只有一百行的xss扫描工具——DSXS源码分析
0x00 废话
DSXS是一个只有一百行代码的xss扫描器,其作者刚好就是写sqlmap的那位,下面来看一下其扫描逻辑。0x01部分文字较多,感觉写的有点啰嗦,如果看不下去的话就直接看最后的0x02的总结部分。
0x01 扫描逻辑
程序有两个非并行的逻辑,第一个逻辑是检测dom型xss,第二个逻辑是检测经过后端的xss。在执行两个逻辑之前,程序会先判断目标路径上是否有参数值为空的情况,有则赋为1,比如:baidu.com/?id=99&name=&age=转换成baidu.com/?id=99&name=1&age=1。转换完成后,进入xss检测逻辑部分。
第一个逻辑:dom型xss
首先根据dom_filter_regex去掉响应包中的内容,然后在响应中查找dom_patterns,如果存在,则提示可能存在dom-xss
第二个逻辑:经过后端的xss
首先要知道这里有一个核心的正则表达式list,一共有九个元组,每个元组都代表输出点在dom结点中的一个确定的位置,比如:script标签内、单引号内、注释内。。然后对应每个位置,还有对应的攻击方法,比如在单引号内就需要用单引号逃逸,即单引号在响应中不能被转义,如果被转义就完了。其中每个元组有四个元素,详细看下面:
REGULAR_PATTERNS = ( # each (regular pattern) item consists of (r"context regex", (prerequisite unfiltered characters), "info text", r"content removal regex") # 格式(匹配有可能存在xss的字符串的正则,攻击成功需要哪些字符未经过滤,说明(简易表达匹配格式),获取响应包后首先筛掉的字符的regexp)
(r"\A[^<>]*%(chars)s[^<>]*\Z", ('<', '>'), "\".xss.\", pure text response, %(filtering)s filtering", None),
(r"<!--[^>]*%(chars)s|%(chars)s[^<]*-->", ('<', '>'), "\"<!--.'.xss.'.-->\", inside the comment, %(filtering)s filtering", None),
(r"(?s)<script[^>]*>[^<]*?'[^<']*%(chars)s|%(chars)s[^<']*'[^<]*</script>", ('\'', ';'), "\"<script>.'.xss.'.</script>\", enclosed by <script> tags, inside single-quotes, %(filtering)s filtering", r"\\'"),
(r'(?s)<script[^>]*>[^<]*?"[^<"]*%(chars)s|%(chars)s[^<"]*"[^<]*</script>', ('"', ';'), "'<script>.\".xss.\".</script>', enclosed by <script> tags, inside double-quotes, %(filtering)s filtering", r'\\"'),
(r"(?s)<script[^>]*>[^<]*?%(chars)s|%(chars)s[^<]*</script>", (';',), "\"<script>.xss.</script>\", enclosed by <script> tags, %(filtering)s filtering", None),
(r">[^<]*%(chars)s[^<]*(<|\Z)", ('<', '>'), "\">.xss.<\", outside of tags, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->"),
(r"<[^>]*=\s*'[^>']*%(chars)s[^>']*'[^>]*>", ('\'',), "\"<.'.xss.'.>\", inside the tag, inside single-quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|\\"),
(r'<[^>]*=\s*"[^>"]*%(chars)s[^>"]*"[^>]*>', ('"',), "'<.\".xss.\".>', inside the tag, inside double-quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|\\"),
(r"<[^>]*%(chars)s[^>]*>", (), "\"<.xss.>\", inside the tag, outside of quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|=\s*'[^']*'|=\s*\"[^\"]*\""),
)
人话版如下:
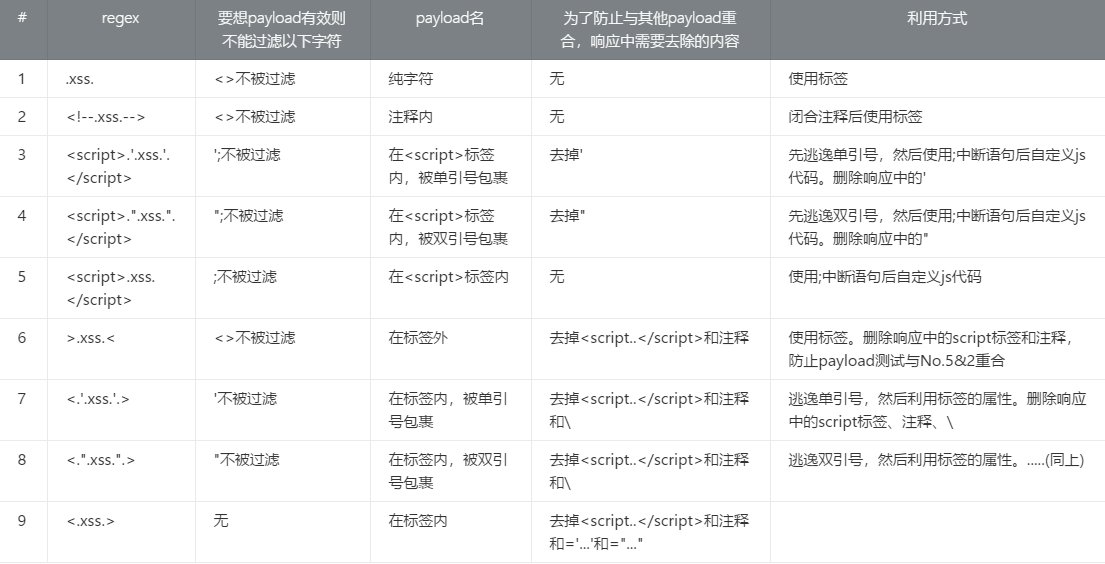
这个表说了,下面说一下检测的大体流程。首先是发送payload,然后查找payload的输出点,接着再看这个输出点对应上边表中的哪个位置。找到对应的位置之后再看如果在这个位置要利用成功需要哪些字符不被转义,然后在响应中查找payload,确定payload中‘不可被转义的特殊字符’前是否被加上了反斜杠\,如果有则认为被转义,并继续往下找,直到每个不可被转义的字符至少在响应中未被转义地出现了一次,才会认为存在漏洞。
下面根据代码说一下。
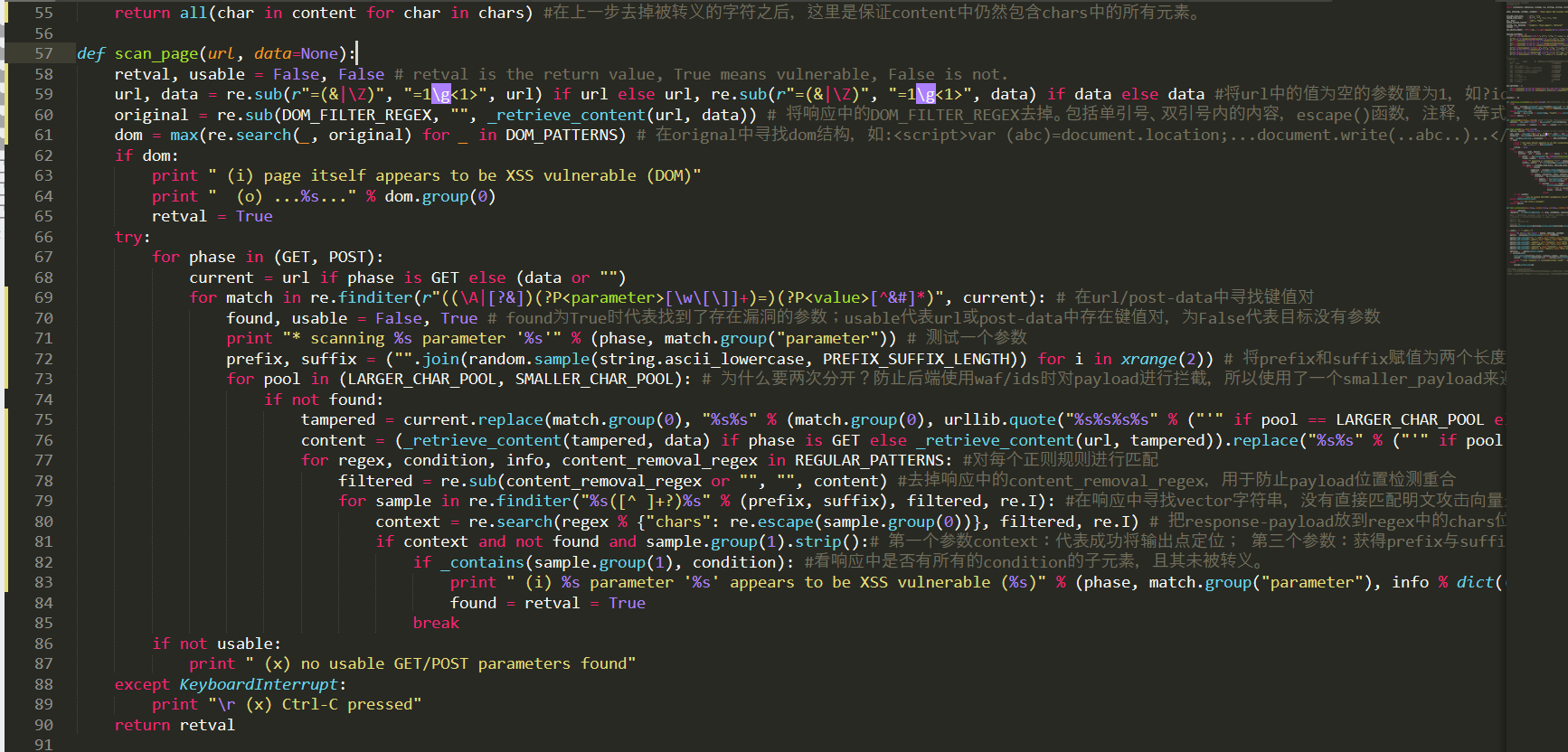
62-65行是dom-xss检测,是属于上面的第一个逻辑,这里就不再展开。从67行往下看,首先是分别进行GET和POST请求,然后到了69行。
这里在url和post-data中查找键值对(参数)的位置,然后对每个参数进行以下的测试。
从72行可以看到,首先赋值两个长度为5的随机字符的字符串:prefix和suffix
然后使用一个for循环,针对larger_char_pool和smaller_char_pool进行单独的测试(这两个list分别是:(''', '"', '>', '<', ';') 和('<', '>')。之所以要用两个list的原因是防止后端使用waf/ids时对payload进行拦截,所以使用了一个smaller_payload来避免过于明显的payload[即有较少的特殊字符]) 。
进入75行,这里先构造payload,payload格式为prefix+pool中所有字符的随机排序+suffix,如果这个pool是larger_char_pool,则这里在payload之前加一个单引号'原因如下:
1) .试图触发xss
2) .故意构造一个错误的sql语句用于报错,试图在报错信息中寻找触发点
这里暂且把prefix与suffix中间的部分称为vector。构造完payload之后直接发送,然后获取返回内容。如果这个pool是larger_char_pool,那么这里就要去掉prefix之前的单引号',这个单引号的作用刚刚已经说了,至此已经完成了它的使命,这里自然要从响应中去掉,防止干扰。
然后到77行,下面开始使用regular_patterns对相应内容进行测试,首先根据content_removal_regex去掉响应中的内容(因为payload有重合部分,所以要通过这种方式来避免重合的检测,即表中每个元组的第四个元素),然后在响应中寻找(prefix+...+suffix) [注:这里的规则大致是prefix.*suffix,不指定中间的部分为vector,因为vector有可能被后端转义掉了],暂时称之为response-payload。
如果可以找到,就说明这个参数的值是会被输出到响应中的(先不管有没有过滤),下面的逻辑就要检测这个参数是否可以利用。首先需要确定response-payload的输出点在哪个位置(script标签内?注释内?引号内?等等,详见REGULAR_PATTERNS),然后再根据输出点来确定在这个位置利用成功需要哪些字符不被过滤。
ok,逻辑大概理清楚了,下面是程序的实现。首先是输出点定位,在第80行,程序将response-payload插入到regular_patterns的regex(每个元组的第一个元素)中的chars位置,如果可以在响应中匹配到regex,就说明定位成功。然后下一步就是检查字符过滤情况,程序通过在82行调用_contains函数来确定“不可被过滤的字符”在响应中是否被过滤(即判断这些字符前是否有反斜杠\),对prefix和suffix中vector位置的字符串进行检测,_contains代码如下:
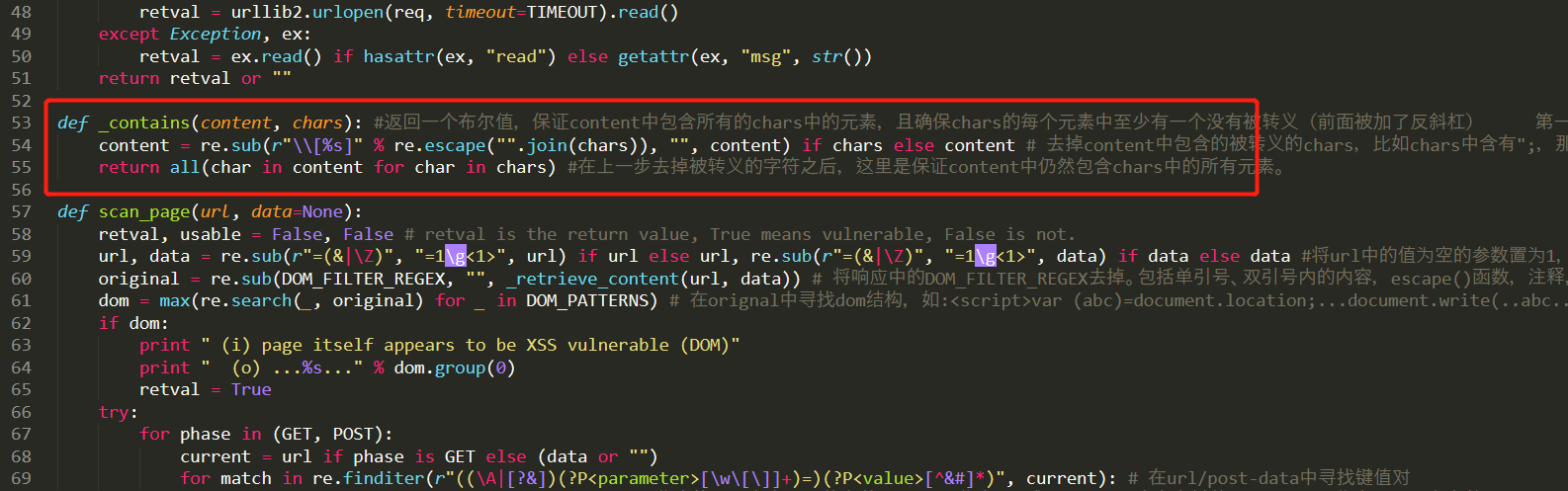
这里如果没有被过滤,这认为可能存在漏洞。
0x02 总结
至此,这个代码分析结束。来个总结,dom xss的检测方法就是通过正则表达式来对一些有可能造成危害的函数进行匹配,并且匹配其参数是否可控。至于经过后端型xss,这里先是通过正则判断输出点在dom树中的位置,然后确定如果想要触发xss需要哪些字符不被过滤,接着再根据响应包中的payload中的特殊字符前是否有反斜杠来确定其是否被过滤从而确定是否满足上面的条件,满足则存在漏洞。
只有一百行的xss扫描工具——DSXS源码分析的更多相关文章
- 并发工具CyclicBarrier源码分析及应用
本文首发于微信公众号[猿灯塔],转载引用请说明出处 今天呢!灯塔君跟大家讲: 并发工具CyclicBarrier源码分析及应用 一.CyclicBarrier简介 1.简介 CyclicBarri ...
- [软件测试]网站压测工具Webbench源码分析
一.我与webbench二三事 Webbench是一个在linux下使用的非常简单的网站压测工具.它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的性能.Webbench ...
- bootstrap_栅格系统_响应式工具_源码分析
-----------------------------------------------------------------------------margin 为负 使盒子重叠 等高 等高 ...
- 网站(Web)压测工具Webbench源码分析
一.我与webbench二三事 Webbench是一个在linux下使用的非常简单的网站压测工具.它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的性能.Webbench ...
- 云实例初始化工具cloud-init源码分析
源码分析 代码结构 cloud-init的代码结构如下: cloud-init ├── bash_completion # bash自动补全文件 │ └── cloud-init ├── Chan ...
- 并发工具CountDownLatch源码分析
CountDownLatch的作用类似于Thread.join()方法,但比join()更加灵活.它可以等待多个线程(取决于实例化时声明的数量)都达到预期状态或者完成工作以后,通知其他正在等待的线程继 ...
- 多渠道打包工具Walle源码分析
一.背景 首先了解多渠道打包工具Walle之前,我们需要先明确一个概念,什么是渠道包. 我们要知道在国内有无数大大小小的APP Store,每一个APP Store就是一个渠道.当我们把APP上传到A ...
- React躬行记(16)——React源码分析
React可大致分为三部分:Core.Reconciler和Renderer,在阅读源码之前,首先需要搭建测试环境,为了方便起见,本文直接采用了网友搭建好的环境,React版本是16.8.6,与最新版 ...
- Node.js躬行记(19)——KOA源码分析(上)
本次分析的KOA版本是2.13.1,它非常轻量,诸如路由.模板等功能默认都不提供,需要自己引入相关的中间件. 源码的目录结构比较简单,主要分为3部分,__tests__,lib和docs,从名称中就可 ...
随机推荐
- SVD的概念以及应用
第十四章 利用SVD简化数据 一.引言 SVD的全称是奇异值分解,SVD的作用是它能够将高维的数据空间映射到低维的数据空间,实现数据约减和去除噪声的功能. SVD的特点主要有以下几个方面: 1.它的优 ...
- Ubuntu下vim中文乱码
在linux中,用vim打开包含中文的文件时,有可能出现乱码 下面的vim配置方法亲测有效 1. 找到你的vimrc文件,也有可能是.vimrc,我的服务器是vimrc,我改的是 有的说建议不要改全局 ...
- Tomcat和JavaWeb目录和流程
Tomcat主要目录结构 bin 二进制可执行文件,包含启动和关闭tomcat文件 conf 配置文件,其中包含了server.xml.context.xml.web.xml等 webapps 存 ...
- pycharm中from xx import xx报错:Unresolved reference
出现问题:无法引用到相关的类,但是这些类确实都在工程中 分析原因:import不成功是路径没对应上,pycharm默认该项目的根目录为source目录 解决方案: 将对应的项目searchTest,选 ...
- angular5学习笔记(deep in 路由)
最近接手了一个angular5的项目.项目本身是由不同的人开发的,所有代码结构风格本身就有很大不同,加上本身接触angular5也不久,之前都是使用1,所有自身压力还是很大的. 接手前几天当然是熟悉代 ...
- dubbo实现原理简单介绍
一.什么是dubbo Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合).从服务模型的角度来看, ...
- mysql workbench EER图,里面的实线以及虚线的关系
ERWin里面线代表实体间的三种关系:决定关系(Identifying Relationship),非决定关系(None-Identifying Relationship),多对多(Many-To-M ...
- 激活IDEA 2017.3 mac版 2018.05.21亲测可用
本文激活方式不会导致IEDA打不开,可激活一年,最简便方式,只需要30秒. 1.修改hosts sudo vim /private/etc/hosts 在文件最后一行中添加: 0.0.0.0 acco ...
- web优化(二)
上次说到js的阻塞dom渲染可能出现的白屏现象,所以对于js我们需要一些优化.首先我们可以模仿通信中的时分的概念,使用 setTime()来执行一段js代码然后渲染页面然后再执行一段js代码,这样可以 ...
- ajax技术基础详解
一.概述 1.什么是ajax 可以与服务器进行[异步]交互的技术,浏览器无需刷新 2.什么时候出现ajax? -- XMLHttp 微软 1999年微软公司发布IE5版本,内嵌了ajax技术 什么时候 ...