hadoop数据流转过程分析
hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转。
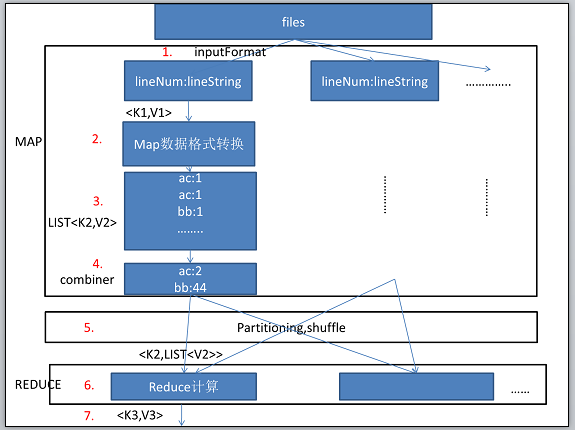
public void map(LongWritable key,Text Value,OutputCollector<Text,Inwritable> output,Reporter reporter){//output为map函数的输出。
String line = value.toString();//每行的值
StringTokenizer itr = new StringTokenizer(line);//根据空格分词
while(itr.hasMoreTokens()){
output.collect( new Text().set(itr.nextToken()),new IntWritable(1));//输出 ,key为单词,value为1.
}
}
public void reduce(Text key,Interator<InWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{
int sum = 0;
while(values.hasNext()){//求和
sum += values.next().get();
}
output.collect(key,new IntWritable(sum));//输出
}
hadoop数据流转过程分析的更多相关文章
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Struts2(三)——数据在框架中的数据流转问题
一款软件,无在乎对数据的处理.而B/S软件,一般都是用户通过浏览器客户端输入数据,传递到服务器,服务器进行相关处理,然后返回到指定的页面,进行相关显示,完成相关功能.这篇博客重点简述一下Struts2 ...
- 面向UI编程:ui.js 1.1 使用观察者模式完成组件之间数据流转,彻底分离组件之间的耦合,完成组件的高内聚
开头想明确一些概念,因为有些概念不明确会导致很多问题,比如你写这个框架为什么不去解决啥啥啥的问题,哎,心累. 什么是框架? 百度的解释:框架(Framework)是整个或部分系统的可重用设计,表现为一 ...
- 关系数据库数据与hadoop数据进行转换的工具 - Sqoop
Sqoop 本文所使用的Sqoop版本为1.4.6 1.官网 http://sqoop.apache.org 2.作用 A:可以把hadoop数据导入到关系数据库里面(e.g. Hive -> ...
- Hadoop数据读写原理
数据流 MapReduce作业(job)是客户端执行的单位:它包括输入数据.MapReduce程序和配置信息.Hadoop把输入数据划分成等长的小数据发送到MapReduce,称之为输入分片.Hado ...
- hadoop数据容易出现错误的地方
最近在搞关于数据分析的项目,做了一点总结. 下图是系统的数据流向.容易出现错误的地方.1.数据进入hadoop仓库有四种来源,这四种是最基本的数据,简称ods,original data source ...
- hadoop 数据采样
http://www.cnblogs.com/xuxm2007/archive/2012/03/04/2379143.html 原文地址如上: 关于Hadoop中的采样器 .为什么要使用采样器 在这个 ...
- Hadoop数据操作系统YARN全解析
“ Hadoop 2.0引入YARN,大大提高了集群的资源利用率并降低了集群管理成本.其在异构集群中是怎样应用的?Hulu又有哪些成功实践可以分享? 为了能够对集群中的资源进行统一管理和调度,Hado ...
- Hadoop 数据排序(一)
1.概述 1TB排序通常用于衡量分布式数据处理框架的数据处理能力.Terasort是Hadoop中的的一个排序作业.那么Terasort在Hadoop中是怎样实现的呢?本文主要从算法设计角度分析Ter ...
随机推荐
- Python练习题 004:判断某日期是该年的第几天
[Python练习题 004]输入某年某月某日,判断这一天是这一年的第几天? ---------------------------------------------- 这题竟然写了 28 行代码! ...
- 2013年arcgis培训
关于开展“GIS空间分析及应用案例解析”培训班的通知 各企事业单位: 随着信息技术的发展,地理信息系统(简称GIS)产业异军突起,在国民经济各个行业中的应用日益广泛,物联网.智慧地球.3S技术等等 ...
- Windows环境下安装Redis
1:首先下载redis.从下面地址下:https://github.com/MSOpenTech/redis/releases2:创建redis.conf文件:这是一个配置文件,指定了redis的监听 ...
- spring中配置jndi数据源
spring AplicationContext.xml中的配置 <bean id="dataSource1" class="org.springframewor ...
- 关于onClick 提交数据问题
我在添加 民工考勤表,用ajax 自动读取数据添加到相应模块之后 进行 OnClick="btnSubmit_Click" 保存,结果无法保存,之后我将光标锁定到某一个文本框内,就 ...
- React Native学习-measure测量view的宽高值
measure()测量是根据view标签中的ref属性,使用方法如下: measureWatermarkerImage(){ this.refs.watermarkerImage.measure((a ...
- JQuery获取append后的动态元素
在使用ajax请求后,使用jquery将数据append到网页中.发现jquery无法使用append内的id和class获取元素. 例如:$("ul").append(" ...
- asp.net渐变
简介:第一个参数代表渐变的方向,后面的StartColorStr和End就不用解释了: filter: progid:DXImageTransform.Microsoft.Gradient(Gradi ...
- Android异步下载网络图片
最近新做的一个项目,里面需要下载网络上的图片,并显示在UI界面上,学Android有个常识,就是Android中在主线程中没法直接更新UI的,要想更新UI必须另外开启一个线程来实现,当开启的线程完成图 ...
- Part 53 to 55 Talking about Reflection in C#
Part 53 Reflection in C# Part 54 Reflection Example here is the code private void btnDiscover_Click( ...