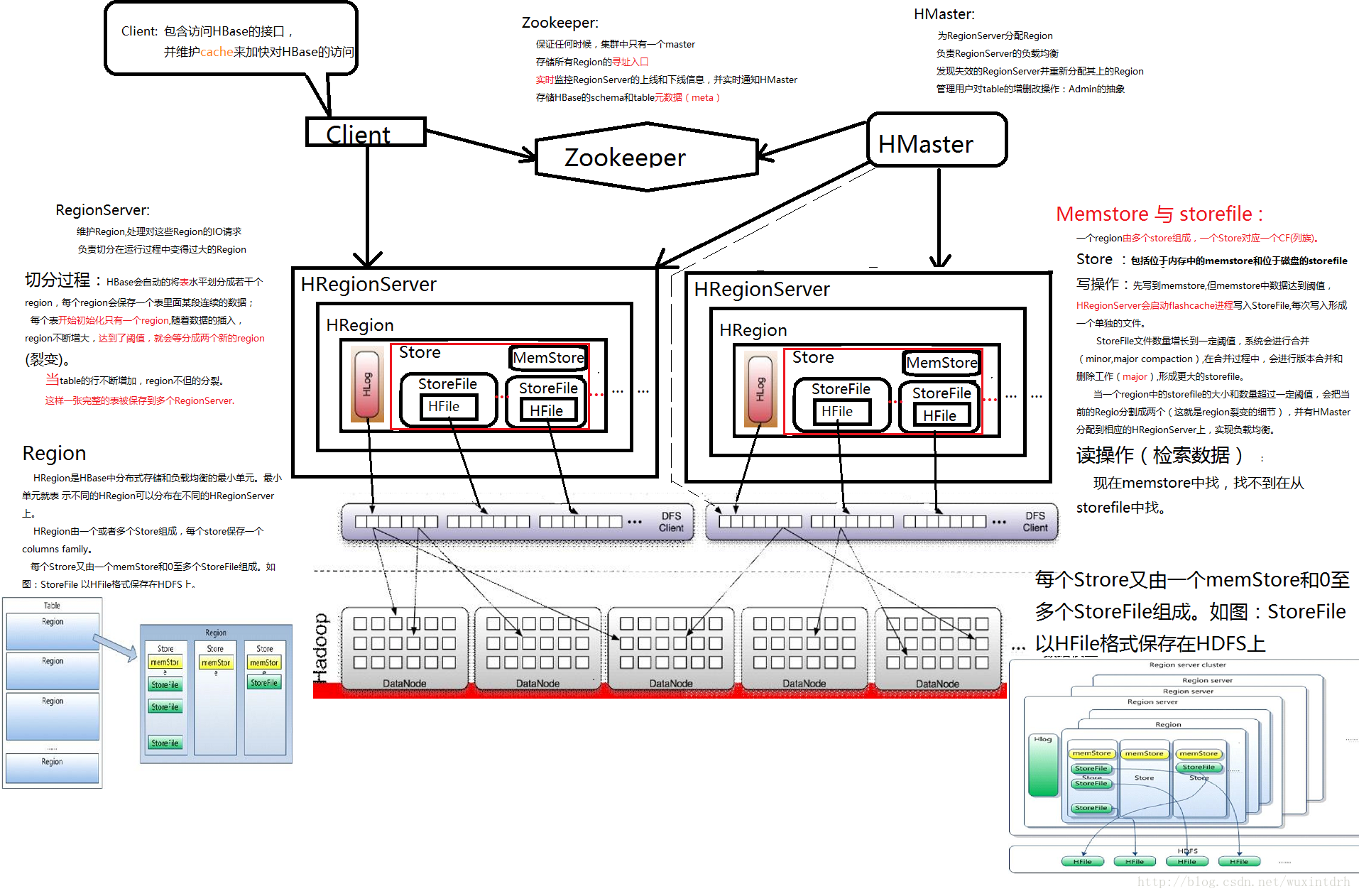
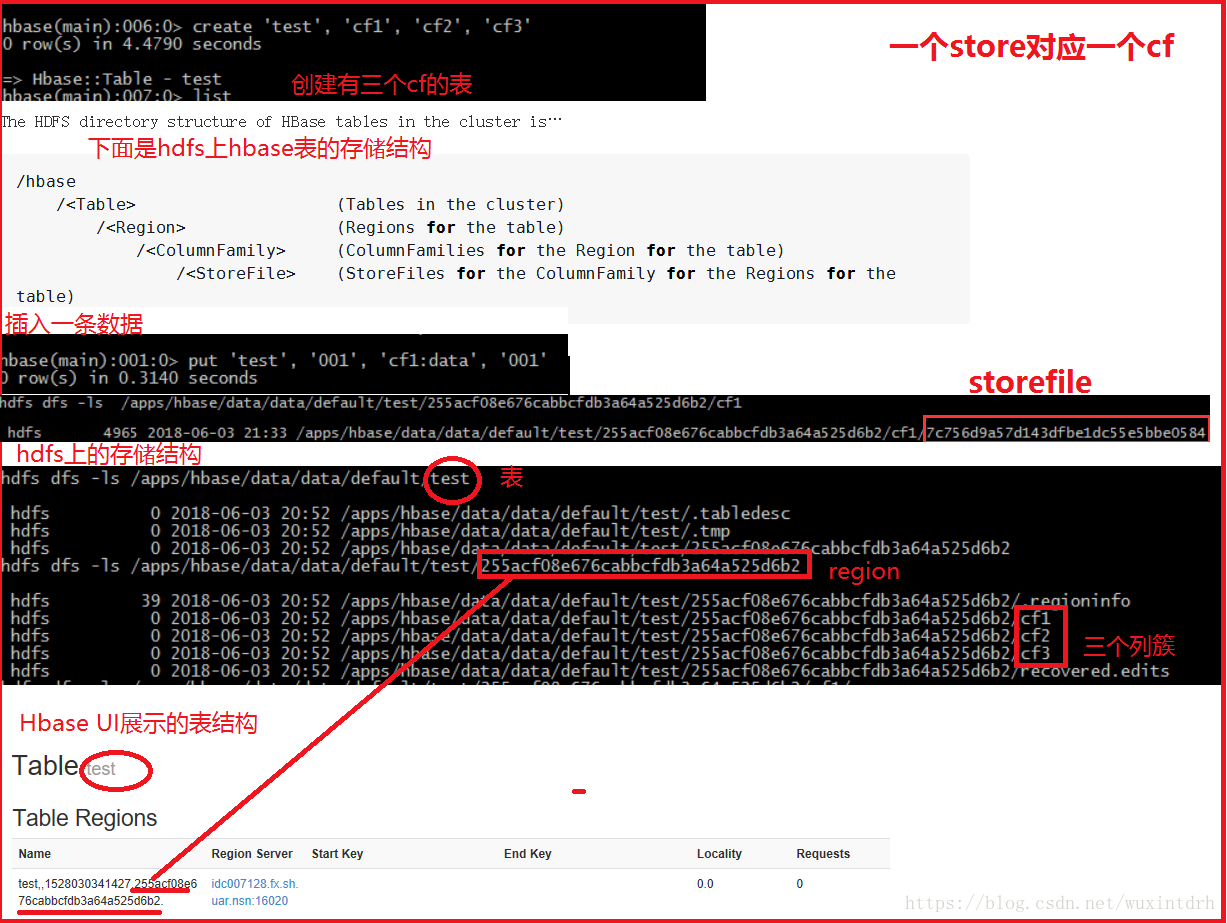
写操作:
Client写入,存入Memstore,Memstore满则Flush成一个Storefile,Storefile文件数量增长到一定的阈值,触发Compact合并操作,多个Storefile合并成一个Storefile,同时进行版本合并和数据删除,当Storefile compact后,逐步形成越来越大的store file,单个store file大小超过一定的阈值后触发split操作,把当前region分裂为两个region,原来的region下线,新的2个region会被hmaster分配到hregionserver上(负载均衡),使得原先1个Region的压力分流到两个上,Hbase只是增加数据,所有的更新和删除操作都是在COMPACT阶段做的。所以用户操作只需要写入到内存即返回,保证IO性能
写入先memstore, storefile,compact,split
读操作:
Client->zookeeper->.ROOT->.META->用户数据表zookeeper记录了.ROOT的路径信息(root只有一个region),.ROOT理记录了.META的region信息(.META信息可能有多个region)
Hbase中,所有的存储文件都被划分成若干小块存储,这些小存储块在get或scan操作时会加载到内存中
Hbase顺序的读取一个数据块到内存缓存中,其读取相邻的数据时就可以在内存中读取而不是从磁盘中再次读取,减少IO次数
HLog
每个HRegionServer中都会有一个HLog(Write Ahead Log),每次用户操作写入Memstore的同时,也写入一份到HLog文件,该文件定期滚动出新,并删除旧的文件(已经持久化到Storefile中的数据)。当HRegionServer意外终止后,HMaster会通过zookeeper感知,HMaster首先处理遗留的HLog文件,将不同的region的log数据拆分,分别放到相应的region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在load region的过程中,会发现有历史的HLog需要处理,因此会replay HLog中的数据到memstore中,然后flush到storefile,完成数据恢复
Hbase数据读写流程的更多相关文章
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- HBase数据读写流程(1.3.1)
===数据写入流程=== 源码:https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/ha ...
- HBase - 数据写入流程解析
本文由 网易云发布. 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松 ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- HBase数据存取流程
一.HBase的特点是什么 1.HBase一个分布式的基于列式存储或者行式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理. 2.HBase适合存储半结构化或非结构化数据,对于 ...
- JuiceFS 数据读写流程详解
对于文件系统而言,其读写的效率对整体的系统性能有决定性的影响,本文我们将通过介绍 JuiceFS 的读写请求处理流程,让大家对 JuiceFS 的特性有更进一步的了解. 写入流程 JuiceFS 对大 ...
- 2.1-2.2 HBase数据存储
一.HBase数据检索流程 一篇介绍HBase数据读写流程的解析的博文:http://hbasefly.com/2016/12/21/hbase-getorscan/?wsfatm=uqvhl3 1. ...
- HBase 文件读写过程描述
HBase 数据读写过程描述 我们熟悉的在 Hadoop 使用的文件格式有许多种,例如: Avro:用于 HDFS 数据序序列化与 Parquet:常见于 Hive 数据文件保存在 HDFS中 HFi ...
- 【HBase】知识小结+HMaster选举、故障恢复、读写流程
1:什么是HBase HBase是一个高可靠性,高性能,面向列,可伸缩的分布式数据库,提供海量数据存储功能,一个结构化的分布式存储系统,不同于一般的关系型数据库,它适合半结构化和非结构化数据存储. 2 ...
随机推荐
- listview 选择后高亮显示
public class UserTypeParentAdapter extends MyBaseAdapter<UserTypeList> { private int selectIte ...
- [UE4]编辑器偏好设置,在同一个窗口以标签打开蓝图
- Android 中Jackson的简单使用
第一步:下载Jackson的jar包http://pan.baidu.com/s/1qXHwtQ0 第二步:在gradle中导入jar包 第三步:创建ObjectMapper对象的单例 Jackson ...
- sed初学者实用说明
转自:http://www.codeweblog.com/sed%E5%88%9D%E5%AD%A6%E8%80%85%E5%AE%9E%E7%94%A8%E8%AF%B4%E6%98%8E/ ...
- windows10配置python
官网下载:https://www.python.org python3---->Download Windows x86-64 executable installer python2----& ...
- elastalert新增自定义警告推送
举例,博主公司有自己的内部通讯工具(类似QQ),接下来用IM代称该工具.于是希望elastalert的警告推送可以支持IM的公众号群发功能. 等博主这个月知识库写了再来补充hah
- CSS 随笔
1.动态修改div的大小 Html: <div> Hello </div> css: div { resize:both; overflow:auto; } 2. box-si ...
- python-模块的导入import
#-*- coding:utf-8 -*- #本次学习:模块的导入 ''' 1.模块名不能与第三方库或者本地库名字重名/冲突 2.导入模块时,寻找顺序:现在当前目录找,再去我们环境变量配置的pytho ...
- 解决从客户端(Content="<div><p ><p>12312...")中检测到有潜在危险的Request.Form 值。
[HttpPost] [ValidateInput(false)]//解决从客户端(Content="<div><p ><p>12312..." ...
- python库myqr生成二维码
python中有一个好玩的库,不仅可以生成各种花色的二维码,还可以生成动态二维码. MyQR是一个能够生成自定义二维码的第三方库,可以根据需要生成普通二维码.带图片的艺术二维码,也可以生成动态二维码 ...