[论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名。本文的主要贡献点就是使用小的卷积核(3x3)来增加网络的深度,并且可以有效提高网络的性能,而且在其他数据集上也有很好的泛化能力。
总结本文,能为网络带来比较好的方法有:
1) 加深网络的深度(网络太深,可能造成过拟合,需要小心);
2) 将较大的卷积核替换为小的卷积核,比如3x3,效果会变好,参数也会降低;
3) 使用1x1卷积,可以为网络增加非线性,某种程度上可以增加网络的性能;
4) 训练的时候,使用尺寸抖动,即对多个尺度的图像进行训练,要比只训练单尺度的图像效果要好;
5) 测试的时候,使用尺度抖动,即对多个尺度的图像进行评估,取平均值,效果比单尺度测试要好;
6) 测试的时候,使用dense 和 multi-crop方法对测试图像进行采样,效果会提升;
7) 测试的时候,使用多个模型融合,效果会变好。
下面进行详细介绍
2 卷积网络配置
为了公平的测试增加卷积层深度给网络带来的提高,所有的卷积网络层的配置都使用相同的准则。
2.1结构
训练阶段,网络的输入大小为固定尺寸的224x224的RGB图像,唯一的预处理是每个像素减去RGB均值。
这些图像经过一系列的卷积层,其中使用的非常小感受野的卷积核,大小为3x3(3x3是最小的可以感知上下左右中心的尺寸)。在一些卷积层中,我们还使用1x1的卷积核,可以看成是对输入通道的一个线性变换。
卷积步长(stride)固定设置为1,对3x3的卷积核,padding为1。
网络中的池化层采用5个最大池化(max-pooling)层,接在一些卷积层的后面(不是所有的卷积层)。Max-pooling大小为2x2,stride为2.
一系列卷积层后面跟着3个全连接层(Fully Connected layers),前2层都是4096通道,第3层是1000通道的,用来分类。最后面跟着softmax层。
所有的隐含层都使用ReLU。我们也注意到使用Local Response Normalisation (LRN) normalisation这种标准化并不能在ILSVRC数据集上提升性能,反而会导致内存消耗和增加计算时间。
2.2网络配置
每个网络配置如下表,表中A-E,每个网络的配置遵循(2.1)的说明。A网络(11层)有8个卷积层和3个全连接层,E网络(19层)有16个卷积层和3个全连接层。卷积层宽度(通道数)从64到512,每经过一次池化操作扩大一倍。虽然随着网络的深度变深,但是网络的参数数量并没有比那些浅层的使用大卷积核的网络参数要多。
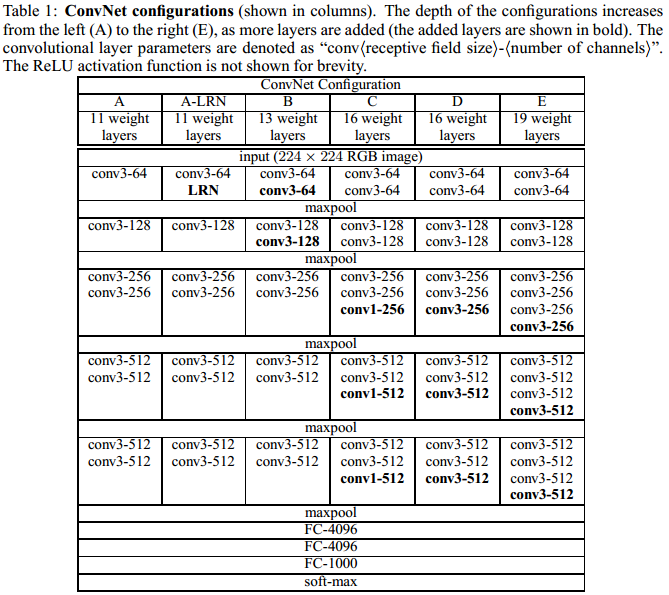
2.3 讨论
与AlexNet和ZFNet卷积层配置不同,本网络并没有在第一层使用具有大感受野的卷积核(AlexNet在第一层卷积使用11x11,stride=4的卷积核,ZFNet使用7x7,stride=2的卷积核),本文提出的网络只使用非常小的3x3,stride=1的卷积核。
可以比较容易的发现,两个3x3卷积层的串接(中间没有pooling层)与5x5卷积核拥有相同的感受野。三个连续的3x3的卷积层相当于7x7的感受野。
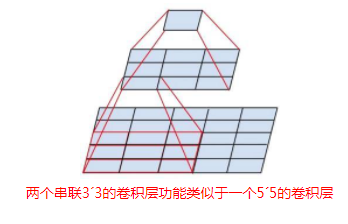
使用三个3x3卷积而不是一个7x7的卷积的优势有两点:1)包含三个ReLu层而不是一个(增加了非线性),使决策函数更有判别性;2)减少了参数。比如输入输出都是C个通道,使用3*3的3个卷积层需要3(3*3*C*C)=27*C*C,使用7*7的1个卷积层需要7*7*C*C=49C*C。这可看为是对7*7卷积施加一种正则化,使它分解为3个3*3的卷积。
增加1x1卷积核(网络C)可以在不用影响卷积层感受野的同时增加决策函数的非线性。虽然1x1的卷积操作是线性的(1x1卷积核的输入与输出大小相同),但是ReLu增加了非线性。1x1卷积核最早出现在“Network in Network”这篇文章中。
与他人工作对比:Ciresan et al.(2011)也曾用过小的卷积,但是他的网络没有VGGNet深,而且没有在大规模的ILSVRC数据集上测试。Goodfellow使用深的卷积网络(11层)做街道数字识别,表明增加卷及网络深度可以提高性能。GoogLeNet(ILSVRC-2014分类任务冠军)与VGGNet独立发展起来,同样的是也使用了很深的卷积网络(22层)和小的卷积(5*5,3*3,1*1)。
3 分类框架
下面介绍分类网络训练和评估的细节。
3.1 训练
除了对输入图像采样方法不同外,其他的训练过程与AlexNet训练过程一样。使用mini-batch gradient descent训练,Batch size为256,momentum为0.9,使用L2正则化,正则化系数为5*10^-4,在前两层全连接层设置dropout为0.5。初始学习率为0.01,然后当验证集上侧误差不变时,学习率除以10。
最后,学习率总共减少了3次,在370次迭代(74 epochs)后训练停止。对比于AlexNet,本文设计的网络深度更深,但是训练的epoch却更少,我们猜想有如下两点原因:1)更大的深度和更小的卷积带来隐式的正则化;2)一些层的预训练。
权重初始化很重要,不好的初始化可能会导致网络停止学习。为了解决这个问题,我们首先训练浅层的A网络(A网络的权重随机初始化),然后训练更深层的网络时,我们使用A网络的权重参数来初始化深层网络的前4层卷积层和后3层全连接层,其余层的权重随机初始化。权重随机初始化采用0均值,方差为0.01的正态分布,偏置(bias)初始化为0。但是后来发现,不使用浅层预训练的参数,而使用随机初始化也可以。
为了获得224x224的输入图像,它们从重新调整大小后的训练图像中随机的裁剪(每次SGD迭代,每个图像只crop一次)。为了更进一步增加训练集,从随机水平翻转和RGB颜色偏移后的图像(方法见AlexNet)中裁剪。
Training image size
令S为各向同性调整大小后的训练图像(isotropically-rescaled training image,各向同性指图像长宽缩小的比例是一样的;各向异性指的是图像的长宽都缩放至某一长度,所有如果原图像是长方形的话,缩放后的图像会有形变)的短边,对这些图像裁剪后就是网络的输入。由于裁剪大小固定为224x224,因此S可以去任意大于等于224的数值。当S>224时,crop后的图像为原图像的一小部分,可能包含一个小物体或者物体的一部分。
设置S有两种途径。第一种是固定S的大小,称为单尺度训练(single-scale training)。实验中,使用两种大小的S尺度进行训练,S=256(广泛应用于各个网络)和S=384。我们首先使用S=256训练网络,然后为了加速训练S=384的网络,我们使用S=256的网络的参数进行初始化,初始学习率为0.001。
第二种方法是多尺度训练(multi-scale training),即让S在[Smin, Smax]范围之内进行随机采样,然后将训练图像重新调整大小为S。由于图像中的物体大小是不同的,因此把这个考虑在内是很有用处的。这种方法也可以看成通过尺度抖动(scale jittering)来增强训练数据集。为了加快训练速度,我们在单尺度S=384模型的基础上进行fine-tuning。
3.2 测试
在测试阶段,给定一个已经训练好的卷积网络和一张输入图像,将按照如下方式进行分类。首先,将原图像各向同性的将短边缩放至Q大小,Q也被称为test scale。我们注意到Q与S没有必要相同,反而,对于每个S使用多个Q会提高网络性能。然后,将网络密集的应用于从重新调整大小后的测试图像中密集采样的图像(方式与Sermanet et al., 2014,overfeat,相同)。换句话说,就是将全连接层转换成卷积层(第一个全连接层转换为7x7大小的卷积层,最后两层全连接层转换成1x1的卷积层),然后将这个全卷积网络应用于整个(uncropped)图像。结果是类别分数图(其通道数量等于类的数量)和一个变化的空间大小(取决于输入图像的大小)。最后,为了获得图像的类分数的固定大小的向量,类别分数图被空间平均了(sum-pooled)。我们也通过水平翻转图像来增加测试集;将原始图像和翻转图像的soft-max分类后验概率进行平均以获得图像的最终分数。
由于将全卷积网络应用于整个图像中,因此,在测试的时候没有必要采样多个crop后的图像。(注:后面又讨论了使用多个crop后的图像进行测试,可以提高准确率)
3.3 实现细节
评估的时候使用full-size (uncropped) images at multiple scales。
使用4个NVIDIA Titan Black GPU,总共训练了2-3周。
4 分类实验
4.1 单尺度评估
当S为固定大小时,测试图像大小为Q=S;当S ∈ [Smin, Smax]时,Q = 0.5(Smin + Smax)
下图为实验结果:
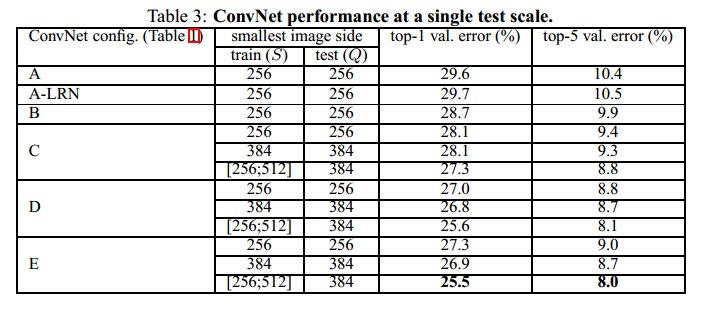
从实验结果中可以看出来:
1) 使用LRN并不会提高网络的性能
2) 网络越深,性能越好
3) 网络C比网络B性能要好,说明1x1卷积引入的非线性是有用的。
4) C与D的深度虽然是一样的,但是C的性能要比D差,说明使用具有大感受野的卷积核来获取空间内容会相对好一点。
5) 当网络深度到达19层时,错误率就饱和了,可能是更深的网络更适合用于大的数据集。
6) 另外,对于网络B,我们将两个3x3的连续卷积核替换为一个5x5的卷积核(就像前面所说的,它们具有相同的感受野),因此浅层的网络具有5个5x5的卷积核,最后这个浅层网络与B相比,错误率变高了7%,也进一步说明,一个具有小卷积核的深层网络要比一个具有大卷积核的浅层网络效果要好。
7) 最后,在训练的时候进行尺度抖动(scale jittering),可以使得测试结果更好。这也说明在训练集上通过scale jittering来增强数据集是有用的。
4.2 多尺度评估
下面评估在测试阶段使用scale jittering带来的影响。它包括在一个测试图像(对应于不同的Q值)的几个重新缩放的版本上运行一个模型,然后平均所得到的类的后验概率。考虑到如果训练图像和测试图像如果尺度差别较大的话,会导致性能的下降,因此对于固定大小的S,测试时使用3种接近S的尺寸Q={S-32,S,S+32}。对于S ∈ [Smin; Smax]的情况,Q = {Smin, 0.5(Smin + Smax), Smax}。
结果如下表:
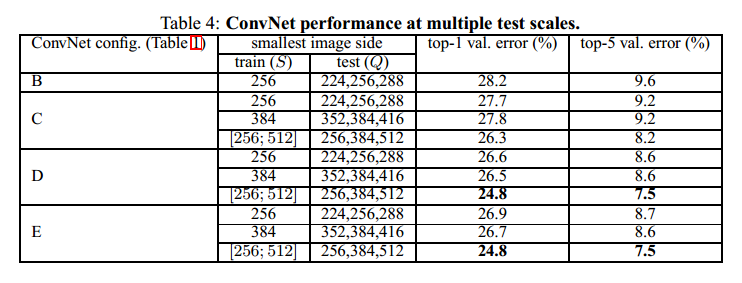
从上表中可以看出:
1) 在测试的时候尺度抖动可以提高网络性能(与Table 3相比);
2) 训练的时候,使用多尺度训练要比单尺度效果要好。
4.3 MULTI-CROP EVALUATION
下面比较mult-crop与dense采样对最后结果的影响。结果如下:
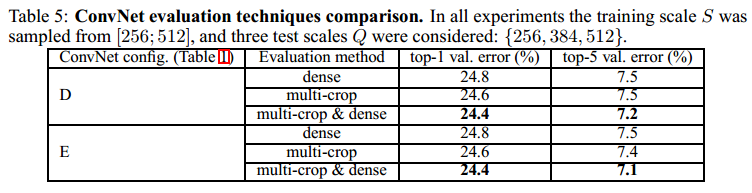
从上面的表中可以看出:
1) multi-crop效果要比dense好一些
2) multi-crop & dense效果最好
4.4 模型融合
上面讲的是对每个卷积网络模型单独测评。下面,我们结合多个模型的输出,然后去这些输出的平均值作为最后结果。结果如下表:
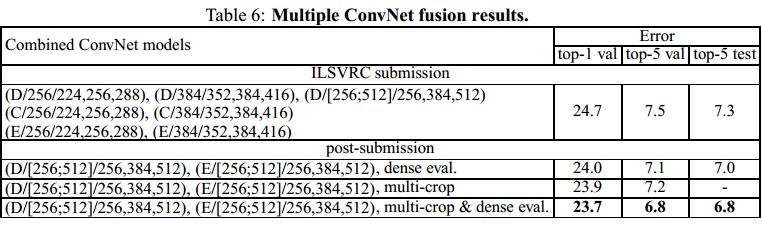
在ILSVRC submission中,使用7个网络的融合,测试集上top-5错误率为7.3。后来发现,只使用网络D和网络E的融合,效果会更好。当使用dense 和 multi-crop评估模型时,效果会进一步变好。
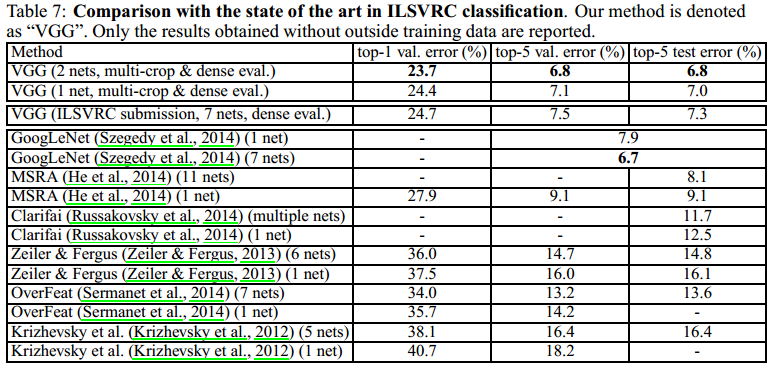
下面是本文模型与其他文章采用的模型的一个对比
总结本文,能为网络带来比较好的方法有:
1) 加深网络的深度(网络太深,可能造成过拟合,需要小心);
2) 将较大的卷积核替换为小的卷积核,比如3x3,效果会变好,参数也会降低;
3) 使用1x1卷积,可以为网络增加非线性,某种程度上可以增加网络的性能;
4) 训练的时候,使用尺寸抖动,即对多个尺度的图像进行训练,要比只训练单尺度的图像效果要好;
5) 测试的时候,使用尺度抖动,即对多个尺度的图像进行评估,取平均值,效果比单尺度测试要好;
6) 测试的时候,使用dense 和 multi-crop方法对测试图像进行采样,效果会提升;
7) 测试的时候,使用多个模型融合,效果会变好。
参考:
http://blog.csdn.net/muyiyushan/article/details/62895202
[论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)的更多相关文章
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- 目标检测论文阅读:Deformable Convolutional Networks
https://blog.csdn.net/qq_21949357/article/details/80538255 这篇论文其实读起来还是比较难懂的,主要是细节部分很需要推敲,尤其是deformab ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 论文笔记:(2019CVPR)PointConv: Deep Convolutional Networks on 3D Point Clouds
目录 摘要 一.前言 1.1直接获取3D数据的传感器 1.2为什么用3D数据 1.3目前遇到的困难 1.4现有的解决方法及存在的问题 二.本文idea 2.1 idea来源 2.2 初始思路 2.3 ...
- Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition 转载请注明:http://blog.csdn.net/stdcou ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- 《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》研读笔记
<DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks>研读笔记 论文标题:DSLR-Quality ...
- 2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
2014-VGG-<Very deep convolutional networks for large-scale image recognition>翻译 原文:http://xues ...
随机推荐
- Mycat 配置说明(rule.xml)
rule.xml 配置文件定义了我们对表进行拆分所涉及到的规则定义.我们可以灵活的对表使用不同的分片算法, 或者对表使用相同的算法但具体的参数不同. tableRule 标签 该标签用于定义表的拆分规 ...
- Maven-02: 依赖
其实一个依赖声明可以包含如下的一些元素: groupId,artifactId,version:依赖的基本坐标. type:依赖的类型,对应于项目坐标定义的packaging.大多数情况下,该元素不必 ...
- 前端的UI设计与交互之导航篇
在广义上,任何告知用户他在哪里,他能去什么地方以及如何到达那里的方式,都可以称之为导航.当设计者使用导航或者自定义一些导航结构时,请注意:尽可能提供标识.上下文线索,避免用户迷路:保持导航样式和行为一 ...
- 玩转log4j
我的目标是授人以渔,而不是授人以鱼,我相信你仔细看完这篇文章,玩转log4j不成问题 先来一个log4j最简单的例子 public class MyApp { static Logger logger ...
- c++ --> c++中四种类型转换方式
c++中四种类型转换方式 c风格转换的格式很简单(TYPE)EXPRESSION,但是c风格的类型转换有不少缺点, 1)它可以在任意类型之间转换,比如你可以把一个指向const对象的指针转换成指向 ...
- SpringMvc环境搭建(配置文件)
在上面的随笔里已经把搭建springmvc环境的基本需要的包都下下来了,拉下来就是写配置文件了. 下面左图是总的结构,右图是增加包 一.最开始当然是web.xml文件了,这是一个总的宏观配置 < ...
- jQuery学习笔记 .addClass()/.removeClass()简单学习
使用jQuery或javaScript来动态改变页面中某个或部分元素的样式,为了实现这样的功能,我们往往都是使用jQuery或javaScript来控制HTML中DOM的类名(class)从而实现增加 ...
- 开源小工具 酷狗、网易音乐缓存文件转mp3工具
发布一个开源小工具,支持将酷狗和网易云音乐的缓存文件转码为MP3文件. 以前写过kgtemp文件转mp3工具,正好当前又有网易云音乐缓存文件需求,因此就在原来小工具的基础上做了一点修改,增加了对网易云 ...
- python多进程并发redis
Redis支持两种持久化方式RDB和AOF,RDB持久化能够快速的储存和回复数据,但在服务器停机时会丢失大量数据,AOF持久化能够高效的提高数据的安全性,但在储存和恢复数据方面要耗费大量的时间,最好的 ...
- Vue 知识复习(上)
Vue Vue实例 创建实例: var vm = new Vue({ //code }) 数据与方法: 只有当实例被创建时 data 中存在的属性才是响应式的; Vm.b = 'h1' 是不会触发视图 ...