【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志
通过oozie job id可以查看流程详细信息,命令如下:
oozie job -info 0012077-180830142722522-oozie-hado-W
流程详细信息如下:
Job ID : 0012077-180830142722522-oozie-hado-W
------------------------------------------------------------------------------------------------------------------------------------
Workflow Name : test_wf
App Path : hdfs://hdfs_name/oozie/test_wf.xml
Status : KILLED
Run : 0
User : hadoop
Group : -
Created : 2018-09-25 02:51 GMT
Started : 2018-09-25 02:51 GMT
Last Modified : 2018-09-25 02:53 GMT
Ended : 2018-09-25 02:53 GMT
CoordAction ID: -
Actions
------------------------------------------------------------------------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@:start: OK - OK -
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@test_spark_task ERROR application_1537326594090_5663FAILED/KILLEDJA018
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@Kill OK - OK E0729
------------------------------------------------------------------------------------------------------------------------------------
失败的任务定义如下
<action name="test_spark_task">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>${job_tracker}</job-tracker>
<name-node>${name_node}</name-node>
<master>${jobmaster}</master>
<mode>${jobmode}</mode>
<name>${jobname}</name>
<class>${jarclass}</class>
<jar>${jarpath}</jar>
<spark-opts>--executor-memory 4g --executor-cores 2 --num-executors 4 --driver-memory 4g</spark-opts>
</spark>
在yarn上可以看到application_1537326594090_5663对应的application如下
application_1537326594090_5663 hadoop oozie:launcher:T=spark:W=test_wf:A=test_spark_task:ID=0012077-180830142722522-oozie-hado-W Oozie Launcher
查看application_1537326594090_5663日志发现
2018-09-25 10:52:05,237 [main] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1537326594090_5664
yarn上application_1537326594090_5664对应的application如下
application_1537326594090_5664 hadoop TestSparkTask SPARK
即application_1537326594090_5664才是Action对应的spark任务,为什么中间会多一步,类结构和核心代码详见 https://www.cnblogs.com/barneywill/p/9895225.html
简要来说,Oozie执行Action时,即ActionExecutor(最主要的子类是JavaActionExecutor,hive、spark等action都是这个类的子类),JavaActionExecutor首先会提交一个LauncherMapper(map任务)到yarn,其中会执行LauncherMain(具体的action是其子类,比如JavaMain、SparkMain等),spark任务会执行SparkMain,在SparkMain中会调用org.apache.spark.deploy.SparkSubmit来提交任务
如果提交的是spark任务,那么按照上边的方法就可以跟踪到实际任务的applicationId;
如果你提交的hive2任务,实际是用beeline启动,从hive2开始,beeline命令的日志已经简化,不像hive命令可以看到详细的applicationId和进度,这时有两种方法:
1)修改hive代码,使得beeline命令和hive命令一样有详细日志输出
详见:https://www.cnblogs.com/barneywill/p/10185949.html
2)根据application tag手工查找任务
oozie在使用beeline提交任务时,会添加一个mapreduce.job.tags参数,比如
--hiveconf
mapreduce.job.tags=oozie-9f896ad3d40c261235dc6858cadb885c
但是这个tag从yarn application命令中查不到,只能手工逐个查找(实际启动的任务会在当前LuancherMapper的applicationId上递增),
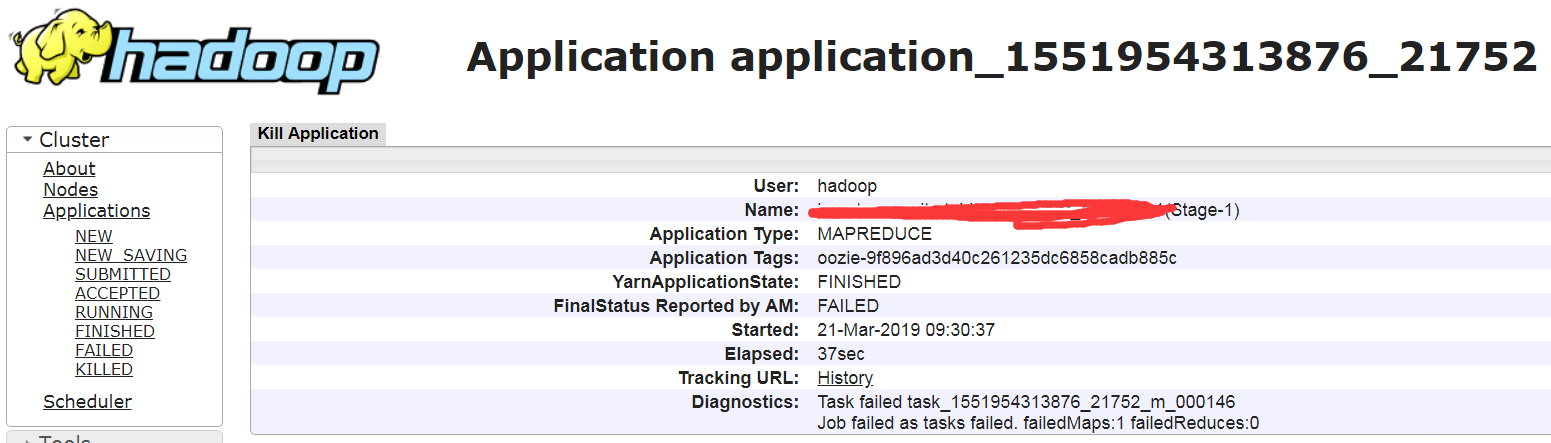
然后就可以看到实际启动的applicationId了
另外还可以从job history server上看到application的详细信息,比如configuration、task等
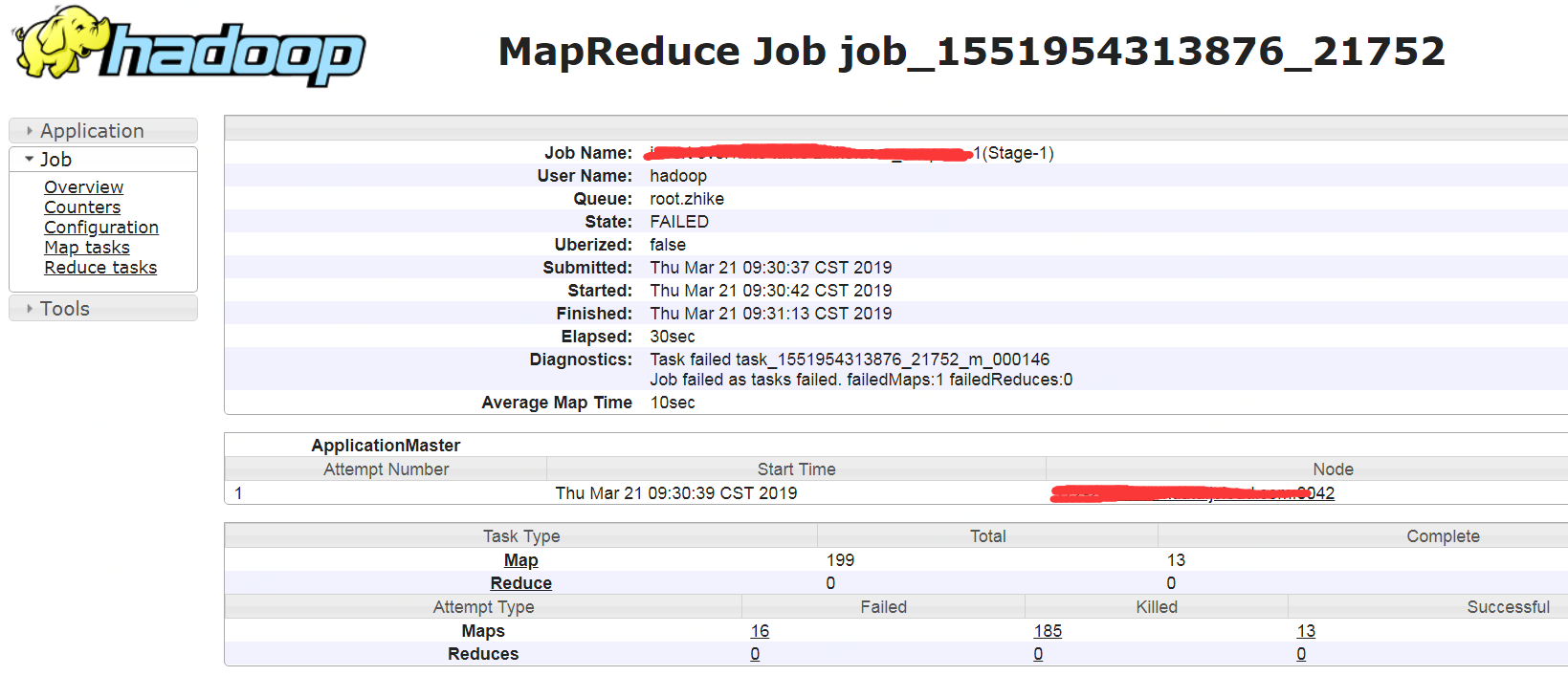
查看hive任务执行的完整sql详见:https://www.cnblogs.com/barneywill/p/10083731.html
【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志的更多相关文章
- 【原创】大叔经验分享(46)用户提交任务到yarn报错
用户提交任务到yarn时有可能遇到下面的错误: 1) Requested user anything is not whitelisted and has id 980,which is below ...
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- 【原创】经验分享:一个小小emoji尽然牵扯出来这么多东西?
前言 之前也分享过很多工作中踩坑的经验: 一个线上问题的思考:Eureka注册中心集群如何实现客户端请求负载及故障转移? [原创]经验分享:一个Content-Length引发的血案(almost.. ...
- 【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql
spark 2.1.1 hive正在执行中的sql可以很容易的中止,因为可以从console输出中拿到当前在yarn上的application id,然后就可以kill任务, WARNING: Hiv ...
- 【原创】大叔经验分享(5)oozie提交spark任务如何添加依赖
spark任务添加依赖的方式: 1 如果是local方式运行,可以通过--jars来添加依赖: 2 如果是yarn方式运行,可以通过spark.yarn.jars来添加依赖: 这两种方式在oozie上 ...
- 【原创】大叔经验分享(49)hue访问hdfs报错/hue访问oozie editor页面卡住
hue中使用hue用户(hue admin)访问hdfs报错: Cannot access: /. Note: you are a Hue admin but not a HDFS superuser ...
- 【原创】大叔经验分享(48)oozie中通过shell执行impala
oozie中通过shell执行impala,脚本如下: $ cat test_impala.sh #!/bin/sh /usr/bin/kinit -kt /tmp/impala.keytab imp ...
- 【原创】大叔经验分享(59)kudu查看table size
kudu并没有命令可以直接查看每个table占用的空间,可以从cloudera manager上间接查看 CM is scrapping and aggregating the /metrics pa ...
- 【原创】大叔经验分享(21)yarn中查看每个应用实时占用的内存和cpu资源
在yarn中的application详情页面 http://resourcemanager/cluster/app/$applicationId 或者通过application命令 yarn appl ...
随机推荐
- 使用.net core搭建文件服务器
标题之所以带上.net core,而不是.net就是由于两者在类库的使用以及部署环境有很大的差别,所以特此说明. 长话短说,直接开始! 1.新建一个.net core项目,版本是2.0,为了方便就建一 ...
- jenkins集成python时出现"Non-ASCII character '\xe6' in file"错误解决方法
我的问题: 使用python3.5,在Linux环境下手动执行python文件时不报错,但是用jenkins自动执行时就报"Non-ASCII character '\xe6' in fil ...
- SQL拼接字符串时单引号转义问题 单引号转义字符
要拼接一个单引号到已有字符串前后, 开始以为(错误)可以用 \ 转义,如下: '\''+ str+'\'' 看颜色就知道是不行的. 正确方法是两个单引号就转义为单引号,如下: ''''+str+'' ...
- Shell脚本中的break continue exit return
转自:http://www.cnblogs.com/guosj/p/4571239.html break结束并退出循环 continue在循环中不执行continue下面的代码,转而进入下一轮循环 e ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 第四章· Redis的事务、锁及管理命令
一.事务介绍 二.Redis乐观锁介绍 三.Redis管理命令 一.事务介绍 Redis的事务与关系型数据库中的事务区别 1)在MySQL中讲过的事务,具有A.C.I.D四个特性 Atomic(原子性 ...
- Android技术框架——Dagger2
Dagger2 是一个Android依赖注入框架.没错依赖注入,学习过spring的同学看到这词,应该是挺熟悉的.当然既然是Android的课题,我们就来聊聊Dagger2 ,android开发当前非 ...
- MySQL-基本命令
一.登录命令 mysql -r 用户名 -p 密码 二.创建用户 create user '用户名'@'主机名' identified by '密码' #主机名:指定该用户在哪个主机上可以登陆,如果是 ...
- CSS3文字、背景与列表
一.文本相关属性 1.字体 (1)字体设置 在HTML中,字体通过<font face="字体名称">来设置.在CSS中字体通过font-family属性来控制,里面可 ...
- 第六十五天 js操作
1.闭包 // 函数的嵌套定义,定义在内部的函数都称之为 闭包 // 1.一个函数要使用另一个函数的局部变量 // 2.闭包会持久化包裹自身的函数的局部变量 // 3.解决循环绑定 function ...