[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)
适合大数据的分布式存储与计算平台
官方版本(1.0.4)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Yahoo内部使用的版本,发布过两次,已有的版本都放到了Apache上,后续不在继续发布,而是集中在Apache的版本上。
== HDFS ==


诉求:
Data processed by Google every month: 400 PB … in 2007
问题:
MapReduce+HDFS思想:
MapReduce 思想:
HDFS思想:




官方版本(2.4.1)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Hortonworks公司发行版本。
hadoop核心
资源管理调度系统
问题:怎样解决海量数据的存储?

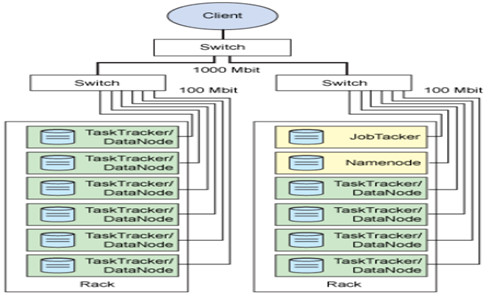
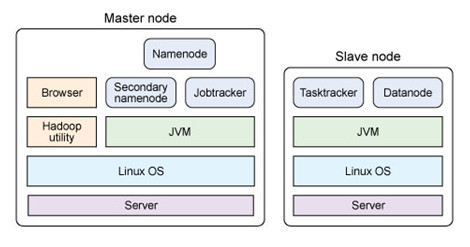
HDFS的架构
主从结构 主节点, namenode 从节点,有很多个: datanode namenode负责: 接收用户操作请求 维护文件系统的目录结构 管理文件与block之间关系,block与datanode之间关系 datanode负责: 存储文件 文件被分成block存储在磁盘上 为保证数据安全,文件会有多个副本

问题:怎样解决海量数据的计算?

hadoop1.0和hadoop2.0的对比

Hadoop部署方式
伪分布模式安装步骤
修改hadoop配置文件
1.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/
2.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
&
3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
</property>
</configuration>
浏览hadoop
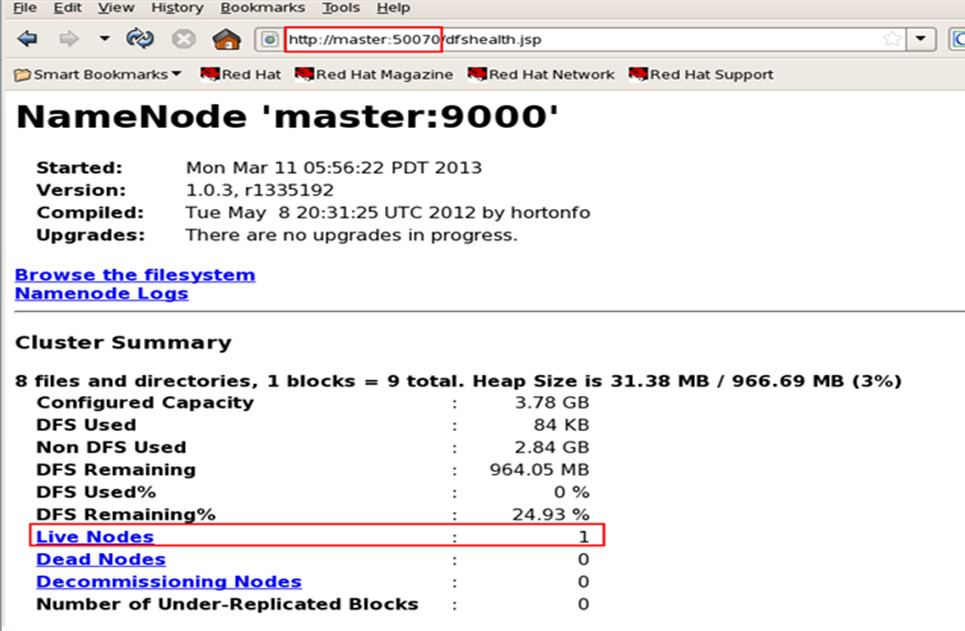
&
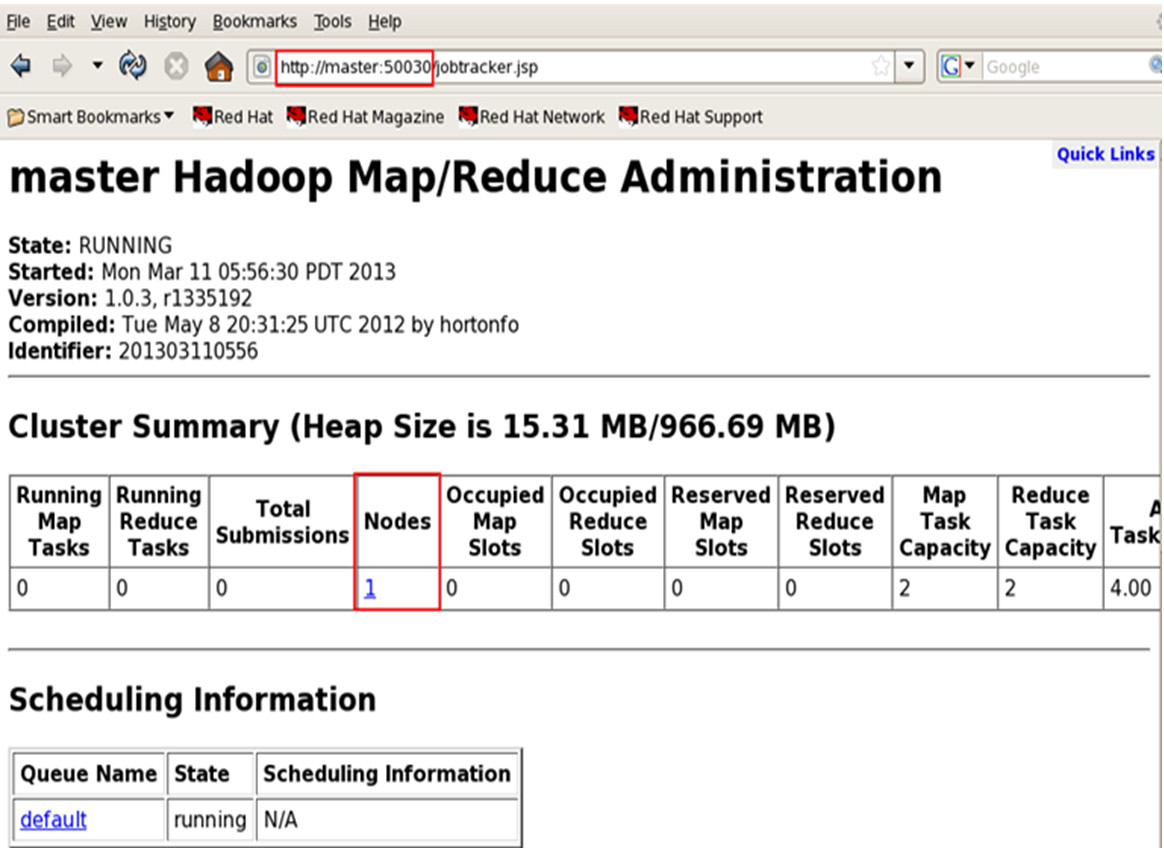
练习:搭建伪分布环境
思考题
常用linux命令

[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)的更多相关文章
- [BigData]关于Hadoop学习笔记第二天(PPT总结)(一)
Plan: 分布式文件系统与HDFS HDFS体系结构与基本概念 HDFS的shell操作 java接口及常用api HADOOP的RPC机制 HDFS源码分析 远程debug 自己设计一分布式文件系 ...
- [BigData]关于Hadoop学习笔记第四天(PPT总结)(一)
课程安排 Partitioner编程** 自定义排序编程** Combiner编程** 常见的MapReduce算法** ---------------------------加深拓展-------- ...
- [BigData]关于Hadoop学习笔记第三天(PPT总结)(一)
课程安排 MapReduce原理*** MapReduce执行过程** 数据类型与格式*** Writable接口与序列化机制*** ---------------------------加深拓展- ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- Hadoop学习笔记之HBase Shell语法练习
Hadoop学习笔记之HBase Shell语法练习 作者:hugengyong 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- 【转】linux代码段,数据段,BSS段, 堆,栈
转载自 http://blog.csdn.net/wudebao5220150/article/details/12947445 linux代码段,数据段,BSS段, 堆,栈 网上摘抄了一些,自己组 ...
- LightOJ 1074 Extended Traffic (最短路spfa+标记负环点)
Extended Traffic 题目链接: http://acm.hust.edu.cn/vjudge/contest/122685#problem/O Description Dhaka city ...
- linux下登陆用户的行为信息—w和who命令详解
查看用户的操作系统管理员若想知道某一时刻用户的行为,只需要输入命令w 即可,在SHELL终端中输入如下命令: [root@localhost ~]# w 可以看到执行w命令及显示结果. 命令信息含义上 ...
- Spring Data JPA教程, 第二部分: CRUD(翻译)
我的Spring Data Jpa教程的第一部分描述了,如何配置Spring Data JPA,本博文进一步描述怎样使用Spring Data JPA创建一个简单的CRUD应用.该应用要求如下: pe ...
- TestDriven.NET – 快速入门
TestDriven.NET – 快速入门[译文] 介绍 这部分将提供一个快速的入门向导,在vs.NET的任何一个版本上面使用TestDriven.NET TDD(测试驱动开发)在你写你的代码之前,写 ...
- C#自定义控件的开发:Pin和Connector
C#自定义控件的开发:Pin和Connector 2009-08-03 14:46 wonsoft hi.baidu 我要评论(0) 字号:T | T 本文介绍了如何使用智能设备扩展C#自定义控件. ...
- ALT(预警)
1. Alert简介 Alert是一种Oracle系统中的一种机制,它可以监视系统数据库,在规定的情况下给规定用户一个通知,通知可以是邮件或者其他形式,在标注的系统和客户化系统中都是可以定义使用的 2 ...
- maven使用.01.Hello World
要说Java世界有什么东西是我最为留恋的:在写其他语言程序的时候,我最为想要的东西,那非maven莫属. 什么是Maven? Maven能做什么? Maven是一个针对Java的自动构建工具.所谓自动 ...
- URAL 1777 D - Anindilyakwa 暴力
D - AnindilyakwaTime Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://acm.hust.edu.cn/vjudge/contest/v ...
- MaterialDesignLibrary
https://github.com/navasmdc/MaterialDesignLibrary MaterialDesignLibrary.zip