Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)
Spark显式缓存
NVMe SSD面临的调整
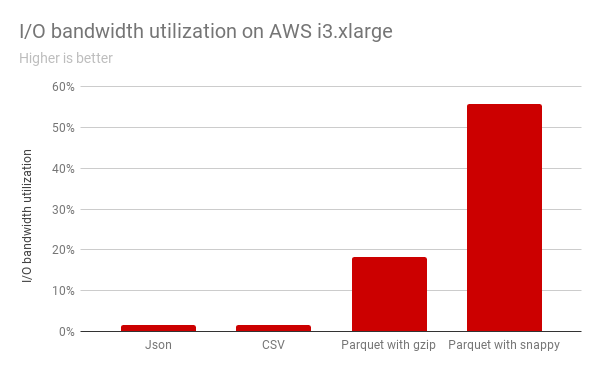
自适应运行
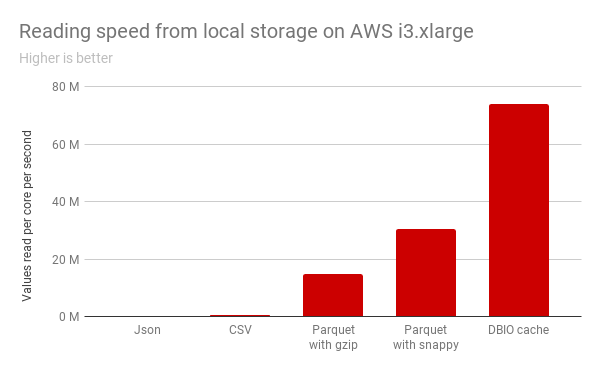
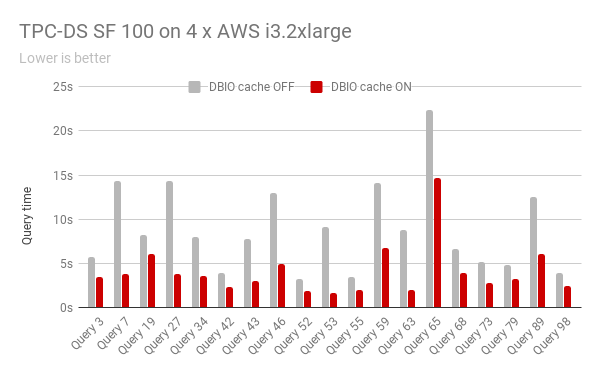
性能
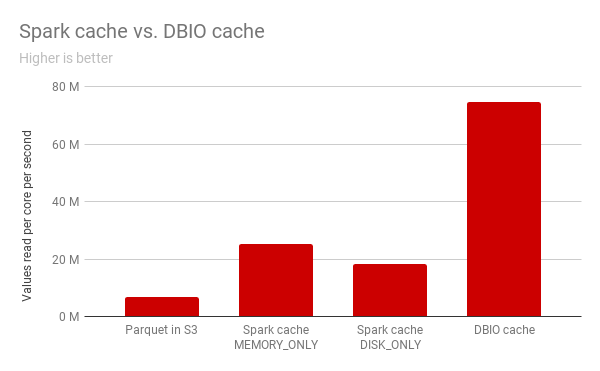
对比Spark缓存和Databricks缓存
Databricks缓存配置
spark.databricks.io.cache.enabled true
spark.databricks.io.cache.maxDiskUsage "{DISK SPACE PER NODE RESERVED FOR CACHED DATA}"
spark.databricks.io.cache.maxMetaDataCache "{DISK SPACE PER NODE RESERVED FOR CACHED METADATA}"
结论
Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)的更多相关文章
- NVMe固态硬盘工具箱使用说明
https://www.bilibili.com/read/cv562989/ 浦科特NVMe固态硬盘工具箱使用说明 数码 2018-6-7 687阅读7点赞3评论 浦科特已经推出针对NVMe固态硬盘 ...
- 一文看懂SATA和NVMe固态硬盘用起来有何区别?
本文摘自:https://www.sohu.com/a/203688929_615464 NVMe固态硬盘正在逐步扩张,而包括三星.东芝在内的大厂并没有停止SATA固态硬盘新品的研发.到底那种固态硬盘 ...
- ubuntu 开机进入grub rescue> 解决办法(nvme固态硬盘)
起因: 我是在windows下格式化了ubuntu的盘,然后重新安装ubuntu就出现了这种问题.卸载ubuntu的正确姿势,要去查一下,千万不要直接格式化. 解决方法: 1. 先使用ls命令,找到 ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- 把WinXP装进内存 性能飚升秒杀固态硬盘
现在用户新配置的电脑,内存很少有小于2GB的,配置4GB内存的朋友也有不少.容量如此大的内存,我们在使用电脑的日常操作中绝对用不完.而目前制约系统性能最大的瓶颈就是硬盘的传输速度,所以,这里教你怎么把 ...
- M.2接口NVMe协议的固态硬盘读写速度是SATA接口的两倍
原文:https://www.sohu.com/a/203688929_615464 中午走路的时候,同事说的,M 2 nvme接口的更快. 树莓派开发板可以跑linux . ------------ ...
- 固态硬盘寿命实测让你直观SSD寿命!--转
近年来,高端笔记本及系列上网本越来越多的采用固态硬盘来提升整机性能,尽管众所周知固态硬盘除 了在正常的使用中带来更快速度的体验外,还具有零噪音.不怕震动.低功耗等优点,但大家对固态硬盘的寿命问题的担忧 ...
- 机械硬盘和ssd固态硬盘的原理对比分析
固态硬盘和机械硬盘的区别 机械硬盘 磁头是不是直接和盘片接触的呢 磁盘中有几个盘片 机械硬盘的工作原理 固态硬盘的寻址方式 SMR叠瓦式真的比PMR优秀吗 固态硬盘 主控芯片 闪存颗粒 缓存单元 固态 ...
随机推荐
- vim保存时提示: 无法打开并写入文件
命名内容已经写入,但是不知怎的就是没法保存,估计是权限不足的问题. 切换到root用户,进行了同样的操作,发现没有该问题了. 经验教训:编辑配置文件时,记得切换到root用户进行编辑.
- instr函数的"重载"
.带两个参数的 --模糊查询,comp表的Mobel和show_name字段中含有'张' INSTR(COMP.MOBILE .带三个参数的 ) from dual; 结果: 第三个参数:从字符串&q ...
- WebGL光照阴影映射
原文地址:WebGL光照阴影映射 经过前面的学习,webgl的基本功能都已经掌握了,我们不仅掌握了着色器的编写,图形的绘制,矩阵的变换,添加光照,还通过对webgl的基础api封装,编写出了便 ...
- meterpreter_paranoid_mode.sh允许用户安全上演/无级连接Meterpreter经检查合格证书的处理程序正在连接到
刚刚看完即刻安全大咖的新姿势感觉很6逼,结果成功了meterpreter_paranoid_mode.sh允许用户安全上演/无级连接Meterpreter经检查合格证书的处理程序正在连接到. 我们开始 ...
- React Router 使用教程
一.基本用法 React Router 安装命令如下. $ npm install -S react-router 使用时,路由器Router就是React的一个组件. import { Router ...
- CTF---Web入门第十三题 拐弯抹角
拐弯抹角分值:10 来源: cwk32 难度:易 参与人数:5765人 Get Flag:2089人 答题人数:2143人 解题通过率:97% 如何欺骗服务器,才能拿到Flag? 格式:CTF{} 解 ...
- [51nod1502]苹果曼和纸
苹果曼有很大的一张纸.这张纸的形状是1×n的长方形.你的任务是帮助苹果曼来折叠这一张纸.有一些操作,这些操作有如下两个种形式: 1. 把这张纸在第pi个位置对折.经过对折后,左边的1×pi部分会盖到右 ...
- http://acm.hdu.edu.cn/showproblem.php?pid=1039(水~)
判读条件 1:有元音字母 2:不能三个连续元音或辅音 3.不能连续两个相同的字母,除非ee或oo #include<cstdio> #include<cstring> #inc ...
- GDI绘制时钟效果,与系统时间保持同步,基于Winform
2018年工作之余,想起来捡起GDI方面的技术,特意在RichCodeBox项目中做了两个示例程序,其中一个就是时钟效果,纯C#开发.这个CSharpQuartz是今天上午抽出一些时间,编写的,算是偷 ...
- UEP-树和表
Model Select:表格要展示的数据Tree DataSource:树的数据源数据源是自定义java类实现接口:ITreeRetriever创建根节点.判断子节点.创建子节点 --数据源 pac ...