MySQL Group Relication 部署环境入门篇
| 端口号 | 数据目录 | group_repplicatoon 通信接口 | |
| 3307 | /data/mysql/mysql_3306{data,logs,tmp} | 23307 | |
| 3308 | /data/mysql/mysql_3307{data,logs,tmp} | 23308 | |
| 3309 | /data/mysql/mysql_3308{data,logs,tmp} | 23309 |
环境的准备:
#my.cnf[client]port = 3307socket = /tmp/mysql3307.sock[mysql]prompt="\\u@\\h:\\p [\\d]>#pager="less -i -n -S"#tee=/home/mysql/query.logno-auto-rehash[mysqld]#miscuser = mysqlbasedir = /usr/local/mysqldatadir = /data/mysql/mysql_3306/dataport = 3306socket = /tmp/mysql3306.sockevent_scheduler = 0tmpdir=/data/mysql/mysql_3306/tmp#timeoutinteractive_timeout = 300wait_timeout = 300#character setcharacter-set-server = utf8open_files_limit = 65535max_connections = 100max_connect_errors = 100000#explicit_defaults_for_timestamp#logslog-output=fileslow_query_log = 1slow_query_log_file = slow.loglog-error = error.loglog_error_verbosity=3pid-file = mysql.pidlong_query_time = 1#log-slow-admin-statements = 1#log-queries-not-using-indexes = 1log-slow-slave-statements = 1#binlogbinlog_format = rowlog-bin = /data/mysql/mysql_3306/logs/mysql-binbinlog_cache_size = 1Mmax_binlog_size = 200Mmax_binlog_cache_size = 2Gsync_binlog = 0expire_logs_days = 10#group replicationserver_id=1013307gtid_mode=ONenforce_gtid_consistency=ONmaster_info_repository=TABLErelay_log_info_repository=TABLEbinlog_checksum=NONElog_slave_updates=ONbinlog_format=ROWtransaction_write_set_extraction=XXHASH64loose-group_replication_group_name="3db33b36-0e51-409f-a61d-c99756e90155"loose-group_replication_start_on_boot=offloose-group_replication_local_address= "192.168.5.100:23307" ###注意端口号,要区分开,不要和我们默认的3306混淆了loose-group_replication_group_seeds= "192.168.5.100:23307,192.168.5.100:23308,192.168.5.100:23309"loose-group_replication_bootstrap_group= offloose-group_replication_single_primary_mode=offloose-group_replication_enforce_update_everywhere_checks=on#relay logskip_slave_start = 1max_relay_log_size = 500Mrelay_log_purge = 1relay_log_recovery = 1#slave-skip-errors=1032,1053,1062#buffers & cachetable_open_cache = 2048table_definition_cache = 2048table_open_cache = 2048max_heap_table_size = 96Msort_buffer_size = 2Mjoin_buffer_size = 2Mthread_cache_size = 256query_cache_size = 0query_cache_type = 0query_cache_limit = 256Kquery_cache_min_res_unit = 512thread_stack = 192Ktmp_table_size = 96Mkey_buffer_size = 8Mread_buffer_size = 2Mread_rnd_buffer_size = 16Mbulk_insert_buffer_size = 32M#myisammyisam_sort_buffer_size = 128Mmyisam_max_sort_file_size = 10Gmyisam_repair_threads = 1#innodbinnodb_buffer_pool_size = 100Minnodb_buffer_pool_instances = 1innodb_data_file_path = ibdata1:100M:autoextendinnodb_flush_log_at_trx_commit = 2innodb_log_buffer_size = 64Minnodb_log_file_size = 256Minnodb_log_files_in_group = 3innodb_max_dirty_pages_pct = 90innodb_file_per_table = 1innodb_rollback_on_timeoutinnodb_status_file = 1innodb_io_capacity = 2000transaction_isolation = READ
#mysql>SET SQL_LOG_BIN=0#mysql>CREATE USER rpl_user@'%';#mysql>GRANT REPLICATION SLAVE ON *.* TO 'rpl_user'@'%' identified by '123456';#mysql>SET SQL_LOG_BIN=1
change master to master_user='rpl_user',MASTER_PASSWORD='123456' for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';

#mysql> set global group_replication_bootstrap_group=ON; # 只在第一个节点使用
#mysq>START GROUP_REPLICATION;
stop group_replication;
select * from performance_schema.replication_group_members;

创建一个测试库
create database czg;use czg;create table t1 (id int not null,name varchar(32), primary key(id));insert into t1 values(1,'chen'),('2','zhang');
./mysqld --defaults-file=/data/mysql/mysql_3308/my_3308.cnf --initialize-insecure
#mysql>SET SQL_LOG_BIN=0#mysql>CREATE USER rpl_user@'%';#mysql>GRANT REPLICATION SLAVE ON *.* TO 'rpl_user'@'%' identified by '123456';#mysql>SET SQL_LOG_BIN=1
change master to master_user='rpl_user',MASTER_PASSWORD='123456' for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';
select * from performance_schema.replication_group_members;

第三个节点的安装:
初始化实列
./mysqld --defaults-file=/data/mysql/mysql_3309/my_3309.cnf --initialize-insecure
#mysql>SET SQL_LOG_BIN=0#mysql>CREATE USER rpl_user@'%';#mysql>GRANT REPLICATION SLAVE ON *.* TO 'rpl_user'@'%' identified by '123456';#mysql>SET SQL_LOG_BIN=1
change master to master_user='rpl_user',MASTER_PASSWORD='123456' for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';

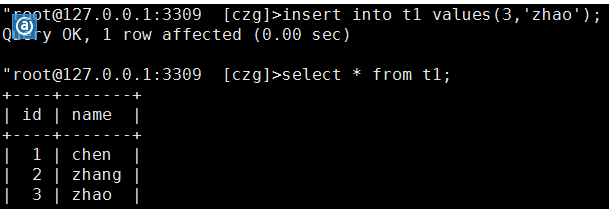
其它两台的机器也会看到新增加数据
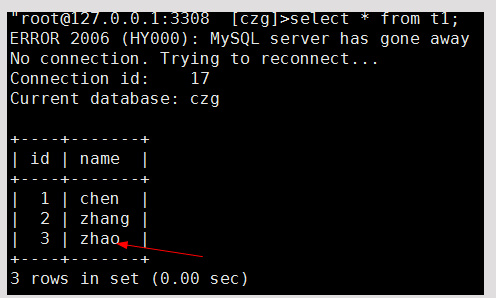
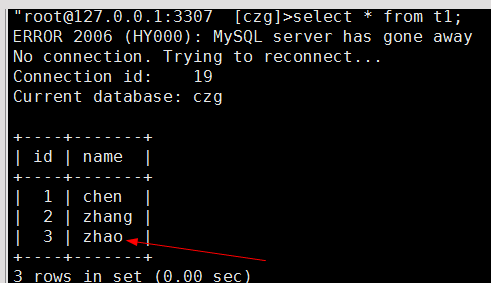
到此我们的主从环境就算搭建完成。
小结:其实环境的搭建还是比较的简单,你只要按文档说明基本能顺利的搭建下来。
注意事项:
select variable_value from performance_schema.global_status where variable_name='group_replication_primary_member';
select variable_value from performacne_schema.global_status where variable_name='group_repliation_primary_member';
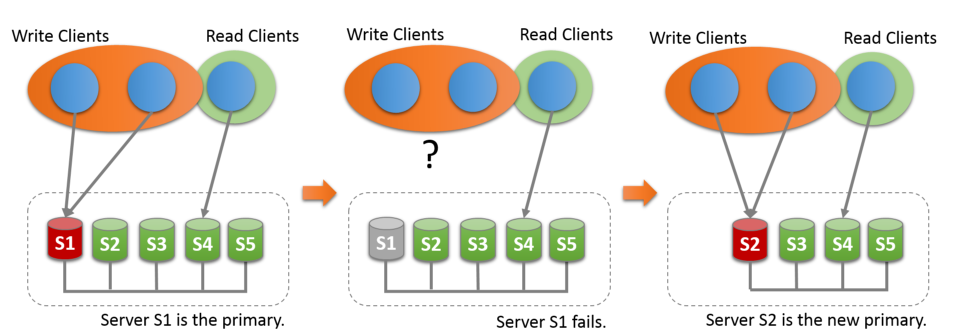
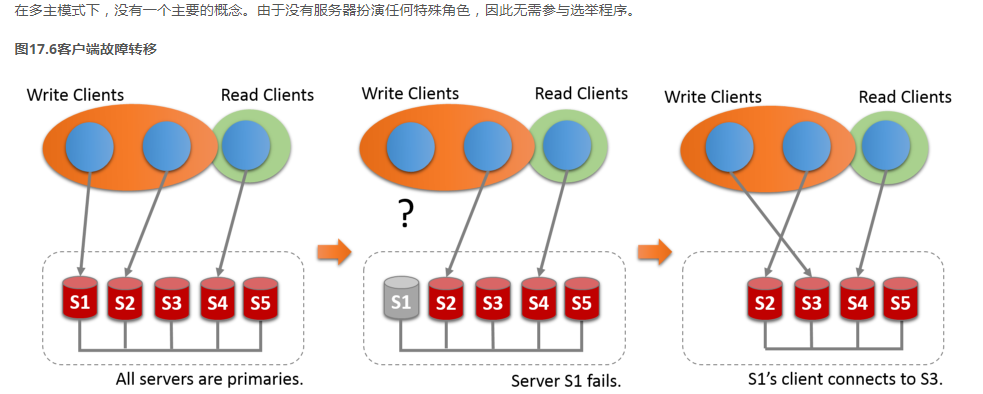
另外一个问题就是启动的问题:

看日志就是我们的端口争用。主要是我们的配置文件的时候,没有把端口设置好,设置冲突了。

总结:主从搭建的环境就写到这里,后续还会针对Group Relication 做一个详细的介绍。水平有限,文中如果有不当或者错误之处,欢迎大家拍砖给我发邮件(chenzhaoguang00@126.com)。欢迎转载,转载请注明来源即可。
MySQL Group Relication 部署环境入门篇的更多相关文章
- 使用 gulp 搭建前端环境入门篇(转载)
本文转载自: 使用 gulp 搭建前端环境入门篇
- MGR(MySQL Group Replication)部署测试
1. 环境说明 192.168.11.131 mgr1 主节点 192.168.11.132 mgr2 从节点 192.168.11.133 mgr3 从节点 2. 在mgr1.mgr2.mgr3上安 ...
- 【Mysql sql inject】【入门篇】sqli-labs使用 part 4【18-20】
这几关的注入点产生位置大多在HTTP头位置处 常见的HTTP注入点产生位置为[Referer].[X-Forwarded-For].[Cookie].[X-Real-IP].[Accept-Langu ...
- 【Mysql sql inject】【入门篇】SQLi-Labs使用 part 1【01-11】
人员流动性过大一直是乙方公司痛点.虽然试用期间都有岗前学习,但老员工忙于项目无暇带新人成长,入职新人的学习基本靠自己不断摸索.期望看相关文档就可以一蹴而是不现实的.而按部就班的学习又很难短期内将知识有 ...
- 【Mysql sql inject】【入门篇】sqli-labs使用 part 3【15-17】
Less-15- Blind- Boolian Based- String 1)工具用法: sqlmap -u --batch --technique BEST 2)手工注入 时间盲注放弃用手工了 ...
- 【Mysql sql inject】【入门篇】SQLi-Labs使用 part 2【12-14】
这几关主要是考察POST形式的SQLi注入闭合 ## Less-12 - POST - Error Based- Double quotes- String ### 1)知识点 主要考察报错注入中的双 ...
- CentOS7 + Python3 + Django(rest_framework) + MySQL + nginx + uwsgi 部署 API 开发环境, 记坑篇
CentOS7 + Python3 + Django(rest_framework) + MySQL + nginx + uwsgi 部署 API 开发环境 CentOS7 + Python3 + D ...
- Hadoop生态圈-Hive快速入门篇之Hive环境搭建
Hadoop生态圈-Hive快速入门篇之Hive环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据仓库(理论性知识大多摘自百度百科) 1>.什么是数据仓库 数据 ...
- MySQL 5.7.17 Group Relication(组复制)搭建手册【转】
本博文介绍了Group Replication的两种工作模式的架构.并详细介绍了Single-Master Mode的部署过程,以及如何切换到Multi-Master Mode.当然,文末给出了Gro ...
随机推荐
- Topshelf 一个简化Windows服务开发的宿主服务框架
Topshelf是 基于.net框架开发的宿主服务框架.该框架简化了服务的创建,开发人员只需要使用 Topshelf编写一个控制台程序,就能安装为Windows服务.之所以这样原因非常简单:调试一个控 ...
- TCP 连接关闭及TIME_WAIT探究
这里主要记录一下TCP连接在关闭的时刻,有哪些细节问题.方便在以后的程序设计中能够注意这些细节, 以避免出现这些错误.首先我们来看一下TCP的状态转换图.如<unix网络编程>卷一所示如下 ...
- Linux shell 基础
目录 一.shell脚本的基本使用 1.语言规范 2.变量 3.重定向(>,>>) 二.运算符和常用判断 1.比较运算符 2.逻辑运算符 3.常用判断 三.程序结构 1.分支(if语 ...
- 基于I2C总线的MPU6050学习笔记
MPU6050学习笔记 1. 简述 一直想自己做个四轴飞行器,却无从下手,终于狠下决心,拿出尘封已久的MPU6050模块,开始摸索着数据手册分析,一步一步地实现了MPU6050模块的功能,从MPU60 ...
- 使用kafka connect,将数据批量写到hdfs完整过程
版权声明:本文为博主原创文章,未经博主允许不得转载 本文是基于hadoop 2.7.1,以及kafka 0.11.0.0.kafka-connect是以单节点模式运行,即standalone. 首先, ...
- Eclipse项目出现红色叹号的解决办法
以前的项目今天打开突然出现了红色的叹号,对于强迫症的患者简直忍不了,出现红色叹号的原因都是jar包出现问题导致的,如果是代码错误早就是一个大红叉了- 打开项目就可以发现,找不到哪里出问题了,代码和js ...
- JAVA 新手注意事项
1. System.exit(0); 强行关闭虚拟机 2. System.out.println("*") 输出一个*并换行 (没后面的ln表 ...
- 笔记:Maven 项目目录结构
Maven提倡使用一个共同的标准目录结构,使开发人员能在熟悉了一个Maven工程后,对其他的Maven工程也能清晰了解.这样做也省去了很多设置的麻烦,以下的文档介绍是Maven希望的目录结构,并且也是 ...
- 1833 深坑 TLE 求解
题目描述: 大家知道,给出正整数n,则1到n这n个数可以构成n!种排列,把这些排列按照从小到大的顺序(字典顺序)列出,如n=3时,列出1 2 3,1 3 2,2 1 3,2 3 1,3 1 2,3 2 ...
- Redis 事务相关
1. Redis服务端是个单线程的架构,不同的Client虽然看似可以同时保持连接,但发出去的命令是序列化执行的,这在通常的数据库理论下是最高级别的隔离2. 用MULTI/EXEC 来把多个命令组装成 ...