Python爬虫与一汽项目【三】爬取中国五矿集团采购平台
网站地址:http://ec.mcc.com.cn/b2b/web/two/indexinfoAction.do?actionType=showMoreCgxx&xxposition=cgxx
本来以为这是个老老实实的get请求,谁知道在翻页的时候发现提交请求的方式是post,
好在首页用get方式可以轻松获取到html源码,没有像之前的东方电气那么烦人。
在这里采用了简单的post提交方式,因此观察翻页即可发现,页面的改变和FormData有关
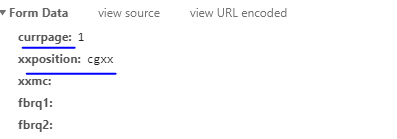
通过更改formdata中的currpage即可实现翻页提交。
使用post方式时,数据放在data或者body中,不能放在url中,放在url中将被忽略。
urllib2用一个Request对象来映射所提出的HTTP请求。
通过请求的地址创建一个Request对象,
通过调用urlopen并传入Request对象,将返回一个相关请求response对象,
这个应答对象如同一个文件对象,所以要在Response中调用.read()
def get_one_page(url,data):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
#将传过来的data进行编码,变成bytes格式的数据
dataEncode = urllib.parse.urlencode(data).encode('utf-8')
#获取网页响应内容,用到了urllib模块
request = urllib.request.Request(url=url, headers=headers,data=dataEncode)
response = urllib.request.urlopen(request)
#获取应答对象
return response.read().decode('utf-8')
except RequestException:
return None
主方法中构造data
def main():
url = "http://ec.mcc.com.cn/b2b/web/two/indexinfoAction.do?actionType=showMoreCgxx&xxposition=cgxx"
#构造post表单所提交的数据
data = {
'currpage': 1,
'xxposition': 'cgxx'
}
html = get_one_page(url,data)
print(html)
接下来可以通过循环构造最大页数,并将最大页传给data,循环获取每一页的内容即可。
#直接修改data的value值即可
for i in range(2,page_num+1):
data['currpage'] = i
Python爬虫与一汽项目【三】爬取中国五矿集团采购平台的更多相关文章
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- Python爬虫与一汽项目【一】爬取中海油,邮政,国家电网问题总结
项目介绍 中国海洋石油是爬取的第一个企业,之后依次爬取了,国家电网,中国邮政,这三家公司的源码并没有多大难度, 采购信息地址: 国家电网电子商务平台 http://ecp.sgcc.com.cn/pr ...
- Python爬虫与一汽项目【综述】
项目来源 这个爬虫项目是 去年实验室去一汽后的第一个项目(基本交工,现在处于更新维护阶段).内容大概是,获取到全国31个省份政府的关于汽车的招标公告,再用图形界面的方式展示爬虫内容.在完成政府招标采购 ...
- 小白学 Python 爬虫(25):爬取股票信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 【python爬虫】一个简单的爬取百家号文章的小爬虫
需求 用"老龄智能"在百度百家号中搜索文章,爬取文章内容和相关信息. 观察网页 红色框框的地方可以选择资讯来源,我这里选择的是百家号,因为百家号聚合了来自多个平台的新闻报道.首先看 ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- Python 爬虫练习(二)爬取补天公益SRC厂商域名URL (2017年11月22日)
介绍下: 补天是国内知名的漏洞响应平台,旨在企业和白帽子共赢. 白帽子在这里提交厂商漏洞,获得库币和荣誉,厂商从这里发布众测.获取漏洞报告和修复建议. 在2017年3月份之前,补天的厂商域名URL是非 ...
随机推荐
- 输入二进制数转换成十进制数(在cin>>和cin.get()上掉的坑)
题目:输入一个二进制数转换成十进制. 题目分析:书上说,在一般情况下,c++的键盘输入可以识别是十进制数.八进制数和十六进制数,因此输入的二进制数据要作为字符处理.(其实我觉得数字也没问题吧). 正确 ...
- Python自动化培训第一周学习总结
Python自动化培训第一周学习结束,看视频复习,把作业完成了. 总体来说,开卷有益. 首先,工具真是好东西,能够极大提升效率,也是人区别于动物所在.想起前任大领导对工具的不屑,本质也是对效率的不屑, ...
- 对SDE中空要素类插入要素,完成后显示的图层特别小
原因是缺少图层Extent或者Extent发生变化,插入完成后需要对图层的Extent进行更新. 调用IFeatureClassManage. UpdateExtent更新范围 参考链接: https ...
- Tengine+Lua+GraphicsMagick
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! 使用 Tengine+Lua+GraphicsMagick 实现图片自动裁剪缩放 需求 : 图片 ...
- Confluence实现附件下载权限的控制
背景: 公司为了方便的管理过程文档,搭建了一个Confluence服务器,版本6.9.在使用过程中,需要按照用户对空间中上传的附件进行下载权限控制. 解决过程及处理方案: 一.Confluence中导 ...
- HANA SQL备忘录
1.改变元素列类型 ALTER TABLE <TABLE_NAME> ALTER (<COLUMN_NAME> <COLUMN_TYPE>);
- Redis在windows下安装与配置
一.安装Redis 1. Redis官网下载地址:http://redis.io/download,下载相应版本的Redis,在运行中输入cmd,然后把目录指向解压的Redis目录. 2.启动服务命令 ...
- numpy(三)
广播: x= np.arange(12).reshape((3,4)) a= np.arange(3) b=np.arange(3)[;,np.newaxis] c=a+b a,b会扩散成公共的形状进 ...
- shiro使用redis作为缓存,出现要清除缓存时报错 java.lang.Exception: Failed to deserialize at org.crazycake.shiro.SerializeUtils.deserialize(SerializeUtils.java:41) ~[shiro-redis-2.4.2.1-RELEASE.jar:na]
shiro使用redis作为缓存,出现要清除缓存时报错 java.lang.Exception: Failed to deserialize at org.crazycake.shiro.Serial ...
- jenkin如何实现web版本控制&回退
jenkins本身作为一款运维利器,具备 1. 持续集成 (Continuous integration) 2. 持续交付(Continuous delivery) 3. 持续部署(continuou ...