【大数据安全】Apache Kylin 安全配置(Kerberos)
1. 概述
本文首先会简单介绍Kylin的安装配置,然后介绍启用Kerberos的CDH集群中如何部署及使用Kylin。
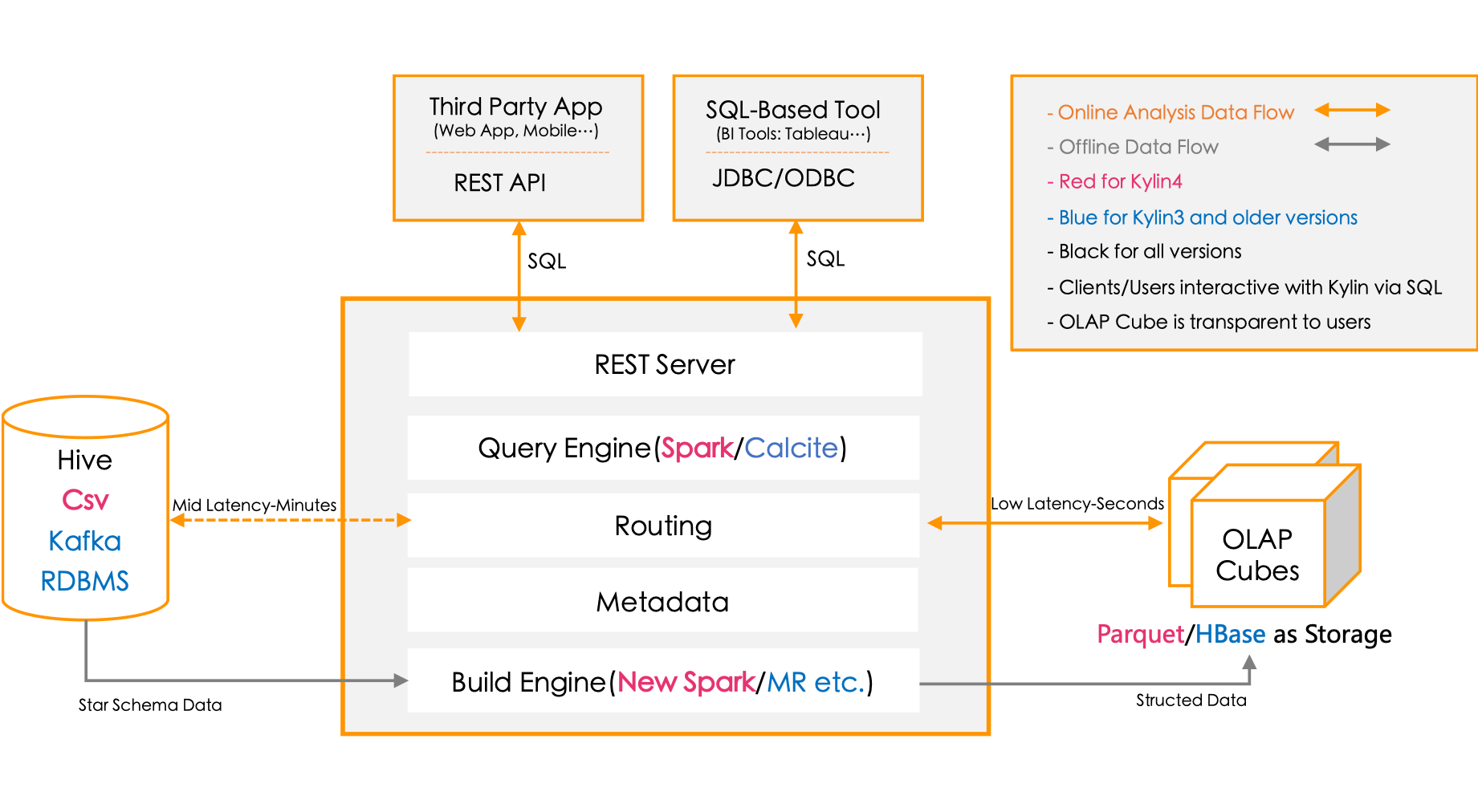
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
1.2 环境说明
- CDH版本:5.11.2
- Linux版本:7.4.1708
- Docker版本:Docker version 18.06.0-ce
- JDK版本:1.8
- 操作用户:root
2.Kylin安装配置
2.1 安装
此处以Kylin 2.0.0版本为例。
社区版Kylin地址:https://archive.apache.org/dist/kylin/
[root@node-3 ~]# cd /usr/local/src/
[root@node-3 src]# wget https://archive.apache.org/dist/kylin/apache-kylin-2.0.0/apache-kylin-2.0.0-bin-cdh57.tar.gz
[root@node-3 src]# tar xf apache-kylin-2.0.0-bin-cdh57.tar.gz
[root@node-3 src]# cp -a apache-kylin-2.0.0-bin /usr/local/
[root@node-3 src]# ln -s /usr/local/apache-kylin-2.0.0-bin /usr/local/kylin
2.2 环境配置
export BASE_PATH_BIG=/opt/cloudera/parcels/CDH/lib
#added by Hbase
export HBASE_HOME=$BASE_PATH_BIG/hbase
#added by HCat
export HCAT_HOME=/opt/cloudera/parcels/CDH/lib/hive-hcatalog/share/hcatalog
#added by Kylin
export KYLIN_HOME=/usr/local/kylin
export PATH=$HBASE_HOME/bin:$PATH
然后执行source /etc/profile生效。
2.3 Kylin配置
编辑/usr/local/kylin/conf/kylin.properites文件,新增以下配置:
Kylin2.0+版本配置的名称有变化,具体参考:https://github.com/apache/kylin/blob/2.0.x/core-common/src/main/resources/kylin-backward-compatibility.properties
## 修改配置(替换地址)
kylin.rest.servers=192.168.100.102:7070
## 新增配置
kylin.job.jar=/usr/local/apache-kylin-2.0.0-bin/lib/kylin-job-2.0.0.jar
kylin.coprocessor.local.jar=/usr/local/apache-kylin-2.0.0-bin/lib/kylin-coprocessor-2.0.0.jar
## 替换地址
kylin.job.yarn.app.rest.check.status.url=http://cdh-node-2:8088/ws/v1/cluster/apps/${job_id}?anonymous=true
kylin.job.mr.lib.dir=/opt/cloudera/parcels/CDH-5.11.2-1.cdh5.11.2.p0.4/lib/sentry/lib
配置说明:
kylin.rest.servers:kylin实例服务器列表,注意:不包括以job模式运行的服务器实例!kylin.job.jar:MR jobs依赖kylin.coprocessor.local.jar:Hbase协同处理依赖,用于提高性能。kylin.job.yarn.app.rest.check.status.url:yarn工作区kylin.job.mr.lib.dir:Hive/Hbase依赖目录。(在没有安装Hive/Hbase的节点上构建Cube会因为找不到依赖报ClassNotFoundException错误,需要此配置。具体参考这边博文《上传Kylin MR依赖》)。
更多配置请参考官网配置指南。
2.4 创建用户
在每个节点创建Kylin用户
useradd kylin
3. Kerberos配置
3.1 创建kylin账号
在Kerberos server上创建kylin账号:
[root@cdh-node-1 /]# kadmin.local
Authenticating as principal admin/admin@HWINFO.COM with password.
kadmin.local: addprinc kylin
WARNING: no policy specified for kylin@HWINFO.COM; defaulting to no policy
Enter password for principal "kylin@HWINFO.COM":
Re-enter password for principal "kylin@HWINFO.COM":
add_principal: Principal or policy already exists while creating "kylin@HWINFO.COM".
kadmin.local:
3.2 生成keytab文件
生成kylin账号keytab文件:
xst -norandkey -k klin.keytab kylin@HWINFO.COM
将kylin.keytab复制到每个kylin节点上。
3.3 定时刷新kt
在kylin节点上配置定时任务进行kinit命令:
kinit -k -t /root/kylin.keytab kylin@HWINFO.COM
添加定时任务,这里设置每天凌晨1点执行一次,可根据kerberos的过期时间自己配置。
- 编写shell脚本:
[root@cdh-node-2 security]# cat init_kt.sh
#!/bin/bash
kinit -kt ./kylin.keytab kylin@HWINFO.COM
- 添加定时任务:
[root@cdh-node-2 security]# crontab -e
# 添加以下内容
0 1 * * * root /home/security/init_kt.sh > /tmp/kylin-ktinit.log 2>&1
# 查看定时任务
[root@cdh-node-2 security]# crontab -l
0 1 * * * root /home/security/init_kt.sh > /tmp/kylin-ktinit.log 2>&1
3.4 添加Hive权限
- 登录Hive
使用拥有操作hive权限的kerberos账户登录beeline:
[root@cdh-node-3 hive]# beeline -u 'jdbc:hive2://cdh-node-3:10000/default;principal=hive/cdh-node-3@HWINFO.COM'
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
scan complete in 2ms
Connecting to jdbc:hive2://cdh-node-3:10000/default;principal=hive/cdh-node-3@HWINFO.COM
Connected to: Apache Hive (version 1.1.0-cdh5.11.2)
Driver: Hive JDBC (version 1.1.0-cdh5.11.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.1.0-cdh5.11.2 by Apache Hive
0: jdbc:hive2://cdh-node-3:10000/default>
- 添加kylin权限
将admin角色权限赋予kylin:
0: jdbc:hive2://cdh-node-3:10000/default> grant role admin to user kylin;
INFO : Compiling command(queryId=hive_20180914174141_6359e1a1-251f-4116-b646-0aa9f55dcfa8): grant role admin to user leili
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hive_20180914174141_6359e1a1-251f-4116-b646-0aa9f55dcfa8); Time taken: 0.069 seconds
INFO : Executing command(queryId=hive_20180914174141_6359e1a1-251f-4116-b646-0aa9f55dcfa8): grant role admin to user leili
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20180914174141_6359e1a1-251f-4116-b646-0aa9f55dcfa8); Time taken: 0.331 seconds
INFO : OK
No rows affected (0.528 seconds)
3.5 添加Hbase权限
使用拥有操作hbase权限的kerberos账户登录hbase shell:
[root@cdh-node-3 hive]# hbase shell
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
18/09/14 17:44:40 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.0-cdh5.11.2, rUnknown, Fri Aug 18 14:09:37 PDT 2017
- 给kylin用户授权
base(main):001:0> grant 'kylin','RWXCA'
0 row(s) in 0.5830 seconds
切换到kylin用户重新登录hbase shell,测试一下:
hbase(main):001:0> whoami
kylin@HWINFO.COM (auth:KERBEROS)
groups: kylin
hbase(main):002:0> create 'test', 'cf'
0 row(s) in 2.6930 seconds
=> Hbase::Table - test
hbase(main):003:0> list
TABLE
test
1 row(s) in 0.0310 seconds
3.6 执行Kylin检查
[root@cdh-node-2 bin]# ./check-env.sh
Retrieving hadoop conf dir...
KYLIN_HOME is set to /usr/local/apache-kylin-2.0.0-bin
3.7 启动kylin服务
先确认主机使用kerberos凭据为kylin,再启动:
[root@cdh-node-2 bin]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: kylin@HWINFO.COM
Valid starting Expires Service principal
09/14/2018 17:48:28 09/15/2018 17:48:28 krbtgt/HWINFO.COM@HWINFO.COM
renew until 09/21/2018 17:48:28
[root@cdh-node-2 bin]# ./kylin.sh start
Retrieving hadoop conf dir...
KYLIN_HOME is set to /usr/local/kylin
Retrieving hive dependency...
Retrieving hbase dependency...
Retrieving hadoop conf dir...
Retrieving kafka dependency...
Retrieving Spark dependency...
KYLIN_JVM_SETTINGS is -Xms1024M -Xmx4096M -Xss1024K -XX:MaxPermSize=128M -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/usr/local/kylin/logs/kylin.gc.3982 -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64M
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /usr/local/kylin/logs/kylin.log
Web UI is at http://<hostname>:7070/kylin
4. 使用Kylin Sample测试
Kylin本身自带了一个测试例子,创建流程如下:
执行sample.sh脚本,这个主要是创建kylin的project、model、cube以及相关的hive表等。
[root@cdh-node-2 bin]# ./sample.sh
Retrieving hadoop conf dir...
Retrieving hadoop conf dir...
KYLIN_HOME is set to /usr/local/kylin
Loading sample data into HDFS tmp path: /tmp/kylin/sample_cube/d
...
Sample cube is created successfully in project 'learn_kylin'.
Restart Kylin server or reload the metadata from web UI to see the change.
进入Kylin Web界面system - reload metadata
然后构建示例的cube,如果构建成功,并且能成功执行查询命令,则表示整个配置全部完成。
[1] Cloudera Configuring Authentication Doc:
https://www.cloudera.com/documentation/enterprise/5-11-x/topics/sg_authentication.html
[2] Kylin官网配置指南:
http://kylin.apache.org/cn/docs/install/configuration.html
[3] Linux下的crontab定时执行任务命令详解:
https://www.cnblogs.com/longjshz/p/5779215.html
【大数据安全】Apache Kylin 安全配置(Kerberos)的更多相关文章
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- Apache Kylin大数据分析平台的演进
转:http://mt.sohu.com/20160628/n456602429.shtml 我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO.今天我主要来和大家分享一下 ...
- Apache Kylin在4399大数据平台的应用
来自:AI前线(微信号:ai-front),作者:林兴财,编辑:Natalie作者介绍:林兴财,毕业于厦门大学计算机科学与技术专业.有多年的嵌入式开发.系统运维经验,现就职于四三九九网络股份有限公司, ...
- 【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:[技术帖]Apache Kylin 2.0为大数据带来交互式的BI 编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲. 基于Hadoop的SQL一直在被 ...
随机推荐
- BZOJ_1196_[HNOI2006]公路修建问题_kruskal+二分答案
BZOJ_1196_[HNOI2006]公路修建问题_kruskal+二分答案 题意:http://www.lydsy.com/JudgeOnline/problem.php?id=1196 分析: ...
- YAML基础教程
一.YAML介绍YAML参考了其他多种语言,包括:XML.C语言.Python.Perl以及电子邮件格式RFC2822.Clark Evans在2001年5月在首次发表了这种语言,另外Ingy döt ...
- DDD「领域驱动设计」分层架构初探
前言 基于 DDD 传统分层架构实现. 项目 github地址:https://github.com/WuMortal/DDDSample 这个分层架构是工作中项目正在使用的分层架构,使用了一段时间发 ...
- .NetCore WebApi——基于JWT的简单身份认证与授权(Swagger)
上接:.NetCore WebApi——Swagger简单配置 任何项目都有权限这一关键部分.比如我们有许多接口.有的接口允许任何人访问,另有一些接口需要认证身份之后才可以访问:以保证重要数据不会泄露 ...
- 微服务架构 - CentOS7离线部署docker
1.环境准备 系统环境为: CentOS Linux release 7.5.1804 (Core) 安装docker版本为: 17.12.0-ce 2.准备部署文件 在http://mirrors. ...
- solr 学习笔记1
创建核心(帮助: solr create_core -help) 例子: solr create_core -c mjj_core -d /var/solr/mjj_config (-c 是核心名称 ...
- 纯css折叠区域-基于checkbox
Accordion Accordion即可折叠区域,和<details>标签类似,不过更灵活些.折叠区域往常多用JavaScript实现,这里就纯粹用CSS,就想法上也是异途同归. 折叠区 ...
- dagger2的初次使用
一.使用前准备 1.打开app的build.gradle文件: 顶部停用apt插件: //添加如下代码,应用apt插件 apply plugin: 'com.neenbedankt.android-a ...
- Android组件化开发的简单应用
组件化开发的主要步骤: 一.新建Modules 1.新建Project,作为应用的主Module. 2.新建Module:"Common",类型选择"Android Li ...
- WPF软件开发系统之三——自助购票取票、自助选座系统
本系统使用.Net WPF开发,运行于Windows操作系统,电脑或者触摸屏设备(包括竖屏). 本系统开发背景:景点.影院.或商场的自助购票.取票系统. 图书馆.自习室的选座.占座系统. 功能包括:选 ...