Oracle执行计划学习笔记
最近拜读《收获,不止SQL优化》一书,并做了笔记,方便自己以后回顾,同时放在网上或许也有益于别人
一、获取执行计划的方法
(1) explain plan for
步骤:
- 1:explain plan for 你的SQL;
- 2:select * from table (dbms_xplan. display()) ;
- 优点:不需要真的执行,快捷方便
- 缺点:没有输出运行时的统计信息(逻辑读、递归调用,物理读),因为没有真正执行,所以不能看到执行了多少行、表被访问了多少次等等
(2) set autotrace on
sqlplus登录:
用户名/密码@主机名称:1521/数据库名
步骤:
- 1:set sutoatrace on
- 2:在此次执行你的sql;
- 优点:可以看到运行时的统计信息(逻辑读、递归调用,物理读)
- 缺点:不能看到表被访问了多少次,也需要等sql执行完成才能看
(3) statistics_level=all
步骤:
- 1:alter session set statistics_level=all;
- 2:在此处执行你的SQL;
- 3:select * from table(dbms_xplan.display_cursor(null , null,'allstats last'));
假如使用了Hint语法: /*+ gather_plan_statistics */,就可以省略步骤1,直接执行步骤2和3,获取执行计划
关键字解读:
- Starts:该SQL执行的次数
- E-Rows:为执行计划预计的行数
- A-Rows:实际返回的行数,E-Rows和A-Rows作比较,就可以看出具体那一步执行计划出问题了
- A-Time:每一步实际执行的时间,可以看出耗时的SQL
- Buffers:每一步实际执行的逻辑读或一致性读
- Reads:物理读
- OMem:当前操作完成所有内存工作区操作总使用私有内存工作区(PGA)的大小
- lMem:当工作区大小无法符满足操作需求的大小时,需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以完成操作,就称一次通过,One-Pass;否则为多次通过,Multi-Pass)。改数据为语句最后一次执行中,单次写磁盘所需要的内存大小,这个是由优化器统计数据以及前一次执行的性能数据估算得出的
- Used-Mem:语句最后一次执行中,当前操作所使用的内存工作区大小,括号里面为(发生磁盘交换的次数,1次即为One-Pass,大于一次则为Mullti-Pass,如果没有使用磁盘,则显示为OPTI1MAL)
OMem、lMem为执行所需要的内存评估值,OMem为最优执行模式所需要内存的评估值,Used-Mem为消耗的内存
优点:
- 可以从STARTS得出表被访问多少次;
- 可以清晰地从E-ROWS和A-ROWS中分别得出预测的行数和真实的行数
缺点: - 必须等到语句真正执行完成后,才可以得出结果
- 无法控制记录打屏输出,不想aututrace有traceonly命令
- 没有专门的输出统计信息,看不到递归调用的次数,看不出物理读具体数值,不过有逻辑读,逻辑读才是重点
(4) dbms_xplan.display_cursor获取
步骤
从共享池获取
//${SQL_ID}参数可以从共享池拿
select * from table(dbms_xplan.display_cursor(${SQL_ID}));
还可以从AWR性能视图里获取
select * from table(dbms_xplan.display_awr(${SQL_ID}));
多个执行计划的情况,可以用类似方法查出
select * from table(dbms_xplan.display_cursor(${SQL_ID},0));
select * from table(dbms_xplan.display_cursor(${SQL_ID},1));
优点:
- 和explain一样不需要真正执行,知道sql_id就好
缺点:
- 不能判断处理了多少行
- 无法判断表被访问了多少次
- 没有输出运行时的相关统计信息(逻辑读、递归调用、物理读)
(5) 事件10046 trace跟踪
步骤:
1:alter session set events '10046 trace name context forever,level 12';//开启跟踪
2:执行你的语句
3:alter session set events '10046 trace name context off';//关闭跟踪
4:找到跟踪产生的文件
5:tkprof trc文件 目标文件 sys=no sort=prsela,exeela,fchela(格式化命令)
优点:
- 可以看出SQL语句对应的等待事件
- 可以列出sql语句中的函数调用的
- 可以看出解析事件和执行事件
- 可以跟踪整个程序包
- 可以看出处理的行数,产生的逻辑读
缺点: - 步骤比较繁琐
- 无法判断表被访问了多少次
- 执行计划中的谓词部分不能清晰地显示出来
(6) awrsqrpt.sql
步骤:
1:@?/rdbms/admin/awrsqrpt.sql
具体可以参考我之前的博客:https://smilenicky.blog.csdn.net/article/details/89429989
二、解释经典执行计划的方法
可以分为两种类型:单独型和联合型
联合型分为:关联的联合型和非关联的联合型
【单独型】
单独型比较好理解,执行顺序是按照id=1,id=2,id=3执行,由远及近
先scott登录,然后执行sql,例子来自《收获,不止SQL优化》一书
select deptno, count(*)
from emp
where job = 'CLERK'
and sal < 3000
group by deptno
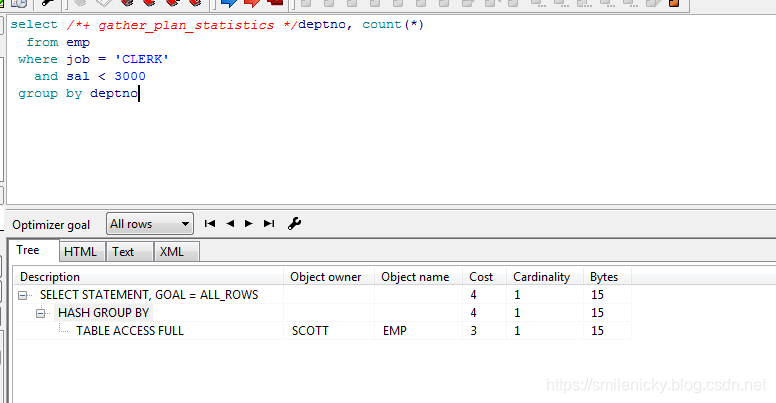
所以可以给出单独型的图例:

【联合型关联型】
(1) 联合型的关联型(NL)
这里使用Hint的nl
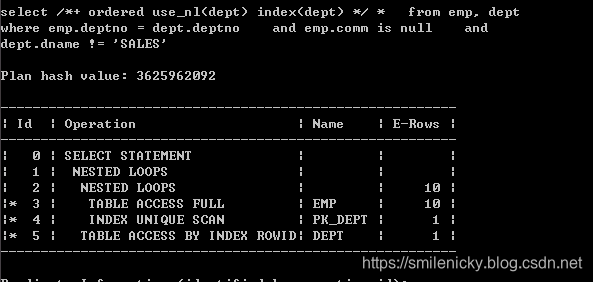
select /*+ ordered use_nl(dept) index(dept) */ *
from emp, dept
where emp.deptno = dept.deptno
and emp.comm is null
and dept.dname != 'SALES'
这图来自《收获,不止SQL优化》,可以看出id为2的A-Rows实践返回行数为10,id为3的Starts为10,说明驱动表emp访问的结果集返回多少条记录,被驱动表就被访问多少次,这是关联型的显著特征

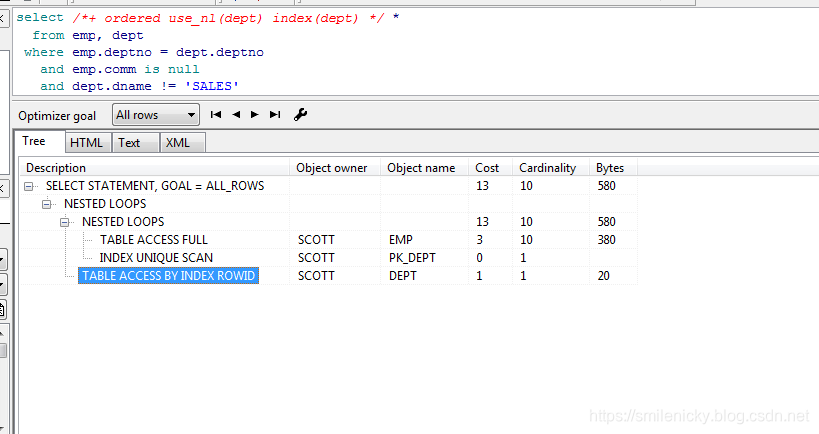
关联型不一定是驱动表返回多少条,被驱动表就被访问多少次的,注意FILTER模式也是关联型的
(2) 联合型的关联型(FILTER)
前面已经介绍了联合型关联型(nl)这种方法的,这种方法是驱动表返回多少条记录,被驱动表就被访问了多少次,不过这种情况对于FILTER模式下并不适用
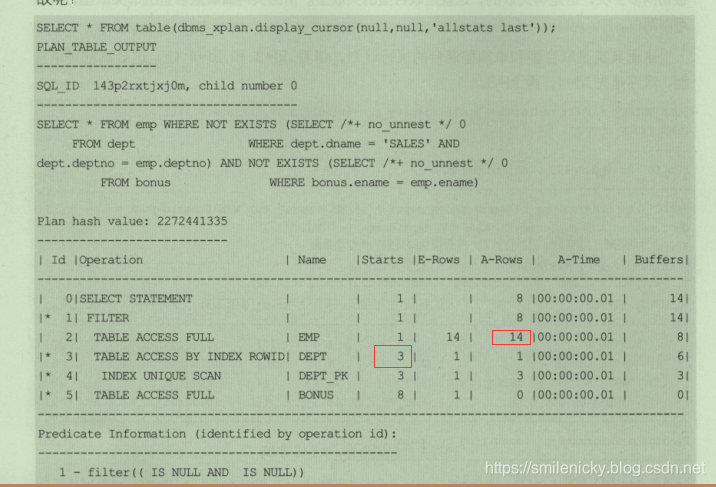
执行SQL,这里使用Hint /*+ no_unnset */
select * from emp where not exists (select /*+ no_unnset */ 0 from dept
where dept.dname='SALES' and dept.deptno = emp.deptno) and not exists(select /*+ no_unnset */ 0 from bonus where bonus.ename = emp.ename)
ps:图来自《收获,不止SQL优化》一书,这里可以看出id为2的地方,A-Rows实际返回行数为8,而id为3的地方,Starts为3,说明对应SQL执行3次,也即dept被驱动表被访问了3次,这和刚才介绍的nl方式不同,为什么不同?
 查询一下SQL,可以看出实际返回3条,其它的都是重复多的,
查询一下SQL,可以看出实际返回3条,其它的都是重复多的,
select dname, count(*) from emp, dept where emp.deptno = dept.deptno group by dname;
所以,就很明显了,被过滤了重复数据,也就是说FILTER模式的对数据进行过滤,驱动表执行结果集返回多少行不重复数据,被驱动表就被访问多少次,FILTER模式可以说是对nl模式的改善
(3) 联合型的关联型(UPDATE)
update emp e1 set sal = (select avg(sal) from emp e2 where e2.deptno = e1.deptno),comm = (select avg(comm) from emp e3)
联合型的关联型(UPDATE)和FILTER模式类似,所以就不重复介绍
(4) 联合型的关联型(CONNECT BY WITH FILTERING)
select /*+ connect_by_filtering */ level, ename ,prior
ename as manager from emp start with mgr is null connect by prior empno = mgr
给出联合型关联型图例:

【联合型非关联型】
可以执行SQL
select ename from emp union all select dname from dept union all select '%' from dual
对于plsql可以使用工具查看执行计划,sqlplus客户端的可以使用statistics_level=all的方法获取执行计划,具体步骤
- 1:alter session set statistics_level=all;
- 2:在此处执行你的SQL;
- 3:select * from table(dbms_xplan.display_cursor(null , null,'allstats last'));
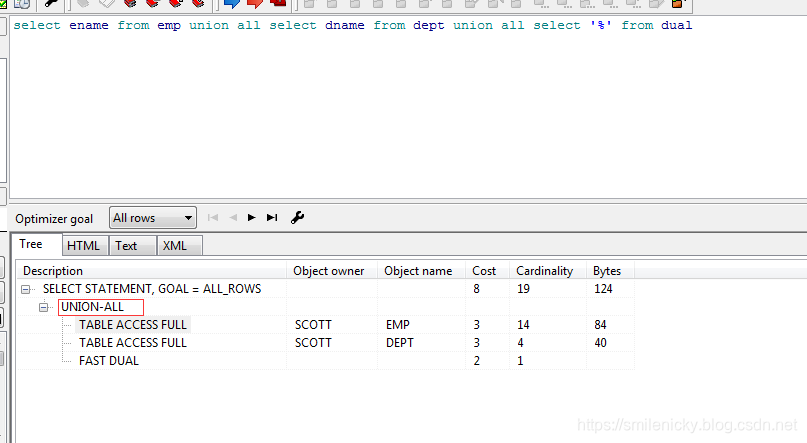
可以给出联合型非关联型的图例:

Oracle执行计划学习笔记的更多相关文章
- Oracle调优之看懂Oracle执行计划
@ 目录 1.文章写作前言简介 2.什么是执行计划? 3.怎么查看执行计划? 4.查看真实执行计划 5.看懂Oracle执行计划 5.1 查看explain 5.2 explain执行顺序 5.3 访 ...
- ORACLE 执行计划
有关oracle 执行计划几个不错的连接 执行计划的一些概念介绍:http://database.51cto.com/art/200611/34273.htm执行计划的例子:http://www.or ...
- FastJson远程命令执行漏洞学习笔记
FastJson远程命令执行漏洞学习笔记 Fastjson简介 fastjson用于将Java Bean序列化为JSON字符串,也可以从JSON字符串反序列化到JavaBean.fastjson.ja ...
- Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
- 【转】Oracle执行计划解释
Oracle执行计划解释 一.相关的概念 Rowid的概念:rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的. 对每个表都有一个rowid的伪列,但是表中并不物 ...
- 看懂Oracle执行计划
最近一直在跟Oracle打交道,从最初的一脸懵逼到现在的略有所知,也来总结一下自己最近所学,不定时更新ing- 一:什么是Oracle执行计划? 执行计划是一条查询语句在Oracle中的执行过程或访问 ...
- oracle 执行计划详解
简介: 本文全面详细介绍oracle执行计划的相关的概念,访问数据的存取方法,表之间的连接等内容. 并有总结和概述,便于理解与记忆! +++ 目录 --- 一.相关的概念 ...
- 从Count看Oracle执行计划的选择
一. 前言 在调查一个性能问题的时候,一个同事问道,为什么数据库有些时候这么不聪明,明明表上有索引,但是在执行一个简单的count的时候居然全表扫描了!难道不知道走索引更快么? 试图从最简单的coun ...
- 查看Oracle执行计划的几种方法
查看Oracle执行计划的几种方法 一.通过PL/SQL Dev工具 1.直接File->New->Explain Plan Window,在窗口中执行sql可以查看计划结果.其中,Cos ...
随机推荐
- day10_cookie&session学习笔记
一.会话概述 1.什么是会话?如同打电话. 会话可简单理解为:用户开一个浏览器,点击多个超链接,访问服务器多个web资源,然后关闭浏览器,整个过程称之为一个会话. 2.会话过程要解决的问题是什么?保持 ...
- vue UI库iview源码解析(2)
上篇问题 在上篇<iview源码解析(1)>中的index.js 入口文件的源码中有一段代码有点疑惑: /** * 在浏览器环境下默认加载组件 */ // auto install if ...
- “蝉原则”与CSS3随机多背景随机圆角等效果
一.什么是“蝉原则”? “蝉原则”,英文称作“cicada principle”,是一种让事物的重复出现符合“自然随机性”的规则,为什么这么说呢? “蝉原则”源自于北美,中国似乎并未有这样的说法,这背 ...
- js实用技巧
IIFE(立即调用函数表达式)最广泛的用途是避免污染全局作用域. 已经有很多JavaScript库和JavaScript高手正在使用这种技巧, 尤其是在最流行jQuery插件的开发者中. 你也应该把这 ...
- hashmap,hashTable concurrentHashMap 是否为线程安全,区别,如何实现的
线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多 ...
- Java多线程:线程与进程
实际上,线程和进程的区别,在学OS时必然是学习过的,所缺的不过是一些总结. 1. 进程 2. 线程 3. 进程与线程 4. 多进程与多线程对比 5. Java多进程与多线程 5.1. Java多进程 ...
- 重温《STL源码剖析》笔记 第一章
源码之前,了无秘密. --侯杰 经典的书,确实每看一遍都能重新收获一遍: 第一章:STL简介 STL的设计思维:对象的耦合性极低,复用性极高,符合开发封闭原则的程序库. STL的价值:1.带给我们一套 ...
- 初入thinkphp
花3天时间入门了php和thinkphp框架,紧接着就做了一个小后台,简单使用了thinkphp框架封装的一些类和函数. 现在来总结一下: //登陆函数 public func ...
- Flask入门之Bootstrap介绍使用和Flask-Nav快速导航栏
一.Bootstrap Bootstrap,来自 Twitter,是目前最受欢迎的前端框架. Python中,同样可以使用Bootstrap. 1. 导入Bootstrap库 from flask_b ...
- Python_eval()
''' eval()用来把任意字符串转化为Python表达式并进行求值 ''' print(eval('3+4')) #计算表达式的值 a=3 b=4 print(eval('a+b')) #这时候要 ...