词向量:part 1 WordNet、SoW、BoW、TF-IDF、Hash Trick、共现矩阵、SVD
1.基于知识的表征
如WordNet(图1-1),包含同义词集(synonym sets)和上位词(hypernyms,is a关系)。

存在的问题:
- 作为资源来说是好的,但是它失去了词间的细微差别,比如说"good"和"full"同义是需要在一定的上下文中才能成立的;
- 易错过词的新义,基本不可能时时保持up-to-date;
- 是人为分的,所以是主观的结果;
- 需要花费很多的人力去创建和调整;
- 很难计算出准确的词间相似度。
2.基于数据库的表征
2.1 词本身
2.1.1 词集模型(SoW,Set of Words)
0-1表征,参见图2.1.1-1,向量维度为数据库中总词汇数,每个词向量在其对应词处取值为1,其余处为0。

存在的问题:
因为不同词间相互正交,所以很难计算词间相似度。
2.1.2 词袋模型(BoW,Bag of Words)
除了考虑词是否出现外,词袋模型还考虑其出现次数,即每个词向量在其对应词处取值为该词在文本中出现次数,其余处为0。
但是,用词频来衡量该词的重要性是存在问题的,比如"the",其词频很高,但其实没有那么重要,所以可以使用TF-IDF特征来统计修正词频。
修正后的向量依旧存在数据稀疏的问题,大部分值为0,常使用Hash Trick进行降维。
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF(term frequency):词在当前文本中的词频;
IDF(inverse document frequency):包含该词的文本在语料库中出现频率的倒数的对数。
\(IDF(x)=log{N \over N(x)}\),其中,N是语料库中文本的总数,N(x)是语料库中包含词x的文本的总数。
常见的IDF平滑公式之一:\(IDF(x)=log{N+1 \over N(x)+1}+1\)。
最终,词x的TF-IDF值:\(TF\)-\(IDF(x)=TF(x)*IDF(x)\)。
Hash Trick
哈希函数h将第i个特征哈希到位置j,即h(i)=j,则第i个原始特征的词频数值c(i)将会累积到哈希后的第j个特征的词频数值c'(j)上,即:\(c'(j)=\sum_{i\in J;h(i)=j}c(i)\),其中J是原始特征的维度。
但这样做存在一个问题,有可能两个原始特征哈希后位置相同,导致词频累加后特征值突然变大。
为了解决这个问题,出现了hash trick的变种signed hash trick,多了一个哈希函数\({\xi}:N{\rightarrow}{\pm}1\),此时,我们有\(c'(j)=\sum_{i\in J;h(i)=j}{\xi}(i)c(i)\)。
这样做的好处是,哈希后的特征值仍然是一个无偏的估计,不会导致某些哈希位置的值过大。从实际应用中来说,由于文本特征的高稀疏性,这么做是可行的。
注意hash trick降维后的特征已经不知道其代表的特征和意义,所以其解释性不强。
2.2 结合上下文
基本思想:近义词之间常有相似的上下文邻居。
2.2.1 共现矩阵
- 基于整个文档:常给出文档的主题信息;
- 基于上下文窗口:常捕获语法、语义信息。
图2.2.1-1为基于窗口大小为1、不区分左右形成的高维稀疏词向量。
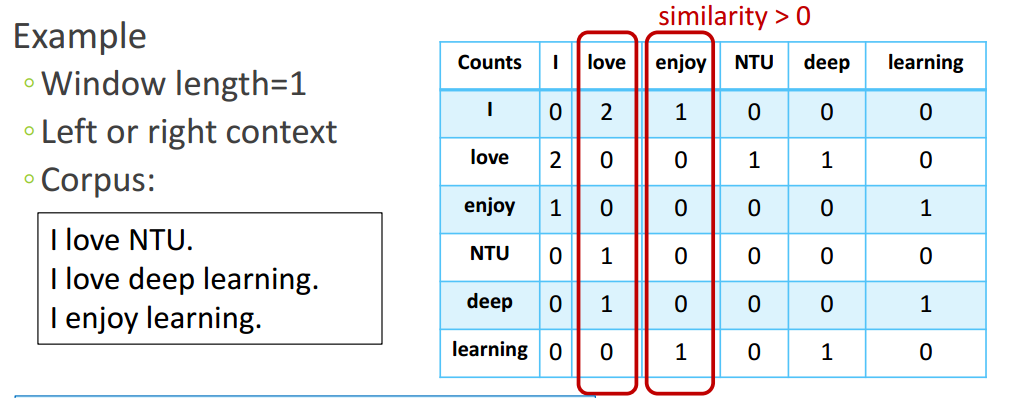
存在的问题:
- 共现矩阵的大小随着词汇量的增多而变大;
- 维度高;
- 数据稀疏带来的鲁棒性差。
2.2.2 低维稠密词向量
降维
通过对共现矩阵进行SVD,如图2.2.2-1所示。
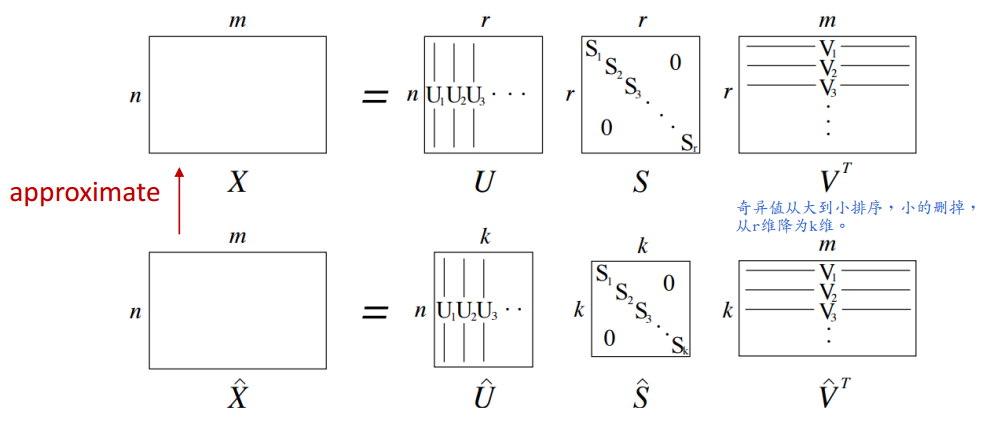
选择U的前k列得到k维词向量。
优势:
- 有效地利用了统计信息。
存在的问题:
- 难以加入新词,每次来个新词,都得更新共现矩阵,然后重新SVD;
- 由于大多数词不共现,导致矩阵十分稀疏;
- 矩阵维度通常很高(\(\approx 10^6*10^6\));
- 计算代价高,对于\(n*m\)的矩阵为\(O(nm^2)\);
- 需要对共现矩阵进行处理来面对词频上的极端不平衡现象。
常用的解决办法:
- 忽视"the"、"he"、"has"等功能词或者限制其次数不超过某个值(常100);
- 基于文档中词间距离对共现矩阵中的count进行加权处理,常窗口中离中心词越近的词分配给其的权重越大;
- 使用Pearson相关系数(\(C(X,Y)=\frac{cov(X,Y)}{\sigma(X)*\sigma(Y)}\))来代替原本的count,负数置0。
直接学
基于迭代:相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词间共现值。
- word2vec
- GloVe
词向量:part 1 WordNet、SoW、BoW、TF-IDF、Hash Trick、共现矩阵、SVD的更多相关文章
- 词表征 1:WordNet、0-1表征、共现矩阵、SVD
原文地址:https://www.jianshu.com/p/c1e4f42b78d7 一.基于知识的表征 参见图1.1,WordNet中包含同义词集(synonym sets)和上位词(hypern ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- 词向量(one-hot/SVD/NNLM/Word2Vec/GloVe)
目录 词向量简介 1. 基于one-hot编码的词向量方法 2. 统计语言模型 3. 从分布式表征到SVD分解 3.1 分布式表征(Distribution) 3.2 奇异值分解(SVD) 3.3 基 ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
自然语言处理的第一步就是获取词向量,获取词向量的方法总体可以分为两种两种,一个是基于统计方法的,一种是基于语言模型的. 1 Glove - 基于统计方法 Glove是一个典型的基于统计的获取词向量的方 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- Vim编辑器的注释,解注,删除与恢复
1. 注释: 将光标移动到注释首部 命令模式下 Ctrl+V,进入列模式 上下移动,选中待注释内容 按大写I,进入插入模式 输入 // or # 按两次退出 2 解注 将光标移动到待解注首部 命令模式 ...
- Win调整和小技巧
推荐win下一些个人爱用的工具软件(以及使用心得)和一些系统调整方法,让win下不尽人意的设置发生小小变化,让整天摸着电脑的ITer们的生活更有乐趣. 本人酷爱收集一些好用的软件,若各位也对某个或某些 ...
- JavaScript简史
JavaScript诞生于1995年. 当时的web正在日益兴起,人们对客户端语言的需求也越来越强烈.当时走在技术革新最前沿的Netscape公司决定开发一种客户端语言,用来处理简单的输入验证. 当时 ...
- geotrellis使用(三十六)瓦片入库更新图层
前言 Geotrellis 是针对大数据量栅格数据进行分布式空间计算的框架,这一点毋庸置疑,并且无论采取何种操作,其实都是先将大块的数据切割成一定大小的小数据(专业术语为瓦片),这是分治的思想,也是分 ...
- c语音-第零次作业
1.你认为大学的学习生活.同学关系.师生应该是怎样? 我认为大学学习应该以自我学习为主,由以往的被动学习改为主动学习,探索新世界,除学习专业知识外对自身欠缺的地方也应该加以补足:同学之间要互相帮助,更 ...
- python之路--day13-模块
1,什么是模块 模块就是系统功能的集合体,在python中,一个py文件就是一个模块, 例如:module.py 其中module叫做模块名 2,使用模块 2.1 import导入模块 首次带入模块发 ...
- JavaSE阶段初期的一些问题
对于如下问题1:编译阶段Demo1会报错,Demo2不会报错. class Demo1{ int i; i = 0; } class Demo2{ int i = 0; } 事实上,在java中 ...
- JAVA_SE基础——68.RunTime类
RunTime类代表Java程序的运行时环境,每一个Java程序都有一个与之对应的Runtime实例,应用程序通过该对象与运行时环境相连,应用程序不能创建自己的Runtime实例,但可以通过getRu ...
- 作业五:RE 模块模拟计算器
# !/usr/bin/env python3 # _*_coding:utf-8_*_ ''' 实现模拟计算器的功能: 公式: - * ( (- +(-/) * (-*/ + /*/* + * / ...
- api-gateway实践(07)新服务网关 - 手动发布
应用地址:http://10.110.20.191:8080/api-gateway-engine/ 一.准备工作 1.xshell登陆云主机 1.1.配置链接 1.2.链接成功 1.3.关闭防火墙 ...