沉淀再出发:在python3中导入自定义的包
沉淀再出发:在python3中导入自定义的包
一、前言
在python中如果要使用自己的定义的包,还是有一些需要注意的事项的,这里简单记录一下。
二、在python3中导入自定义的包
2.1、什么是模块、包、库?
模块:就是.py文件,里面定义了一些函数和变量,需要的时候就可以导入这些模块。
包:在模块之上的概念,为了方便管理而将文件进行打包。包目录下第一个文件便是 __init__.py,然后是一些模块文件和子目录,假如子目录中也有 __init__.py,那么它就是这个包的子包了。
库:具有相关功能模块的集合。这也是Python的一大特色之一,即具有强大的标准库、第三方库以及自定义模块。标准库就是下载安装的python里那些自带的模块,要注意的是,里面有一些模块是看不到的比如像sys模块,这与linux下的cd命令看不到是一样的情况。第三方库是由其他的第三方机构,发布的具有特定功能的模块。自定义模块是用户自己编写的模块。
这三个概念实际上都是模块,只不过是个体和集合的区别。
2.2、简单的自定义包
我们在任何一个目录下面新建一个文件夹和两个.py文件,然后在文件夹下面创建一个空的__init__.py文件和.py的文件,然后开始实验。
首先我们看看在同级目录下各个模块的引用情况
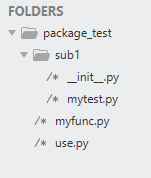
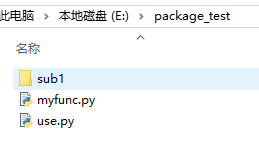

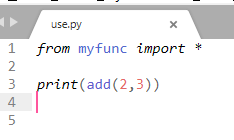
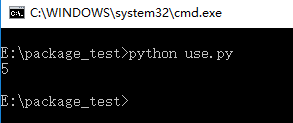
打开CMD,将目录切换到当前文件夹下,运行程序,可以发现在同目录下正常运行并且生成了缓存文件:
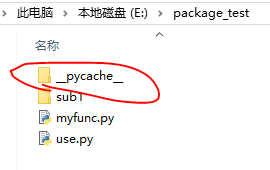
然后我们测试在不同目录下
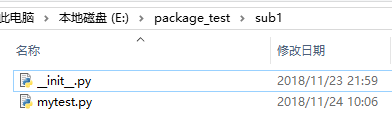
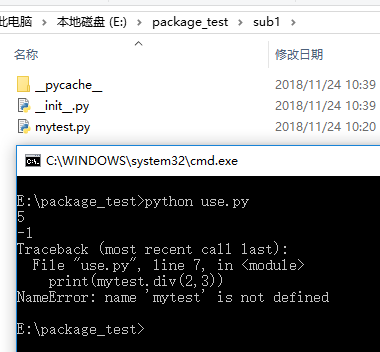
在sub1文件夹下我们因为创建了__init__.py文件,系统会认为这个文件是一个package,因此,就会尝试着加载和发现我们定义的模块:
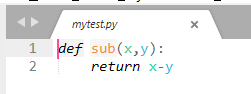
然后再use.py中,我们发现可以正常的使用和执行了:
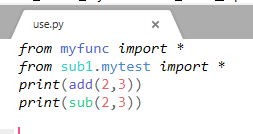
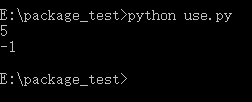
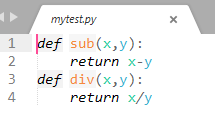
其实如果我们将__init__.py文件删除了,结果也会是一样的,同样可以运行:

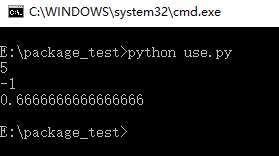
但是如果我们使用import 包名.模块名的时候就会出现问题了,我们会发现如果是在同级上可以正常使用,但是在不同的包下面,除非我们使用全称,要不然的话是不能成功的(注意:这个时候我们的包依旧没有使用__init__.py文件):
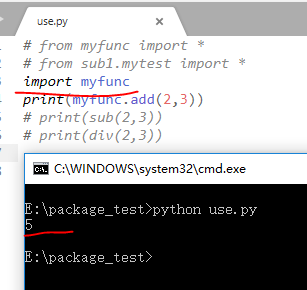
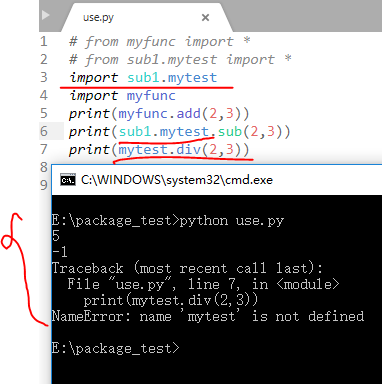
即使我们使用了__init__.py依旧会是这样:
那么到底是为什么呢?
这是因为python3需要绝对路径引用,从project的根位置开始指明被引模块的位置。通用格式为:from directory import module 。如果module存在于directory1下的directory2,那么建议写成from directory1.directory2 import module,其中程序运行时根目录(mount)为directory1。使用from语句可以把模块直接导入当前命名空间,from语句并不引用导入对象的命名空间,而是将被导入对象直接引入当前命名空间。但是如果直接使用import的时候,就会使用另一个命名空间下面的函数或者变量,这个时候我们就需要使用全称来指代。
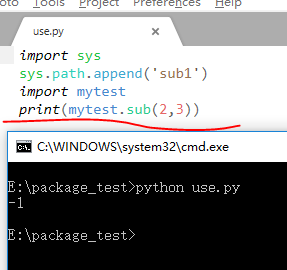
那么有没有解决办法呢,当然是有的,比如我们将子包加入到sys.path中,这样系统就能自动识别了(这个时候不需要__init__.py文件):
import sys
sys.path.append('sub1')
import mytest
print(mytest.sub(2,3))
2.3、__init__.py的作用
大家可能注意到,我一直在提这个文件,那么我们可以看到在很多的大型项目之中都是有这个文件存在的,我们可以看看我们自己使用pip install XXX,从网上下载的包文件:
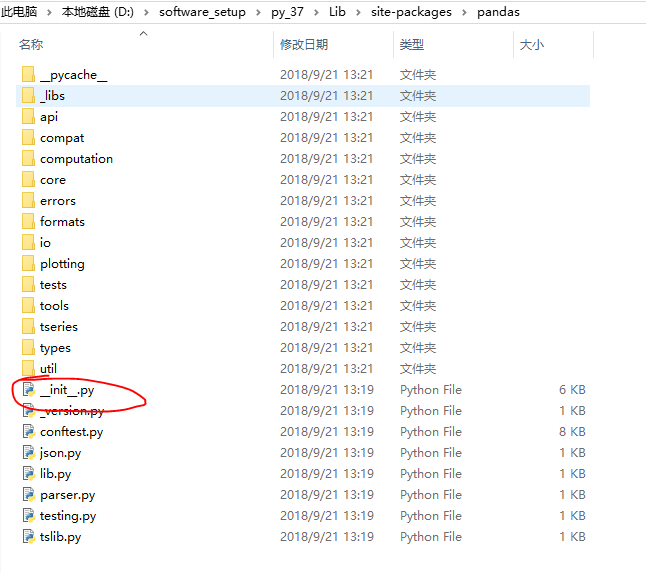
随便找一个都会发现这个文件的,并且在子目录下面也都会有这个文件的,我们看看上面的这个文件的内容,可以发现其中将自己目录下面的文件进行了一种整合方便用户直接来使用,再看看下面的子目录中的__init__.py文件有的为空,有的就是整合该目录下面的文件资源的:
# pylint: disable-msg=W0614,W0401,W0611,W0622 # flake8: noqa __docformat__ = 'restructuredtext' # Let users know if they're missing any of our hard dependencies
hard_dependencies = ("numpy", "pytz", "dateutil")
missing_dependencies = [] for dependency in hard_dependencies:
try:
__import__(dependency)
except ImportError as e:
missing_dependencies.append(dependency) if missing_dependencies:
raise ImportError(
"Missing required dependencies {0}".format(missing_dependencies))
del hard_dependencies, dependency, missing_dependencies # numpy compat
from pandas.compat.numpy import * try:
from pandas._libs import (hashtable as _hashtable,
lib as _lib,
tslib as _tslib)
except ImportError as e: # pragma: no cover
# hack but overkill to use re
module = str(e).replace('cannot import name ', '')
raise ImportError("C extension: {0} not built. If you want to import "
"pandas from the source directory, you may need to run "
"'python setup.py build_ext --inplace --force' to build "
"the C extensions first.".format(module)) from datetime import datetime # let init-time option registration happen
import pandas.core.config_init from pandas.core.api import *
from pandas.core.sparse.api import *
from pandas.tseries.api import *
from pandas.core.computation.api import *
from pandas.core.reshape.api import * # deprecate tools.plotting, plot_params and scatter_matrix on the top namespace
import pandas.tools.plotting
plot_params = pandas.plotting._style._Options(deprecated=True)
# do not import deprecate to top namespace
scatter_matrix = pandas.util._decorators.deprecate(
'pandas.scatter_matrix', pandas.plotting.scatter_matrix, '0.20.0',
'pandas.plotting.scatter_matrix') from pandas.util._print_versions import show_versions
from pandas.io.api import *
from pandas.util._tester import test
import pandas.testing # extension module deprecations
from pandas.util._depr_module import _DeprecatedModule json = _DeprecatedModule(deprmod='pandas.json',
moved={'dumps': 'pandas.io.json.dumps',
'loads': 'pandas.io.json.loads'})
parser = _DeprecatedModule(deprmod='pandas.parser',
removals=['na_values'],
moved={'CParserError': 'pandas.errors.ParserError'})
lib = _DeprecatedModule(deprmod='pandas.lib', deprmodto=False,
moved={'Timestamp': 'pandas.Timestamp',
'Timedelta': 'pandas.Timedelta',
'NaT': 'pandas.NaT',
'infer_dtype': 'pandas.api.types.infer_dtype'})
tslib = _DeprecatedModule(deprmod='pandas.tslib',
moved={'Timestamp': 'pandas.Timestamp',
'Timedelta': 'pandas.Timedelta',
'NaT': 'pandas.NaT',
'NaTType': 'type(pandas.NaT)',
'OutOfBoundsDatetime': 'pandas.errors.OutOfBoundsDatetime'}) # use the closest tagged version if possible
from ._version import get_versions
v = get_versions()
__version__ = v.get('closest-tag', v['version'])
del get_versions, v # module level doc-string
__doc__ = """
pandas - a powerful data analysis and manipulation library for Python
===================================================================== **pandas** is a Python package providing fast, flexible, and expressive data
structures designed to make working with "relational" or "labeled" data both
easy and intuitive. It aims to be the fundamental high-level building block for
doing practical, **real world** data analysis in Python. Additionally, it has
the broader goal of becoming **the most powerful and flexible open source data
analysis / manipulation tool available in any language**. It is already well on
its way toward this goal. Main Features
-------------
Here are just a few of the things that pandas does well: - Easy handling of missing data in floating point as well as non-floating
point data.
- Size mutability: columns can be inserted and deleted from DataFrame and
higher dimensional objects
- Automatic and explicit data alignment: objects can be explicitly aligned
to a set of labels, or the user can simply ignore the labels and let
`Series`, `DataFrame`, etc. automatically align the data for you in
computations.
- Powerful, flexible group by functionality to perform split-apply-combine
operations on data sets, for both aggregating and transforming data.
- Make it easy to convert ragged, differently-indexed data in other Python
and NumPy data structures into DataFrame objects.
- Intelligent label-based slicing, fancy indexing, and subsetting of large
data sets.
- Intuitive merging and joining data sets.
- Flexible reshaping and pivoting of data sets.
- Hierarchical labeling of axes (possible to have multiple labels per tick).
- Robust IO tools for loading data from flat files (CSV and delimited),
Excel files, databases, and saving/loading data from the ultrafast HDF5
format.
- Time series-specific functionality: date range generation and frequency
conversion, moving window statistics, moving window linear regressions,
date shifting and lagging, etc.
"""
下面我们看看__init__.py的作用:
__init__.py文件用于组织包(package)。当文件夹下有__init__.py时,表示当前文件夹是一个package,其下的多个module统一构成一个整体。这些module都可以通过同一个package引入代码中。__init__.py文件可以什么都不写,但如果想使用from package1 import *这种写法的话,需要在__init__.py中加上:
__all__ = ['file1','file2'] #package1下有file1.py,file2.py
我们看一个例子:


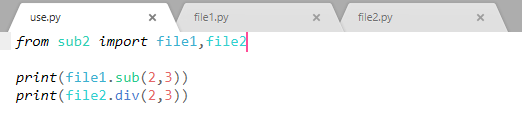

目前我们没有__init__.py文件,是可以运行的:

但是我们不能使用from sub2 import * 来使用。

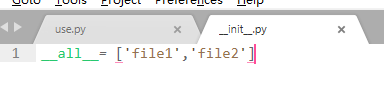
如果使用__init__.py,在其中加入下面的语句,程序就可以正常运行了,特别是当该文件夹下的模块特别多的时候就非常有用了。
__all__= ['file1','file2']

三、总结
关于自定义package的导入,我们需要理解的还有很多,只有彻底的理解了其中的道理,我们才能真正的学会去使用它。
沉淀再出发:在python3中导入自定义的包的更多相关文章
- 沉淀再出发:java中线程池解析
沉淀再出发:java中线程池解析 一.前言 在多线程执行的环境之中,如果线程执行的时间短但是启动的线程又非常多,线程运转的时间基本上浪费在了创建和销毁上面,因此有没有一种方式能够让一个线程执行完自己的 ...
- 沉淀再出发:java中的HashMap、ConcurrentHashMap和Hashtable的认识
沉淀再出发:java中的HashMap.ConcurrentHashMap和Hashtable的认识 一.前言 很多知识在学习或者使用了之后总是会忘记的,但是如果把这些只是背后的原理理解了,并且记忆下 ...
- 沉淀再出发:java中的CAS和ABA问题整理
沉淀再出发:java中的CAS和ABA问题整理 一.前言 在多并发程序设计之中,我们不得不面对并发.互斥.竞争.死锁.资源抢占等等问题,归根到底就是读写的问题,有了读写才有了增删改查,才有了所有的一切 ...
- 沉淀,再出发:python中的pandas包
沉淀,再出发:python中的pandas包 一.前言 python中有很多的包,正是因为这些包工具才使得python能够如此强大,无论是在数据处理还是在web开发,python都发挥着重要的作用,下 ...
- 沉淀,再出发:sublime中快捷键和html标签的使用和生成以及使用markdown
沉淀,再出发:sublime中快捷键和html标签的使用和生成以及使用markdown 一.前言 工欲善其事,必先利其器.在软件代码的编写中,一定要知道IDE或者编辑器的快捷键的使用,这样可以提高很多 ...
- 沉淀再出发:java中注解的本质和使用
沉淀再出发:java中注解的本质和使用 一.前言 以前XML是各大框架的青睐者,它以松耦合的方式完成了框架中几乎所有的配置,但是随着项目越来越庞大,XML的内容也越来越复杂,维护成本变高.于是就有人提 ...
- 沉淀再出发:关于java中的AQS理解
沉淀再出发:关于java中的AQS理解 一.前言 在java中有很多锁结构都继承自AQS(AbstractQueuedSynchronizer)这个抽象类如果我们仔细了解可以发现AQS的作用是非常大的 ...
- 沉淀再出发:java中的equals()辨析
沉淀再出发:java中的equals()辨析 一.前言 关于java中的equals,我们可能非常奇怪,在Object中定义了这个函数,其他的很多类中都重载了它,导致了我们对于辨析其中的内涵有了混淆, ...
- 沉淀再出发:如何在eclipse中查看java的核心代码
沉淀再出发:如何在eclipse中查看java的核心代码 一.前言 很多时候我们在eclipse中按F3键打算查看某一个系统类的定义的时候,总是弹出找不到类这样的界面,这里我们把核心对应的代码加进 ...
随机推荐
- [中英对照]The sysfs Filesystem | sysfs文件系统
The sysfs Filesystem | sysfs文件系统 Abstract | 摘要 sysfs is a feature of the Linux 2.6 kernel that allow ...
- Esper简介
1. CEP(Complex Event Processing, 复杂事件处理) 事件(Event)一般情况下指的是一个系统中正在发生的事,事件可能发生在系统的各个层面上,它可以是某个动作,例如客户下 ...
- Uboot流程分析
1. uboot的配置分析 1).配置入口分析 首先分析配置: 从make mx6dl_sabresd_android_config可知配置项,搜索Makefile: mx6solo_sabresd_ ...
- Delphi下OpenGL2d绘图(04)-画四边形
一.前言 画四边形基本上与前几遍文字代码是相同.区别在于glBegin()的参数“GL_QUADS”.绘制的框架代码可以使用 Delphi下OpenGL2d绘图(01)-初始化 中的代码.修改的部份为 ...
- Eclipse常用快捷键之代码编辑篇
Eclipse是Java开发常用的IDE工具,熟练使用快捷键可以提高开发效率,使得编码工作事半功倍,下面介绍几种常用的代码编辑和补全工具 重命名快捷键:Alt+Shift+R 可用于类名,方法名,属性 ...
- SQL 之连接查询
概述:INNER JOIN.LEFT JOIN.LIGHT JOIN.FULL JOIN. 一.INNER JOIN INNER JOIN 关键字在表中存在至少一个匹配时返回行. 语法: select ...
- 初识JSP,第一天
1.什么JSP java Server Page java 服务端的页面,它和servlet 一样可以提供动态的html 响应. 不同的是 servlet 以 java 代码 为主 jsp 以html ...
- 五、线程本地ThreadLocal
一.线程私有 在多线程情况下,对于一个共享的数据可能会产生线程安全问题.最简单的解决办法就是堆访问共享数据的时候加锁,但我们知道加锁是很影响效率的,尤其是像数据库连接这样耗费资源较多的情况下,加锁就意 ...
- tomcat-虚拟目录的映射
虚拟目录的映射 1.新建 ${tomcat安装目录}\conf\Catalina\localhost\xxx.xml 文件. 文件内容: <Context path="/xxx&qu ...
- unity3d之使用技巧
知乎 project.hierarchy折叠打开全部文件夹——alt +方向键