hadoop数据流转过程分析
hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转。
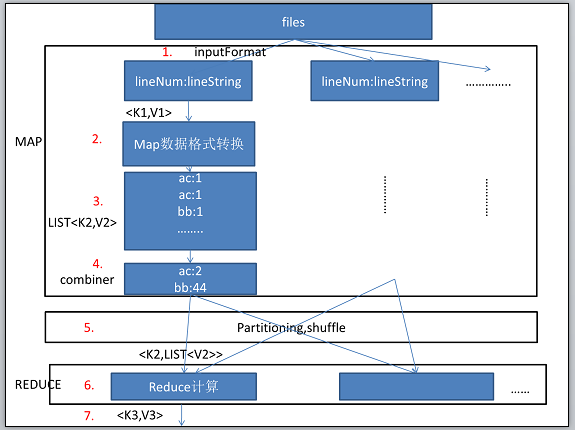
public void map(LongWritable key,Text Value,OutputCollector<Text,Inwritable> output,Reporter reporter){//output为map函数的输出。
String line = value.toString();//每行的值
StringTokenizer itr = new StringTokenizer(line);//根据空格分词
while(itr.hasMoreTokens()){
output.collect( new Text().set(itr.nextToken()),new IntWritable(1));//输出 ,key为单词,value为1.
}
}
public void reduce(Text key,Interator<InWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{
int sum = 0;
while(values.hasNext()){//求和
sum += values.next().get();
}
output.collect(key,new IntWritable(sum));//输出
}
hadoop数据流转过程分析的更多相关文章
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Struts2(三)——数据在框架中的数据流转问题
一款软件,无在乎对数据的处理.而B/S软件,一般都是用户通过浏览器客户端输入数据,传递到服务器,服务器进行相关处理,然后返回到指定的页面,进行相关显示,完成相关功能.这篇博客重点简述一下Struts2 ...
- 面向UI编程:ui.js 1.1 使用观察者模式完成组件之间数据流转,彻底分离组件之间的耦合,完成组件的高内聚
开头想明确一些概念,因为有些概念不明确会导致很多问题,比如你写这个框架为什么不去解决啥啥啥的问题,哎,心累. 什么是框架? 百度的解释:框架(Framework)是整个或部分系统的可重用设计,表现为一 ...
- 关系数据库数据与hadoop数据进行转换的工具 - Sqoop
Sqoop 本文所使用的Sqoop版本为1.4.6 1.官网 http://sqoop.apache.org 2.作用 A:可以把hadoop数据导入到关系数据库里面(e.g. Hive -> ...
- Hadoop数据读写原理
数据流 MapReduce作业(job)是客户端执行的单位:它包括输入数据.MapReduce程序和配置信息.Hadoop把输入数据划分成等长的小数据发送到MapReduce,称之为输入分片.Hado ...
- hadoop数据容易出现错误的地方
最近在搞关于数据分析的项目,做了一点总结. 下图是系统的数据流向.容易出现错误的地方.1.数据进入hadoop仓库有四种来源,这四种是最基本的数据,简称ods,original data source ...
- hadoop 数据采样
http://www.cnblogs.com/xuxm2007/archive/2012/03/04/2379143.html 原文地址如上: 关于Hadoop中的采样器 .为什么要使用采样器 在这个 ...
- Hadoop数据操作系统YARN全解析
“ Hadoop 2.0引入YARN,大大提高了集群的资源利用率并降低了集群管理成本.其在异构集群中是怎样应用的?Hulu又有哪些成功实践可以分享? 为了能够对集群中的资源进行统一管理和调度,Hado ...
- Hadoop 数据排序(一)
1.概述 1TB排序通常用于衡量分布式数据处理框架的数据处理能力.Terasort是Hadoop中的的一个排序作业.那么Terasort在Hadoop中是怎样实现的呢?本文主要从算法设计角度分析Ter ...
随机推荐
- iOS runtime 运行时( - )
谈到运行时,相对应的就有编译时: 1).运行时-- 直到程序运行时才去确定一个对象的具体信息,并且可以改变这个类的具体信息,包括它的方法,变量等等: 2).编译时-- 是在程序运行之前,编译的时候,就 ...
- MVC框架 - 捆绑
捆绑和缩小是两个性能改进提高应用程序在请求负载时的技术.目前大多数的主流浏览器限制每个主机同时连接到六个数量.这意味着,在一个时间,所有的其他请求将被浏览器排队. 启用捆绑和缩小 为使捆绑和缩小MVC ...
- 在虚拟环境中安装pygame
http://www.pygame.org/wiki/CompileUbuntu#Python%203.x%20into%20virtual%20environment 先安装依赖: ᐅ sudo a ...
- 【Android 界面效果24】Intent和PendingIntent的区别
intent英文意思是意图,pending表示即将发生或来临的事情. PendingIntent这个类用于处理即将发生的事情.比如在通知Notification中用于跳转页面,但不是马上跳转. In ...
- 使用subversion搭建SVN
使用subversion搭建SVN需要用到的软件包有subversion,apr,apr-util,sqlite,zlib,因为在编译安装subversion时需要指明apr.apr-util.sql ...
- HDU 1069 Monkey and Banana (DP)
Monkey and Banana Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u S ...
- codeforces 677B B. Vanya and Food Processor(模拟)
题目链接: B. Vanya and Food Processor time limit per test 1 second memory limit per test 256 megabytes i ...
- 转: Android入门及效率开发
评注: android第三方开源框架介绍不错 转:https://segmentfault.com/a/1190000004495351 入门 Android官方培训课程中文版:http://huka ...
- date & dirname
date 年:+%Y 月:+%m 日:+%d 时:+%H 或者 +%k 分:+%M 秒:+%S 周:+%w dirname 目录 获取目录的上级目录
- GDB使用
1.display val 设置显示格式 2.i b显示所有断点