Java-Web DOM方式解析xml文件
XML DOM 树形结构:
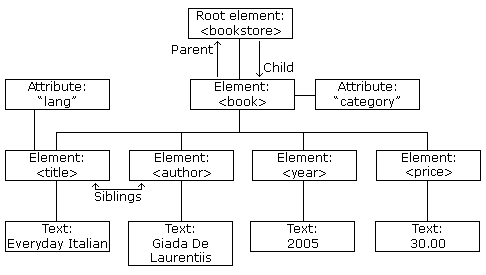
DOM 节点
根据 DOM,XML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 元素是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释是注释节点
常用节点类型
| 节点类型 | NodeType | Named Constant | nodeName 的返回值 | nodeValue 的返回值 |
| Element | 1 | ELEMENT_NODE | element name | null |
| Attr | 2 | ATTRIBUTE_NODE | 属性名称 | 属性值 |
| Text | 3 | TEXT_NODE | #text | 节点名称 |
案例:
目标:解析xml文件后,Java程序能够得到xml文件的所有数据
思考:如何在解析之后保留xml的结构信息
xml文档:

实例:
package Test;
/**
* 案例:运用DOM解析xml文件,获得xml文件的所有数据
*/
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList; public class DOMDemo {
public static void main(String[] args) throws Exception {
/** 步骤一:创建一个DocumentBuilderFactory的对象
* 1.定义工厂 API,使应用程序能够从 XML 文档获取生成 DOM 对象树的解析器。
* 2. protected DocumentBuilderFactory()
* 用于阻止实例化的受保护构造方法
* 3. static DocumentBuilderFactory newInstance()
* 获取 DocumentBuilderFactory 的新实例。
*/
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); /** 步骤二:创建一个DocumentBuilder的对象
* 1.protected DocumentBuilder()
* 受保护的构造方法
* 2.使其从 XML 文档获取 DOM 文档实例。使用此类,应用程序员可以从 XML 获取一个 Document。
*/
DocumentBuilder db = dbf.newDocumentBuilder(); /** 步骤三:通过DocumentBuilder对象的parse方法加载book.xml文件到当前目录下
* 1.parse(File f)
* 将给定文件的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象。
*/
Document document = db.parse("books.xml"); /** 步骤四:获取所有book节点的集合
* 1.getElementsByTagName():通过节点的名称来获取所有同名节点,
* 因为不只有一个节点,所以就把获取的所有节点都存放在一个节点集合中。
*/
NodeList booklist = document.getElementsByTagName("book");
System.out.println("一共有" + booklist.getLength() + "本书"); /** 步骤五:遍历每一个book节点
* 1.Node item(int index)
* 返回集合中的第 index 个项。
* 2.NamedNodeMap getAttributes()
* 包含此节点的属性的 NamedNodeMap(如果它是 Element);否则为 null。
*/ for(int i = 0; i < booklist.getLength(); i++){ // 前提:不知道book节点的id属性有多少
System.out.println("===========下面开始遍历第" + (i+1) + "本书的内容===========");
// 通过item方法获取一个book节点
Node book = booklist.item(i);
// 获取book节点的所有属性集合
NamedNodeMap attrs = book.getAttributes();
System.out.println("第" + (i+1) + "本书共有" + attrs.getLength() + "个属性");
// 遍历book的属性
for(int j = 0; j < attrs.getLength(); j++){
// 通过item方法获取book节点的某一个属性
Node attr = attrs.item(j);
// 获取属性名
System.out.print("属性名:" + attr.getNodeName());
// 获取属性值
System.out.println("--属性值:" + attr.getNodeValue());
} /* // 前提:已经知道book节点有且只有一个id属性
// 将book节点进行强制类型转换,转换成Element类型
Element ebook = (Element)booklist.item(i);
// 通过getAttribute("id")方法来获取属性值
String attrValue = ebook.getAttribute("id");
System.out.println("id属性值为:" + attrValue);
*/ /** 步骤六:解析book节点的子节点
* 1.NodeList getChildNodes()
* 包含此节点的所有子节点的 NodeList。
*/
NodeList childNodes = book.getChildNodes();
// 遍历childNodes获取每个节点的节点名和节点值
System.out.println("第" + (i+1) + "本书共有" + childNodes.getLength() + "个子节点");
for(int k = 0; k < childNodes.getLength(); k++){ /* 如果不对节点类型进行判断
* 遍历book节点的子节点后会发现有9个子节点,但是我们只写了4个子节点
* 输出了5个#text节点,这是Text类型的节点。
* 因为空格也属于子节点,所以也会i被遍历出来。
* */
// 区分出text类型的node以及element类型的node
if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){
// 获取element类型节点的节点名
System.out.print("第" + (k+1) + "个节点的是" + childNodes.item(k).getNodeName() + ": "); /* 当我们用childNodes.item(k).getNodeValue()这种方法获取
* element类型的节点的节点值时会返回空,因为他认为
* <name>冰与火之歌</name>中“冰与火之歌”是<name>的子节点,
* 所以返回<name>节点的值当然是null,因为它认为“冰与火之歌”是节点而不是内容。
* 我们这时需要返回<name>节点的第一个子节点,再返回第一个子节点的值就可以了,
* 或者用getTextContent()也可以解决,它会获取所有子节点的节点值
* */
// System.out.println(childNodes.item(k).getFirstChild().getNodeValue());
System.out.println(childNodes.item(k).getTextContent());
} } } } }
运行结果:
一共有2本书
===========下面开始遍历第1本书的内容===========
第1本书共有1个属性
属性名:id--属性值:1
第1本书共有9个子节点
第2个节点的是name: 冰与火之歌
第4个节点的是author: 乔治马丁
第6个节点的是year: 2014
第8个节点的是price: 89
===========下面开始遍历第2本书的内容===========
第2本书共有1个属性
属性名:id--属性值:2
第2本书共有9个子节点
第2个节点的是name: 格林童话
第4个节点的是year: 2004
第6个节点的是price: 66
第8个节点的是language: English
Java-Web DOM方式解析xml文件的更多相关文章
- 用JAXP的dom方式解析XML文件
用JAXP的dom方式解析XML文件,实现增删改查操作 dom方式解析XML原理 XML文件 <?xml version="1.0" encoding="UTF-8 ...
- 在iOS 开发中用GDataXML(DOM方式)解析xml文件
因为GDataXML的内部实现是通过DOM方式解析的,而在iOS 开发中用DOM方式解析xml文件,这个时候我们需要开启DOM,因为ios 开发中是不会自动开启的,只有在mac 开发中才自动开启的.我 ...
- Java&Xml教程(二)使用DOM方式解析XML文件
DOM XML 解析方式是最容易理解的,它將XML文件作为Document对象读取到内存中,然后你可以轻松地遍历不同的元素和节点对象.遍历元素和节点不需要按照顺序进行. DOM解析方式适合尺寸较小的X ...
- DOM方式解析XML文件实例
books.XML文件: <?xml version="1.0" encoding="utf-8"?><bookstore> &l ...
- dom方式解析xml文件的步骤
使用java类即可
- 用DOM方式解析XML
一.用DOM方式解析XML 此例子节点结构如下: 1.获取book节点属性 (1).如果不知道节点的属性,通过 NamedNodeMap attrs = book.getAttributes(); 来 ...
- Dom方式解析XML
public class TestXML { public static void main(String[] args) throws SAXException, IOException { //D ...
- Java眼中的XML--文件读取--1 应用DOM方式解析XML
初次邂逅XML: 需要解析的XML文件: 这里有两个book子节点. 1.如何进行XML文件解析前的准备工作,另外解析先获取book节点. 这个我后来看懂了: 这个Node的ELEMENT_NODE= ...
- Java&Xml教程(五)使用SAX方式解析XML文件
Java SAX解析机制为我们提供了一系列的API来处理XML文件,SAX解析和DOM解析方式不太一样,它并不是將XML文件内容一次性全部加载,而是连续的部分加载. javax.xml.parsers ...
随机推荐
- [BZOJ1176]Mokia
Description 维护一个W*W的矩阵,初始值均为S.每次操作可以增加某格子的权值,或询问某子矩阵的总权值.修改操作数M<=160000,询问数Q<=10000,W<=2000 ...
- 如何利用Xshell在windows与linux之间互传文件
如何利用Xshell在windows与linux之间互传文件 第一步: 安装Xshell. 第二步: 打开Xshell,若出现默认的对话框,则选择关闭,因为下面将演示如何将本地文件传输至远程linux ...
- [调参]CV炼丹技巧/经验
转自:https://www.zhihu.com/question/25097993 我和@杨军类似, 也是半路出家. 现在的工作内容主要就是使用CNN做CV任务. 干调参这种活也有两年时间了. 我的 ...
- UOJ #266 【清华集训2016】 Alice和Bob又在玩游戏
题目链接:Alice和Bob又在玩游戏 这道题就是一个很显然的公平游戏. 首先\(O(n^2)\)的算法非常好写.暴力枚举每个后继计算\(mex\)即可.注意计算后继的时候可以直接从父亲转移过来,没必 ...
- Python XML解析和处理
movies.xml <collection shelf = "New Arrivals"> <movie title = "Enemy Behind& ...
- sapply
列表并非总是存储结果的最佳容器.有时,我们希望将结果放在一个向量或者矩阵中.sapply( )函数可以根据结果的结构将其合理简化.假设,我们将平方运算应用到 1:10 的每个元素上.如果使用 lapp ...
- Web开发中常用的定位布局position
定位布局就是为开发提供了更好的布局方式,可以根据需求给相应的模块设定相应位置,从而使界面更佳丰富,代码更佳完美. position是CSS中非常重要的一个属性,通过position属性,我们可以让元素 ...
- bzoj2163
题解: 拆点网络流 然后用总和-最大流 代码: #include<iostream> #include<cstring> #include<cstdio> #inc ...
- 高并发数据采集的架构应用(Redis的应用)
问题的出发点: 最近公司为了发展需要,要扩大对用户的信息采集,每个用户的采集量估计约3W.如果用户量增加的话,将会大量照成采集量成3W倍的增长,但是又要满足日常业务需要,特别是报表数据必要 ...
- 在jenkins和sonar中集成jacoco(一)--使用jacoco收集单元测试的覆盖率
之前系统的持续集成覆盖率工具使用的是cobetura,使用的过程中虽然没什么问题,但感觉配置比较麻烦,现在准备改用jacoco这个覆盖率工具来代替它.接下来我介绍一下jenkins配置jacoco,并 ...