Python:字符串操作总结
所有标准的序列操作(索引、分片、乘法、判断成员资格、求长度、取最小值最大值)对字符串同样适用,且字符串是不可变的。
一、字符串格式化
转换说明符 [注]: 这些项的顺序至关重要
(1)%字符:标记转换说明符的开始
(2)转换标志(可选)
| 转换标志 | 作用 |
| - | 左对齐 |
| + | 在转换值之前加上正负号 |
| ““(空白字符串) | 正数之前保留空格 |
| 0 | 转换值位数不够用0填充 |
(3)最小字段宽度(可选):转换后的字符串至少应该具有该值指定的宽度。 [注]:如果是*,则宽度会从值元组中读出
(4)点(.)后跟精度值(可选):
a、如果转换的是实数,精度值就表示出现在小数点后的位数
b、如果转换的是字符串,精度值就表示最大字段宽度
c、如果是*,那么精度值将会从元组中读出
(5)转换类型 [注]:红色为常用
| 转换类型 | 含义 |
| d,i | 带符号的十进制整数 |
| o | 不带符号的八进制整数 |
| u | 不带符号的十进制整数 |
| x | 不带符号的十六进制整数(小写) |
| X | 不带符号的十六进制整数(大写) |
| e | 科学计数法表示的浮点数(小写) |
| E | 科学计数法表示的浮点数(大写) |
| f,F | 十进制浮点数 |
| g | 如果指数大于-4或者小于精度值则和e相同,其他情况与f相同 |
| G | 如果指数大于-4或者小于精度值则和E相同,其他情况与F相同 |
| C | 单字符(接受整数或者单字符字符串) |
| r | 字符串(使用repr转换的任意Python对象) |
| s | 字符串(使用str转换的任意Python对象) |
Examples:
pi=3.1415926
print('%10f' %pi) #宽度为10
print('%10.2f' %pi) #宽度为10,精度为2
print('%+10.2f' %pi) #宽度为10,精度为2,数字前加正负号
print('%0+10.2f' %pi) #宽度为10,精度为2,数字前加正负号,并用0而非空格来填充
print('%-+10.2f' %pi) #宽度为10,精度为2,数字前加正负号,并且左对齐

name='Tomwenxing'
print('%20s' %name) #宽度为20
print('%20.3s' %name) #宽度为20,精度为3
print('%-20.3s' %name) #宽度为20,精度为3,左对齐
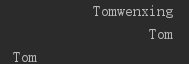
name='Tomwenxing'
print('%-*.*s' %(20,3,name)) #使用*作为字段宽度或精度

[注]:字典的格式化字符串
在每个转换说明符中的%字符后面,可以加上键(用圆括号括起来的),后面再跟上其他说明元素。但以这种方式使用字典时,只要所有给出的键值都能在字典中找到,就可以使用任意数量的转换说明符。
phonebook={'Beth':'','Alice':'','Cecil':''}
message="Cecil's phone number is %(Cecil)s" %phonebook
print(message)
二、字符串方法总结
C:
1.string.capitalize():将字符串的第一个字母变成大写,其他字母变成小写
2.string.center(width[, fillchar]):返回一个原字符串居中,并使用fillchar填充至长度width的新字符串。默认填充字符为空格
[注]:width:字符串的总宽度
fillchar:填充字符
name='Tomwenxing'
print(name.center(50,'-'))

3.string.count(sub,start=0,end=len(string)):统计字符串里摸个子字符串出现的次数。可选参数为字符串搜索的开始于结束位置
[注]:sub:搜索的子字符串
start:字符串开始搜索的位置,默认为第一个字符
end:字符串中结束搜索的位置,默认为字符串中最后一个位置
D:
1.string.decode():以encoding制定的编码格式解码字符串。默认编码为字符串编码,返回解码后的字符串
string.decode(encoding='UTF-8',errors='strict')
[注]: encoding:要使用的编码,如'UTF-8'、‘base64’
errors:设置不同错误的处理方式。默认为‘strict’,意为编码错误引起一个UnicodeError
E:
1.string.encode():以encoding制定的编码格式编码字符串。默认编码为字符串编码,返回编码后的字符串
string.encode(encoding='UTF-8',errors='strict')
[注]: encoding:要使用的编码,如'UTF-8'、‘base64’
errors:设置不同错误的处理方式。默认为‘strict’,意为编码错误引起一个UnicodeError
[理解]:encode和decode的作用:
(1) 字符串在Python内部的表示是Unicode编码
(2)decode的作用是将其他编码的字符串转换成Unicode编码。如:str1.decode('UTF-8')的意思是将UTF-8编码的字符串str1转换成Unicode编码
(3)encode的作用是将Unicode编码的字符串转换成其他编码。如:str2.encode('UTF-8')的意思是将Unicode编码的字符串str2转换成UTF-8编码
2.string.endswith(suffix[,start[,end]]):判断字符串是否以指定后缀结尾,如果是以指定后缀结尾返回True,否则返回False,可选参数“start”和“end”为检索字符串的开始和结束位置
3.string.expandtabs(tabsize=8):把字符串中的tab符号('\t')转为空格,tab符号('\t')默认的空格数是8
[注]: tabsize:指定tab符号('\t')转为多少个空格
message='Today is\ta good day'
print(message.expandtabs(tabsize=4))#指定tab符号转换为4个空格

F:
1.string.find(str,beg=0,end=len(string)):检测字符串中是否包含子字符串str,如果指定beg(开始)和end(结束)范围,则检测子字符串str是否包含在指定范围内,如果包含子字符串则返回开始的索引值,否则返回-1
2.string.format():格式化字符串(详见:http://www.cnblogs.com/duwenxing/p/7347637.html)
3.string.format_map():利用字典格式化字符串
info='''
-------------------------info of {name}---------------------
Name:{name}
Age:{age}
Job:{job}
Salary:{salary}
'''
data={'name':'Tomwenxing','age':'','job':'student','salary':''}
print(info.format_map(data))

I:
1.string.isalnum():如果string至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False
2.string.isalpha():如果string至少有一个字符并且所有字符都是字母则返回True,否则返回False
3.string.isdecimal():如果string只包含十进制数字则返回True,否则返回False
4.string.isdigit():如果string只包含数字则返回True,否则返回False
5.string.islower():如果string至少有一个区分大小写的字符并且所有这些字符都是小写则返回True,否则返回False
6.string.isnumeric():如果string中只包含数字字符,则返回True,否则返回False
[注]: 这种返回只针对Unicode对象
7.string.isspace():如果字符串只包含空格或制表符,则返回True,否则返回False
8.string.istitle():如果字符串中所有的单词拼写首字母为大写,其余字母为小写则返回True,否则返回False
9.string.isupper():如果string至少有一个区分大小写的字符并且所有这些字符都是大写则返回True,否则返回False
10.string.isidentifier():判断字符串是否是合法的表示符(字符串仅包含中文字符合法)
[注]:此方法常用来判断变量名是否合法
11.string.isprintable():如果字符串包含的字符都是可以打印的则返回True,如果包含不可打印的字符如转义字符则返回False
12.string.index(str,beg=0,end=len(string)):该方法的效果和string.find()一样,只不过如果str不存在string中会报一个异常
J:
1.string.join(iterable):使用字符串string将iterable对象中的元素连接起来,返回一个string连接起来的由iterable对象的元素组成的字符串
number=['','','','']
print('+'.join(number))

L:
1.string.lower():把全部字母字符转换为小写,不去管其他非字母字符(字符串全部为非字母字符也是合法的)。返回原字符串
2.string.ljust(width[,fillchar]):返回一个原字符串左对齐,并使用fillchar(默认是空格)填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串
name='Tomwenxing'
print(name.ljust(30,'*'))

3.string.lstrip(chars):用于截掉字符串左边的空格(默认)或指定字符,返回新的字符串
[注]: chars:指定截取的字符
name='***********Tomwenxing'
print(name.lstrip('*'))

M:
1.str.maketrans(intab,outtab):maketrans()方法用于创建字符映射的转换表。第一个参数intab是字符串,表示与需要转换的字符串;第二个参数outtab也是字符串,表示转换的目标字符串
[注]:
(1) 两个字符串的长度必须相同,为一一对应的关系
(2)Python3.4中已经没有string.maketrans()方法了,取而代之的是内建函数str.maketrans()
(3)该方法通常和string.translate()方法一起使用
p=str.maketrans('','abcde')
print(p) #结果是一个ASCII码映射字典

P:
1.string.partition(str):用来根据指定的分隔符(str)将字符串进行分割。如果字符串包含指定的分割符,则返回一个3元的元组,其中第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
str='http://baidu.com/'
print(str.partition('//'))

R:
1.string.rstrip(chars):用于截掉字符串右边的空格(默认)或指定字符,返回新的字符串
name='Tomwenxing*****************'
print(name.rstrip('*'))
2.string.replace(old,new[,max]):把字符串中的old(旧字符串)替换成new(新字符串),如果指定第三个参数max,则替换不超过max次
message='''
That is an apple,
That is a banana,
That is a book
'''
print(message.replace('is','was',2))

3.string.rfind(str,beg=0,end=len(string)):返回字符串最后一次出现的位置(从右向左查询),如果没用匹配项返回-1
info='This is a apple,but that is a book'
print(info.rfind('is'))

4.string.rindex(str,beg=0,end=len(string)):返回子字符串str在字符串中最后出现的位置,如果没有匹配的字符串会报异常,可以指定可选参数[beg:end]设置查找区间
5string.rjust(width[,fillchar]):返回一个原字符串右对齐,并使用fillchar(默认是空格)填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串
name='Tomwenxing'
print(name.rjust(30,'*'))

6.string.rpartition(str):功能和string.partition(str)类似
[注]: string.partition(str)和string.rpartition(str)的不同之处
web='http://baidu//com'
print(web.partition('//'))
print(web.rpartition('//'))

7.string.rsplit(str="",num=string.count(str)):通过指定分割符对字符串进行切片,如果num有指定值,则仅分割num个子字符串
[注]:
(1)string.split()是从左至右处理字符串
string.rsplit()是从右至左处理字符串
(2)str位分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)deng
(3)num为分割次数
message='aaaabaaaaabaaaabaaabaaaabaaabaabaaa'
print(message.split('b',3))
print(message.rsplit('b',3))

S:
1.string.split(str="",num=string.count(str)):通过指定分割符对字符串进行切片,如果num有指定值,则仅分割num个子字符串
2.string.strip(chars):用于移除字符串头尾指定的字符(默认为空格)
name='**********Tomwenxing****************'
print(name.strip('*'))
3.string.splitlines([keepends]):按照行('\r';'\r\n','\n')分隔,返回一个包含各行作为元素的列表,如果产生keepends为False,不包含换行符;如果为True,则保留换行符(默认为False)
str='ab c\n\nde fg\rkl\r\n'
print(str.splitlines())
print(str.splitlines(True))

4.string.startswith(str,beg=0,end=len(string)):检查字符串是否以指定的子字符串开头,如果是则返回True,否则返回False。如果参数beg和end指定值,则在指定的范围内检查
5.string.swapcase():将字符串中的大写字母变为小写字母,小写字母变为大写字母
str='HEGsgsa'
print(str.swapcase())

T:
1.string.title():返回标签化的字符串,即所有单词都是以大写开始,其余字母均为小写
name='toM haNd kING'
print(name.title())

2.string.translate(table):根据参数table给出的表(包含256个字符)转换字符串的字符
[注]:table:翻译表,通常是通过maketrans方法得到
message='This is a simple string example'
intabs='abcde'
outtabs=''
tab=str.maketrans(intabs,outtabs)
print(message.translate(tab))

U:
1.string.upper():把全部字母字符转换为大写,不去管其他非字母字符(字符串全部为非字母字符也是合法的)。返回原字符串
Z:
1.string.zfill(width):返回指定长度的字符串,原字符串右对齐,前面填充0
name='Tomwenxing'
print(name.zfill(30))

参考:《Python基础教程》、RUNOOB.COM
Python:字符串操作总结的更多相关文章
- Python 字符串操作
Python 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) 去空格及特殊符号 s.strip() .lstrip() .rstrip(',') 复制字符 ...
- python字符串操作实方法大合集
python字符串操作实方法大合集,包括了几乎所有常用的python字符串操作,如字符串的替换.删除.截取.复制.连接.比较.查找.分割等,需要的朋友可以参考下: #1.去空格及特殊符号 s.st ...
- 转 Python 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
转自: http://www.cnblogs.com/huangcong/archive/2011/08/29/2158268.html 黄聪:Python 字符串操作(string替换.删除.截取. ...
- Python 字符串操作及string模块使用
python的字符串操作通过2部分的方法函数基本上就可以解决所有的字符串操作需求: python的字符串属性函数 python的string模块 1.字符串属性方法操作: 1.>字符串格式输出对 ...
- python字符串操作总结
python中有各种字符串操作,一开始python有个专门的string模块,要使用需先import string.后来从python2.0开始,string方法改用str.method()形式调用, ...
- 『无为则无心』Python序列 — 17、Python字符串操作常用API
目录 1.字符串的查找 @1.find()方法 @2.index()方法 @3.rfind()和rindex()方法 @4.count()方法 2.字符串的修改 @1.replace()方法 @2.s ...
- python 字符串操作。。
#字符串操作 以0开始,有负下标的使用0第一个元素,-1最后一个元素,-len第一个元 素,len-1最后一个元素 name= "qwe , erw, qwe "print(nam ...
- Python 字符串操作,截取,长度
1.字符串操作: 字符串长度: s = "; slen = len(s); 字符串截取: print s[:-:-] #截取,逆序隔1个取一个字符 print s[:-:-] #截取,逆序隔 ...
- python字符串操作、文件操作,英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 解析身份证号:生日.性别.出生地等 def function3(): print('请输入身份证号') ...
- python字符串操作2
在python有各种各样的string操作函数.在历史上string类在python中经历了一段轮回的历史.在最开始的时候,python有一个专 门的string的module,要使用string的方 ...
随机推荐
- 前端使用mobx时,变量已经修改了,为什么组件还是没变化,map类型变量,对象类型变量的值获取问题(主要矛盾发生在组件使用时)
前天我在使用一个前端多选框组件时遇到了一个问题,明明对象内的值已经修改了,但是组件显示的还是没有效果改变,以下是当时打出的log,我打印了这个对象的信息 对象内的值已经修改了但是组件还是不能及时更改, ...
- php以数组做为配置文件的读取和写入操作
最近想用php开发个简单的文章管理系统,主要是做一批垃圾采集站,目前网上的cms都太多功能了,导致修改个模板要很多文件,花费很多功夫.开始用thinkphp框架做,感觉还是麻烦,后来改用ci,做好了后 ...
- Kafka解惑之时间轮 (TimingWheel)
Kafka中存在大量的延迟操作,比如延迟生产.延迟拉取以及延迟删除等.Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定 ...
- python爬虫同时输出两个列表(zip函数)
简介:在做爬虫时,xpath返回的是列表格式,我们又需要将列表中的元素一一对应并存放至字典中,这是就可以用zip函数. zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组, ...
- sourcetree的安装及使用
sourcetree下载地址:https://www.sourcetreeapp.com/ 点击安装包安装 此前需要跳转到bitbucket登录,我没有账号,所以我直接跳转到到https://bitb ...
- DP_最长公共子序列/动规入门
学自:https://open.163.com/movie/2010/12/L/4/M6UTT5U0I_M6V2U1HL4.html 最长公共子序列:(本文先谈如何求出最长公共子序列的长度,求出最长公 ...
- flex datagrid checkbox选中项目
<?xml version="1.0" encoding="utf-8"?> <mx:Application xmlns:fx=" ...
- 20145226夏艺华 《Java程序设计》第7&8周学习总结、实验一
[实验一]http://www.cnblogs.com/bestixyh/p/6358734.html [第7周]http://www.cnblogs.com/bestixyh/p/6380475.h ...
- 思维水题 poj1852
题目链接:http://poj.org/problem?id=1852 题意:木板长为n, 蚂蚁数量为k, 后面k个数,依次代表蚂蚁的位置, 当蚂蚁到达边界的时候会立马掉下,当两个蚂蚁相 ...
- python 多线程笔记(2)-- 锁
锁是什么?什么场合使用锁? 锁是一种机制,用于保护那些会引起冲突的资源. 比如上厕所,进去之后第一件事干嘛?把厕所门反锁!表示什么呢?表示这个厕所正在使用中! 至于在厕所里面干大事.干小事.还是打飞机 ...