Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题
hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量
mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性
yarn 解决了资源管理调度
二.hadoop生态系统
分层次讲解----> 最底层平台 hdfs yarn mapreduce spark
---- > 应用层 hbase hive pig sparkSQL nutch
----> 工具类 zookeeper flume
三.版本
Apache: 官方版本
Cloudera :使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
HDP(Hortonworks Data Platform) : Hortonworks公司发行版本。
四、伪分布式安装与配置
1.新建app文件夹(mkdir app)用于存放
2.需要jdk环境,普通用户拥有sudo执行权限,关闭防火墙(service iptables stop)及自启(chkconfig iptables off),修改主机名和IP的映射关系(vim /etc/hosts)

3.上传(hadoop-2.4.1.tar.gz)并解压hadoop包到app文件夹(tar -zxvf hadoop-2.4.1.tar.gz -C app/)
4.可以删除hadoop/share的doc文件夹(文档)节省体积(cd app/hadoop-2.4.1/share/ --> rm -rf doc)
5进入hadoop下的etc目录(cd ../etc/hadoop/)
6.修改(vim hadoop-env.sh )将JAVA_HOME改成固定的(echo $JAVA_HOME命令可以获得javahome路径)

7.修改core-site(vim core-site.xml),在configuration中添加
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址,hdfs://后为主机名或者ip地址和端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://jokerq01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,value为hadoopp下新建的用于存储的文件夹 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/app/hadoop-2.4.1/data</value>
</property>
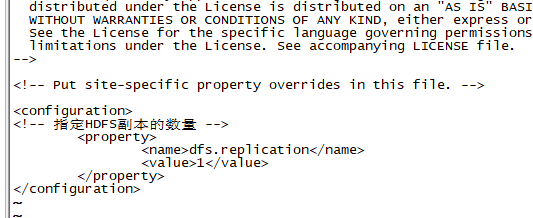
8.修改hdfs-site(vim hdfs-site.xml ),在configuration中添加
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
9.修改mapred-site名称(mv mapred-site.xml.template mapred-site.xml)
10.修改mapred-site(vim mapred-site.xml),在configuration中添加
<!-- 指定mr运行在yarn上,使在集群上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
11.修改yarn-site,(vim yarn-site.xml ),在configuration中添加
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>jokerq01</value>
</property> <!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
12.将hadoop添加到环境变量(目的可以再任意路径下执行hadoop指令)(vim /etc/profile)(对应修改)(修改完成source /etc/profile)
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export HADOOP_HOME=/root/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
13.格式化namenode(是对namenode进行初始化)(hadoop namenode -format)

五、启动
1.进入sbin目录(cd ~/app/hadoop-2.4.1/sbin/)
2.启动HDFS(start-dfs.sh)( 可以修改 vim ~/app/hadoop-2.4.1/etc/hadoop/slaves 将localhost改为主机名)
3.启动YARN(start-yarn.sh)
4.使用jps命令验证是否启动成功(jps)
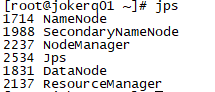
5.可以访问http://192.168.25.151:50070 (HDFS管理界面)(可以修改host文件将ip改为对应的linux机器名)
六、配置ssh免登陆
正常多个机器:
(1-3步骤假设为机器1,机器1中想通过 ssh jokerq01 命令直接连接到jokerq01机器而不需要登录密码的)
1.进入到目录(cd ~/.ssh)
2.执行(ssh-keygen -t rsa)命令 (四个回车,执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥))
3.将公钥拷贝到要免登陆的机器上(需要先修改host文件对应的ip与机器名)(例:scp id_rsa.pub jokerq01:/root)
4.(4-6步骤换到要免登录的机器(jokerq01))(cd ~/.ssh)
5.新建authorized_keys文件(touch authorized_keys)并修改权限(chmod 600 authorized_keys)

6.将拷贝的公钥追加到后面(cat ../id_rsa.pub >> ./authorized_keys)
7.在机器1中通过 (ssh jokerq01) 命令直接登录
伪分布式:
1.(cd ~/.ssh)(ssh-keygen -t rsa)
2.直接追加(cat id_rsa.pub >> authorized_keys)
3.自己连接自己不需要密码(ssh jokerq01)

七、HDFS的JAVA客户端编写()
linux:
1.将linux改为图形界面(内存调大)用来运行eclipse(startx)(失败参考https://blog.csdn.net/baidu_19473529/article/details/54235030)
2.安装eclipse
2.1上传压缩包(eclipse-jee-photon-R-linux-gtk.tar.gz),并解压(可以命令,也可以右键Extract Here)
3.运行文件夹的eclipse(图标不适应可以修改图标),并新建java项目(java project)
4.导入jar包(在hadoop-2.4.1\share\hadoop\hdfs下的hadoop-hdfs-2.4.1.jar,还有hadoop-2.4.1\share\hadoop\hdfs\lib下的所有jar包,hadoop-2.4.1\share\hadoop\common下的hadoop-common-2.4.1.jar,hadoop-2.4.1\share\hadoop\common\lib下的所有jar包)
5.编写测试代码
windows:
1.建项目,导jar包,写代码
2.直接JUnit Test报错,运行需要用户名修改为拥有linux文件可操作权限的用户(右键,run as,run configurations,Arguments,添加-DHADOOP_USER_NAME=root)
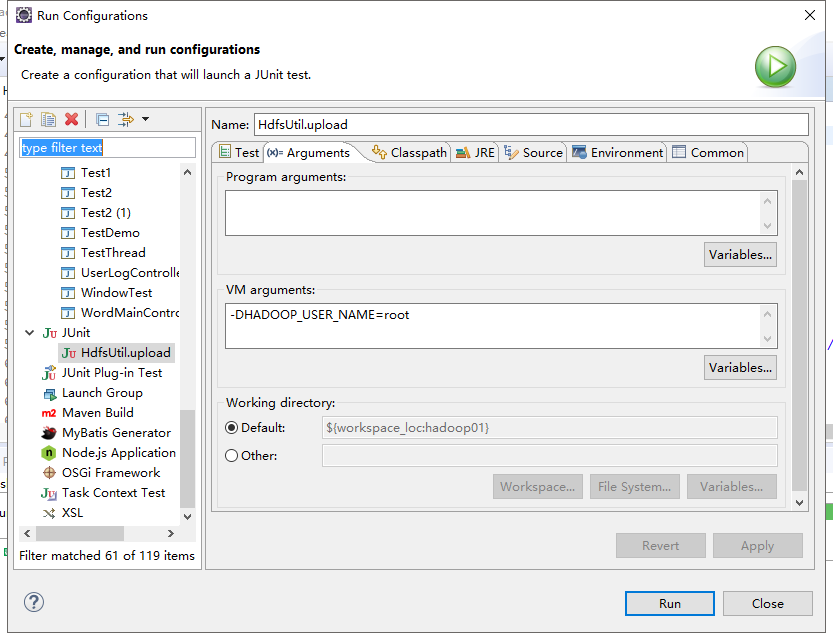
也可以FileSystem.get()方法指定用户
FileSystem fs = null;
@Before
public void init() throws Exception{
//读取classpath下的xxx-site.xml 配置文件,并解析其内容,封装到conf对象中
Configuration conf = new Configuration();
//也可以在代码中对conf中的配置信息进行手动设置,会覆盖掉配置文件中的读取的值
conf.set("fs.defaultFS", "hdfs://jokerq01:9000/");
//根据配置信息,去获取一个具体文件系统的客户端操作实例对象
fs = FileSystem.get(new URI("hdfs://jokerq01:9000/"),conf,"root"); }
Hadoop大数据初入门----haddop伪分布式安装的更多相关文章
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Zookeeper 初体验之——伪分布式安装(转)
原文地址: http://blog.csdn.net/salonzhou/article/details/47401069 简介 Apache Zookeeper 是由 Apache Hadoop 的 ...
- 【每天五分钟大数据-第一期】 伪分布式+Hadoopstreaming
说在前面 之前一段时间想着把 LeetCode 每个专题完结之后,就开始着手大数据和算法的内容. 想来想去,还是应该穿插着一起做起来. 毕竟,如果只写一类的话,如果遇到其他方面,一定会遗漏一些重要的点 ...
- Hadoop大数据平台入门——HDFS和MapReduce
随着硬件水平的不断提高,需要处理数据的大小也越来越大.大家都知道,现在大数据有多火爆,都认为21世纪是大数据的世纪.当然我也想打上时代的便车.所以今天来学习一下大数据存储和处理. 随着数据的不断变大, ...
- [Hadoop大数据]--kafka入门
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行“随机读写”的原因是什么? 3.kafka集群consumer和producer状态信息是如何保存的? ...
- Hadoop系列(二)hadoop2.2.0伪分布式安装
一.环境配置 安装虚拟机vmware,并在该虚拟机机中安装CentOS 6.4: 修改hostname(修改配置文件/etc/sysconfig/network中的HOSTNAME=hadoop),修 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- hadoop大数据平台安全基础知识入门
概述 以 Hortonworks Data Platform (HDP) 平台为例 ,hadoop大数据平台的安全机制包括以下两个方面: 身份认证 即核实一个使用者的真实身份,一个使用者来使用大数据引 ...
随机推荐
- div在页面垂直居中方法---增强改进版
div在页面垂直居中方法---改进版 .wrap{ background: #ffffff; position:absolute; margin:auto; top:; bottom:; left:; ...
- Web API 2 对于 Content-Length 要求严格
最近在做一个工具,里面有一个发起http请求的操作,虽然工具不是用.NET写的,但是测试用服务器软件是.NET写的.在这里选择了ASP.NET MVC和Web API 2. 首先预定义Student与 ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第三周(Hyperparameter tuning, Batch Normalization and Programming Frameworks) —— 2.Programming assignments
Tensorflow Welcome to the Tensorflow Tutorial! In this notebook you will learn all the basics of Ten ...
- 全球各大邮件SMTP服务限制
常用免费SMTP服务的发送限制,转贴 GMail 免费邮箱 http://gmail.google.comSMTP 服务器:smtp.gmail.com策略:发送延时 0,每天发送量限制 50(GMa ...
- godaddy 问题
1. 域名被锁,打电话咨询后.说发送被锁的域名到: change@secureserver.net 去解锁.
- 关于配置 TeamCity 清理历史 artifacts 问题
使用 CI 一段时间后,artifacts 占用的磁盘会很大,可以配置保留多少天的 artifacts,具体如下: Administration Click the Edit link for any ...
- 【转】Windows 8 desktop app中dll搜索路径设置的诡异现象,Bug?
原文地址:http://blog.csdn.net/my_business/article/details/8850151 某个桌面程序在win 8上运行异常的问题困扰了我有近一周,今天终于找到了根本 ...
- PPT-常用快捷键
Ctrl+Shift+C 复制文本格式 Ctrl+Shift+V 粘贴文本格式 Ctrl+B 应用粗体格式Ctrl+U 应用下划线Ctrl+l 应用斜体格式 全选 Ctrl + A 光标之后 ...
- Vue + Element UI 实现权限管理系统 前端篇(七):功能组件封装
组件封装 为了避免组件代码的臃肿,这里对主要的功能部件进行封装,保证代码的模块化和简洁度. 组件结构 组件封装重构后,试图组件结构如下图所示 代码一览 Home组件被简化,包含导航.头部和主内容三个组 ...
- piplinedb 安装配置
piplinedb不能使用root用户操作,提前建好用户 [root@yzh-jkb-privatization /]# useradd steven [root@yzh-jkb-privatizat ...