SIMD---MMX代码优化
单指令多数据流,即SIMD(Single Instruction, Multiple Data)指一类能够在单个指令周期内同时处理多个数据元素的指令集,利用的是数据级并行来提高运行效率,典型的代表由Intel的MMX和SSE指令系列。这类指令的使用环境是对多个数据进行同一种处理,因此典型的应用场景就是多媒体领域,特别是在其中的编解码流程中。
1. SIMD优缺点
1.1 优点
- 效率高:单指令多数据流意味着只需要一个指令周期就能同时对多个数据进行批处理,虽然该类指令本身的指令周期可能会较一般的指令长,但是整体考虑肯定是提高了处理效率。
1.2 缺点
- 适用场景有限:并不是所有的情况都能使用SIMD,有些情况下就算能使用,也需要对原有算法进行不小的改动。
- 增大功耗和芯片面积:因为多数据流,cpu需要更大的寄存器来存储这些数据。
- 人为编写:目前编译器对SIMD的翻译有限,使用时需要开发者人为编写。
- 固定的数据元素个数:例如MMX指令,只能对1个64位、2个32位、4个16位、8个8位数据进行批量处理,其他位长的数据元素需要特殊处理。比如对6个8位元素进行处理,需要额外填充剩余的2个字节。
2. MMX指令简介
MMX指令有8个64位寄存器(MM0~MM7),但MMX实际上并没有硬件支持的新寄存器,它使用浮点寄存器来模拟MMX指令寄存器。
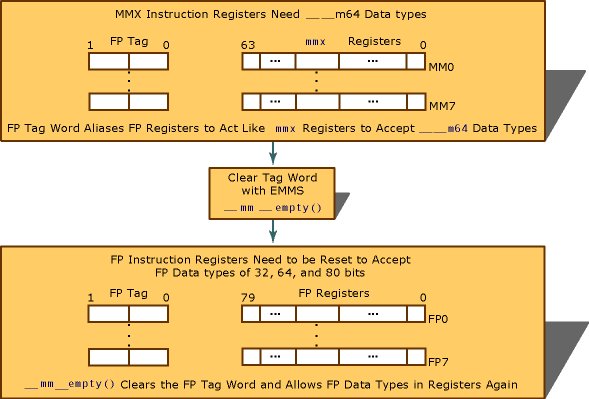
当使用MMX指令的时候,一个叫做FP(Floating Point) Tag 的Word(2字节)被用来映射浮点寄存器到MMX寄存器。这样浮点寄存器就成了MMX寄存器的容器,用来执行计算。从浮点指令切换到MMX指令实在处理器内部完成的,不需要人为的操作;相反,从MMX切换到浮点指令时,需要手动调用emms或者__mm_empty()Intrinsics。
MMX指令与x86指令类似可以分为几类,具体使用及介绍可以参考Oracle的手册,这里不再重复介绍:
- 数据传输指令
- 转换指令
- 算数指令
- 比较指令
- 逻辑运算指令
- 位移指令
- 状态管理指令
3. Intrinsics or Asm
我们可以用通常的汇编嵌入方式在C/C++代码中调用mmx指令,但是这样一来C/C++开发者可能不是很习惯,尤其是它们没有接触过汇编语言的情况下;Intel提供了另一种方式来供开发者选择----Compiler Intrinsics。
Compiler Intrinsics是内建在编译器里的函数,Intrinsics通常会以汇编代码的形式被内联到代码中且具有较高的执行效率,因为编译器知道intrinsics的表现,相比内嵌汇编代码编译器能做更多的优化。
同时,Intrinsics的使用方式是停留在宿主语言层的,所以C语言(通常情况下)相比汇编语言拥有的所有优点,Intrinsics都有(比如我可以对Intrinsics数据类型做类型单位的递增递减)。
4. 效率比较
我们这里分别简单测试C++、Intrinsics(使用MMX)、Asm(使用MMX)三种形式代码的执行效率,示例中我们分别对内存中的100 000 000个字节进行加算数运算:
4.1 C++代码
void calculateUsingCpp(char* data, unsigned size)
{
assert(size % 8 == 0);
unsigned step = 10;
for (unsigned i = 0; i < size; ++i)
{
*data++ += step;
}
}
4.2 Intrinsics代码
Intrinsics代码中,我们每次执行mmx Intrinsics时都打包8个字节的数据并执行加操作,执行完mmx指令后我们需要调用_mm_empty() Intrinsics来取消mmx指令对浮点寄存器的别名映射:
void calculateUsingIntrinsics(char* data, unsigned size)
{
assert(size % 8 == 0);
__m64 step = _mm_set_pi8(10, 10, 10, 10, 10, 10, 10, 10);
__m64* dst = reinterpret_cast<__m64*>(data);
for (unsigned i = 0; i < size; i += 8)
{
auto sum = _mm_adds_pi8(step, *dst);
*dst++ = sum;
}
_mm_empty();
}
4.3 Asm代码
Intel汇编语法在嵌入到高级语言代码中时可以直接使用上下文中的变量,这一点非常方便:
void calculateUsingAsm(char* data, unsigned size)
{
assert(size % 8 == 0);
unsigned loopCount = size / 8;
__int64 value = 0x0a0a0a0a0a0a0a0a;
__asm
{
push eax
push ecx
mov eax, data
mov ecx, loopCount
movq mm1, value
startLoop:
movq mm0, [eax]
paddb mm0, mm1
movq [eax], mm0
add eax, 8
dec ecx
jnz startLoop
emms
pop ecx
pop eax
}
}
5. 运行结果对比
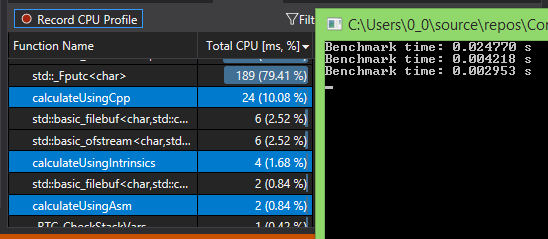
可以看出运行时间比是 8 : 1.5 : 1左右,完整代码见链接。
SIMD---MMX代码优化的更多相关文章
- Pascal编译器大全(非常难得)
http://www.pascaland.org/pascall.htm Some titles (french) : Compilateurs Pascal avec sources = compi ...
- [转]SIMD、MMX、SSE、AVX、3D Now!、NEON
转载来源<[整理]SIMD.MMX.SSE.AVX.3D Now!.neon> 本文摘取部分内容,详细请看原文. SIMD NEON是通用的SIMD(单指令多数据)引擎. 对于SISD,每 ...
- 【转】【MMX】 基于MMX指令集的程序设计简介
(一) MMX技术简介 Intel 公司的MMX™(多媒体增强指令集)技术可以大大提高应用程序对二维三维图形和图象的处理能力.Intel MMX技术可用于对大量数据和复杂数组进行的复杂处理,使用MMX ...
- .net core SIMD范例分析
单指令多数据流(SIMD)是CPU基本运算之外为了提高并行处理多条数据效率的技术,常用于多媒体处理如视频,3D模拟的计算.实现方式不同品牌的CPU各有自己的指令集,如SSE MMX 3DNOW等. C ...
- Intrinsics头文件与SIMD指令集、Visual Studio版本对应表(转)
File:Intrinsics头文件 描述:指令集描述VS:Visual Studio版本号VisualStudio:Visual Studio版本名 File 描述 VS VisualStudio ...
- emms指令在MMX指令中的作用
emms指令在MMX指令中的作用 转自:http://blog.csdn.net/psusong/archive/2009/01/08/3737047.aspx MMX和SSE都是INTEL开发的基于 ...
- 【转载】C代码优化方案
C代码优化方案 1.选择合适的算法和数据结构2.使用尽量小的数据类型3.减少运算的强度 (1)查表(游戏程序员必修课) (2)求余运算 (3)平方运算 (4)用移位实现乘除法运算 (5)避免不必要的整 ...
- SSE再学习:灵活运用SIMD指令6倍提升Sobel边缘检测的速度(4000*3000的24位图像时间由180ms降低到30ms)。
这半年多时间,基本都在折腾一些基本的优化,有很多都是十几年前的技术了,从随大流的角度来考虑,研究这些东西在很多人看来是浪费时间了,即不能赚钱,也对工作能力提升无啥帮助.可我觉得人类所谓的幸福,可以分为 ...
- PC平台的SIMD支持检测
如果我们希望在用SIMD来提升程序处理的性能,首先需要做的就是检测程序所运行的平台是否支持相应的SIMD扩展.平台对SIMD扩展分为两部分的支持: CPU对SIMD扩展的支持.SIMD扩展是随着CPU ...
随机推荐
- C++ 函数模板“偏特化”
模板是C++中很重要的一个特性,利用模板可以编写出类型无关的通用代码,极大的减少了代码量,提升工作效率.C++中包含类模板.函数模板,对于需要特殊处理的类型,可以通过特化的方式来实现特定类型 ...
- R语言-聚类与分类
一.聚类: 一般步骤: 1.选择合适的变量 2.缩放数据 3.寻找异常点 4.计算距离 5.选择聚类算法 6.采用一种或多种聚类方法 7.确定类的数目 8.获得最终聚类的解决方案 9.结果可视化 10 ...
- windows上nginx的安装和配置
http://www.cnblogs.com/Li-Cheng/p/4399149.html http://www.cnblogs.com/huayangmeng/archive/2011/06/15 ...
- SQLite常用函数及语句
SQLite3.0使用的是C的函数接口,常用函数如下: sqlite3_open() //打开数据库 sqlite3_close() //关闭数据库 sqlite3_exec() //执行sql语句, ...
- hdu 2018递推
第n月的牛的数量由第n-1个月的老牛加上n-1个月新生的小牛,得到公式F(n)=F(n-1)+F(n-3) AC代码: #include<cstdio> const int maxn=55 ...
- windows与虚拟机linux能ping通设置
作为以后参考所用. 首先,介绍如何在VMWare中设置linux的网络.一般网络选项有Bridged,NAT,host-only几种,本次以host-only作详细说明,如下图: 在选择host-on ...
- Centos安装jdk8
1.下载jdk1.8的tar cd /usr/local/src #切换到该目录下 wget url #下载jdk8的tar包 2.下载完成后解压tar包 tar -zxvf jdk-8u152-li ...
- 【转载】Ubuntu环境下安装QT(转)
Ubuntu 安装 Qt 开发环境 简单实现是本文要介绍的内容,内容很短,取其精华,详细介绍Qt 类库的说明,先来看内容. 一.Ubuntu下安装Qt $ sudo apt-get install q ...
- linux命令--ldconfig和ldd用法
一.ldconfig ldconfig是一个动态链接库管理命令,为了让动态链接库为系统所共享,还需运行动态链接库的管理命令--ldconfig. ldconfig 命令的用途,主要是在默认搜寻目录(/ ...
- php出现Can't use function return value in write context
<?php if(session('uid')){ }else{ } ?> 在用empty判断值为空的时候,报了这个Can't use function return value in w ...