[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)
适合大数据的分布式存储与计算平台
官方版本(1.0.4)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Yahoo内部使用的版本,发布过两次,已有的版本都放到了Apache上,后续不在继续发布,而是集中在Apache的版本上。
== HDFS ==


诉求:
Data processed by Google every month: 400 PB … in 2007
问题:
MapReduce+HDFS思想:
MapReduce 思想:
HDFS思想:




官方版本(2.4.1)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Hortonworks公司发行版本。
hadoop核心
资源管理调度系统
问题:怎样解决海量数据的存储?

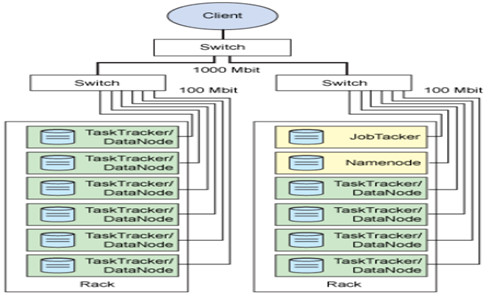
HDFS的架构
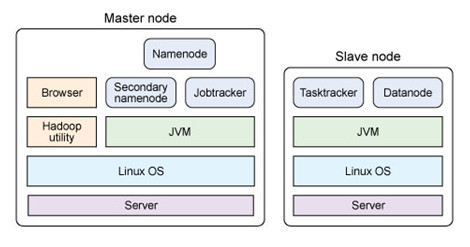
主从结构 主节点, namenode 从节点,有很多个: datanode namenode负责: 接收用户操作请求 维护文件系统的目录结构 管理文件与block之间关系,block与datanode之间关系 datanode负责: 存储文件 文件被分成block存储在磁盘上 为保证数据安全,文件会有多个副本

问题:怎样解决海量数据的计算?

hadoop1.0和hadoop2.0的对比

Hadoop部署方式
伪分布模式安装步骤
修改hadoop配置文件
1.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/
2.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
&
3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
</property>
</configuration>
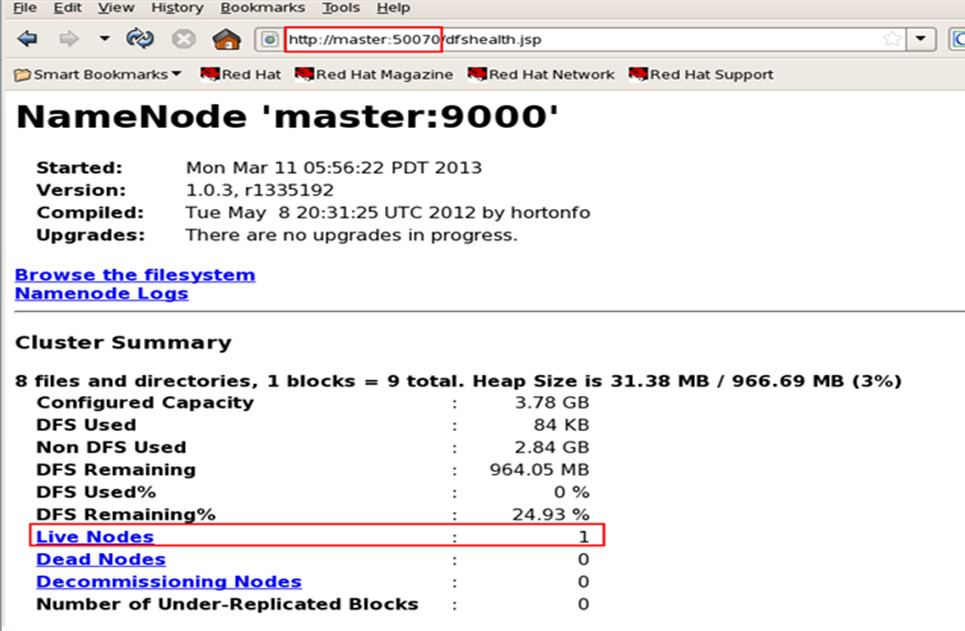
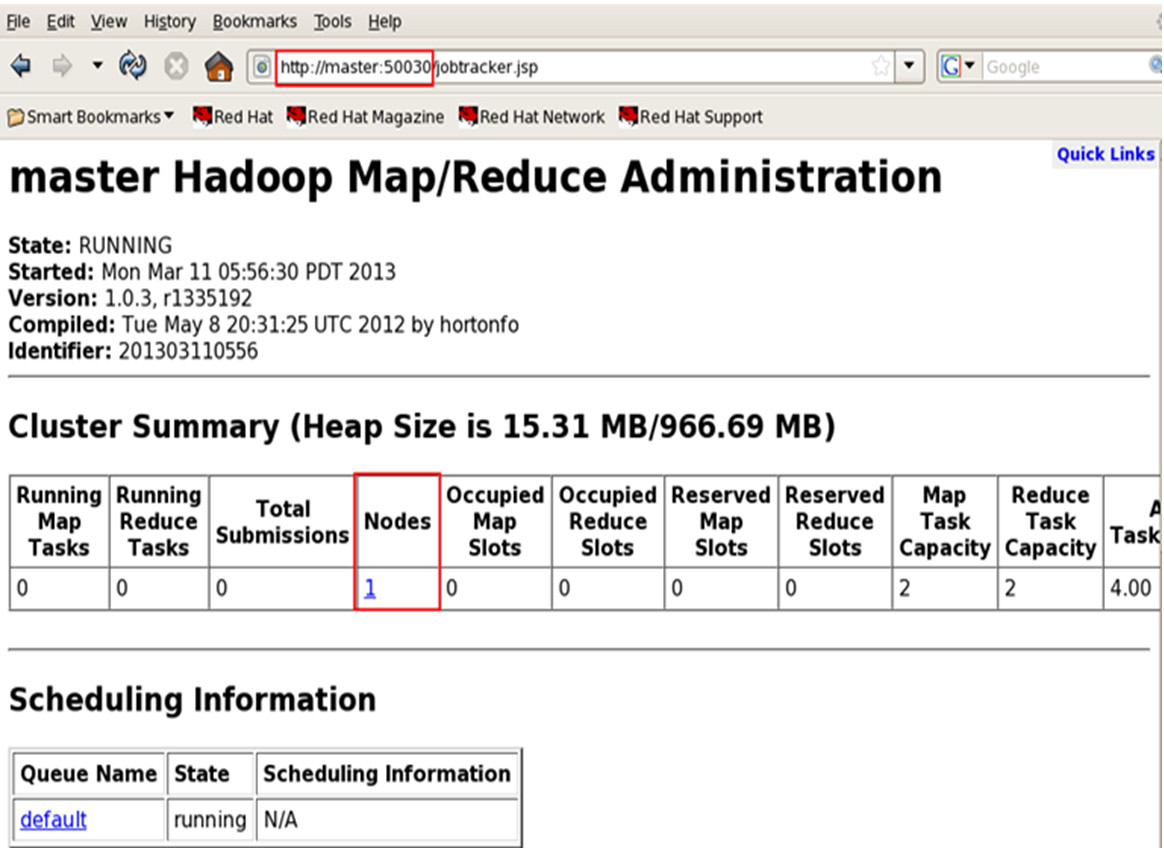
浏览hadoop
&
练习:搭建伪分布环境
思考题
常用linux命令

[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)的更多相关文章
- [BigData]关于Hadoop学习笔记第二天(PPT总结)(一)
Plan: 分布式文件系统与HDFS HDFS体系结构与基本概念 HDFS的shell操作 java接口及常用api HADOOP的RPC机制 HDFS源码分析 远程debug 自己设计一分布式文件系 ...
- [BigData]关于Hadoop学习笔记第四天(PPT总结)(一)
课程安排 Partitioner编程** 自定义排序编程** Combiner编程** 常见的MapReduce算法** ---------------------------加深拓展-------- ...
- [BigData]关于Hadoop学习笔记第三天(PPT总结)(一)
课程安排 MapReduce原理*** MapReduce执行过程** 数据类型与格式*** Writable接口与序列化机制*** ---------------------------加深拓展- ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- Hadoop学习笔记之HBase Shell语法练习
Hadoop学习笔记之HBase Shell语法练习 作者:hugengyong 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- POJ 1797 Heavy Transportation (dijkstra 最小边最大)
Heavy Transportation 题目链接: http://acm.hust.edu.cn/vjudge/contest/66569#problem/A Description Backgro ...
- UVA 11300 Spreading the Wealth
题目大意:n个人手中有些金币,每个人可给相邻两个人一些金币,使得最终每个人手中金币数相同,求被转手的金币最少数 m为最终每个人手中的金币数,a1,a2,a3,...,an为每个人开始时手中的金币数,x ...
- Spring Data Solr教程(翻译)
大多数应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能 这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr ...
- 转:使用memc-nginx和srcache-nginx模块构建高效透明的缓存机制
原文地址:http://blog.codinglabs.org/articles/nginx-memc-and-srcache.html 为了提高性能,几乎所有互联网应用都有缓存机制,其中Memcac ...
- C# 生成解决方案失败,点击项目重新生成报找不到命名空间
1.点击生成解决方案失败,点击项目“重新生成”找不到“XXX”命名空间. 尝试点击"重新生成解决方案"多次,然后点击项目的"重新生成"即可解决.
- thttpd的定时器
运用了static函数实现文件封装 提升变量访问效率的关键字register,该关键字暗示该变量可能被频繁访问,如果可能,请将值存放在寄存器中 内存集中管理,每个节点在取消后并没有立即释放内存,而是调 ...
- hdu 5569 matrix dp
matrix Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=5569 D ...
- HDU 5514 Frogs 容斥定理
Frogs Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=5514 De ...
- C# 手动读写app config 的源码
public class ConfigOperator { public string strFileName; public string configName; public string con ...
- HttpClient post json
public static JSONObject post(String url,JSONObject json){ HttpClient client = new DefaultHttpClient ...