【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志
通过oozie job id可以查看流程详细信息,命令如下:
oozie job -info 0012077-180830142722522-oozie-hado-W
流程详细信息如下:
Job ID : 0012077-180830142722522-oozie-hado-W
------------------------------------------------------------------------------------------------------------------------------------
Workflow Name : test_wf
App Path : hdfs://hdfs_name/oozie/test_wf.xml
Status : KILLED
Run : 0
User : hadoop
Group : -
Created : 2018-09-25 02:51 GMT
Started : 2018-09-25 02:51 GMT
Last Modified : 2018-09-25 02:53 GMT
Ended : 2018-09-25 02:53 GMT
CoordAction ID: -
Actions
------------------------------------------------------------------------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@:start: OK - OK -
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@test_spark_task ERROR application_1537326594090_5663FAILED/KILLEDJA018
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@Kill OK - OK E0729
------------------------------------------------------------------------------------------------------------------------------------
失败的任务定义如下
<action name="test_spark_task">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>${job_tracker}</job-tracker>
<name-node>${name_node}</name-node>
<master>${jobmaster}</master>
<mode>${jobmode}</mode>
<name>${jobname}</name>
<class>${jarclass}</class>
<jar>${jarpath}</jar>
<spark-opts>--executor-memory 4g --executor-cores 2 --num-executors 4 --driver-memory 4g</spark-opts>
</spark>
在yarn上可以看到application_1537326594090_5663对应的application如下
application_1537326594090_5663 hadoop oozie:launcher:T=spark:W=test_wf:A=test_spark_task:ID=0012077-180830142722522-oozie-hado-W Oozie Launcher
查看application_1537326594090_5663日志发现
2018-09-25 10:52:05,237 [main] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1537326594090_5664
yarn上application_1537326594090_5664对应的application如下
application_1537326594090_5664 hadoop TestSparkTask SPARK
即application_1537326594090_5664才是Action对应的spark任务,为什么中间会多一步,类结构和核心代码详见 https://www.cnblogs.com/barneywill/p/9895225.html
简要来说,Oozie执行Action时,即ActionExecutor(最主要的子类是JavaActionExecutor,hive、spark等action都是这个类的子类),JavaActionExecutor首先会提交一个LauncherMapper(map任务)到yarn,其中会执行LauncherMain(具体的action是其子类,比如JavaMain、SparkMain等),spark任务会执行SparkMain,在SparkMain中会调用org.apache.spark.deploy.SparkSubmit来提交任务
如果提交的是spark任务,那么按照上边的方法就可以跟踪到实际任务的applicationId;
如果你提交的hive2任务,实际是用beeline启动,从hive2开始,beeline命令的日志已经简化,不像hive命令可以看到详细的applicationId和进度,这时有两种方法:
1)修改hive代码,使得beeline命令和hive命令一样有详细日志输出
详见:https://www.cnblogs.com/barneywill/p/10185949.html
2)根据application tag手工查找任务
oozie在使用beeline提交任务时,会添加一个mapreduce.job.tags参数,比如
--hiveconf
mapreduce.job.tags=oozie-9f896ad3d40c261235dc6858cadb885c
但是这个tag从yarn application命令中查不到,只能手工逐个查找(实际启动的任务会在当前LuancherMapper的applicationId上递增),
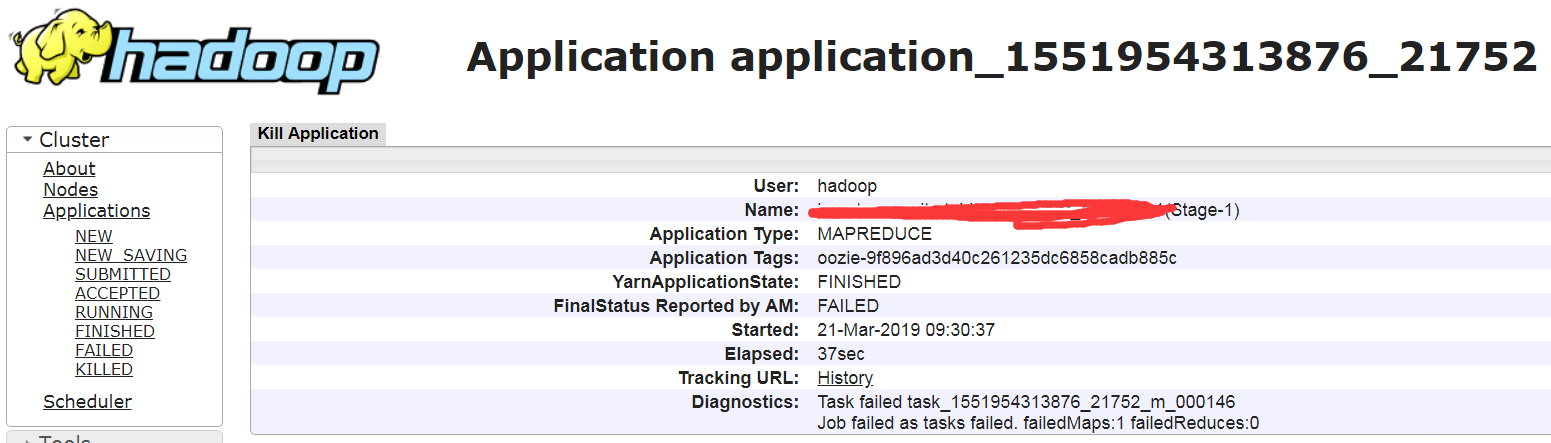
然后就可以看到实际启动的applicationId了
另外还可以从job history server上看到application的详细信息,比如configuration、task等
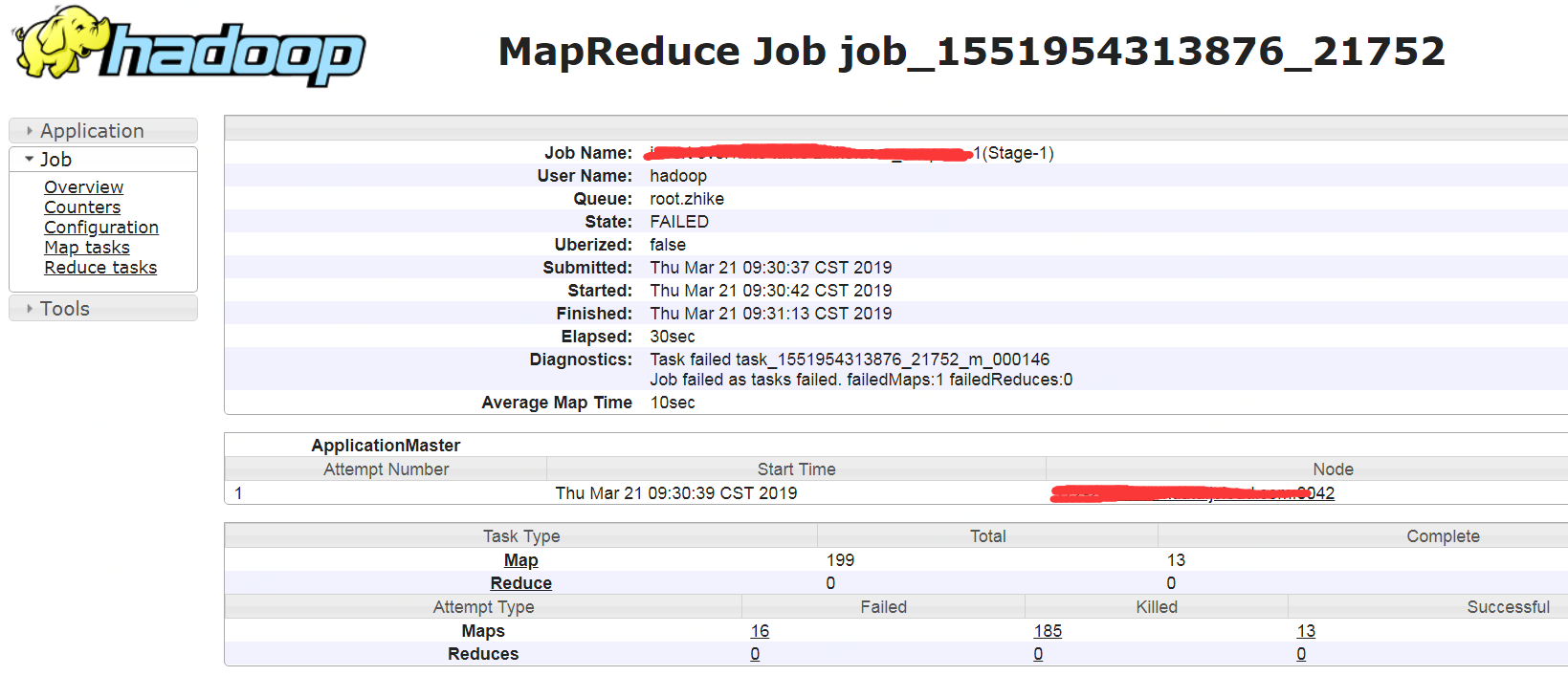
查看hive任务执行的完整sql详见:https://www.cnblogs.com/barneywill/p/10083731.html
【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志的更多相关文章
- 【原创】大叔经验分享(46)用户提交任务到yarn报错
用户提交任务到yarn时有可能遇到下面的错误: 1) Requested user anything is not whitelisted and has id 980,which is below ...
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- 【原创】经验分享:一个小小emoji尽然牵扯出来这么多东西?
前言 之前也分享过很多工作中踩坑的经验: 一个线上问题的思考:Eureka注册中心集群如何实现客户端请求负载及故障转移? [原创]经验分享:一个Content-Length引发的血案(almost.. ...
- 【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql
spark 2.1.1 hive正在执行中的sql可以很容易的中止,因为可以从console输出中拿到当前在yarn上的application id,然后就可以kill任务, WARNING: Hiv ...
- 【原创】大叔经验分享(5)oozie提交spark任务如何添加依赖
spark任务添加依赖的方式: 1 如果是local方式运行,可以通过--jars来添加依赖: 2 如果是yarn方式运行,可以通过spark.yarn.jars来添加依赖: 这两种方式在oozie上 ...
- 【原创】大叔经验分享(49)hue访问hdfs报错/hue访问oozie editor页面卡住
hue中使用hue用户(hue admin)访问hdfs报错: Cannot access: /. Note: you are a Hue admin but not a HDFS superuser ...
- 【原创】大叔经验分享(48)oozie中通过shell执行impala
oozie中通过shell执行impala,脚本如下: $ cat test_impala.sh #!/bin/sh /usr/bin/kinit -kt /tmp/impala.keytab imp ...
- 【原创】大叔经验分享(59)kudu查看table size
kudu并没有命令可以直接查看每个table占用的空间,可以从cloudera manager上间接查看 CM is scrapping and aggregating the /metrics pa ...
- 【原创】大叔经验分享(21)yarn中查看每个应用实时占用的内存和cpu资源
在yarn中的application详情页面 http://resourcemanager/cluster/app/$applicationId 或者通过application命令 yarn appl ...
随机推荐
- Kubernetes的本质
在前面的四篇文章中,我以 Docker 项目为例,一步步剖析了 Linux 容器的具体实现方式.通过这 些讲解你应该能够明白:一个“容器”,实际上是一个由 Linux Namespace.Linux ...
- spark-MLlib之协同过滤ALS
协同过滤与推荐 协同过滤是一种根据用户对各种产品的交互与评分来推荐新产品的推荐系统技术. 协同过滤引入的地方就在于它只需要输入一系列用户/产品的交互记录: 无论是显式的交互(例如在购物网站 ...
- webservice异常
webservice的一个常见异常: [SOAPException: faultCode=SOAP-ENV:Client; msg=Error parsing HTTP status line &qu ...
- Package与Activity简介
Package Package 包.只是在我们的app中这个Package是唯一的,就像你身份证号码一样.在我们做app自动化时,我们就需要知道他的Package,我们知道了Package那么也就知道 ...
- NPOI “发现 中的部分内容有问题,是否要恢复此工作薄的内容?如果信任此工作薄的来源。。。”的问题的解决方法
网上说的方法是调整Sheet可见和顺序:https://blog.csdn.net/hulihui/article/details/21196951 stackoverflow给出的解释是:单元格存储 ...
- jsp篇 之 Jsp中的内置对象和范围对象
Jsp中的内置对象: 在jsp页面代码中不需要声明,直接可以使用的对象. 一共有[9个内置对象]可以直接使用. 对象类型 名字 PageContext pageC ...
- Django_modelform组件
modelForm 组件 概念 将数据库与form 组件结合用起来的中间插件 与 form 组件的区别 form组件的难处: form 可以实现 对数据的验证以及 form 的表单标签的生成 但是她做 ...
- python学习day14 装饰器(二)&模块
装饰器(二)&模块 #普通装饰器基本格式 def wrapper(func): def inner(): pass return func() return inner def func(): ...
- SQL学习指南第二篇
使用集合 union操作符(组合查询) 多数 SQL 查询只包含从一个或多个表中返回数据的单条 SELECT 语句.但是,SQL 也允许执行多个查询(多条 SELECT 语句),并将结果作为一个查询结 ...
- 来了解质量管理工具——质量屋(HOQ)
质量屋(The House Of Quality),又名HOQ,它是质量功能配置(QFD)的核心.一般QFD的学习会涉及到.同时HOQ也是项目管理十大知识领域领域中质量管理工具中的一种,今天我们就来了 ...