LAB1 partV
partV


bash ./test-ii.sh 直接测试程序结果。
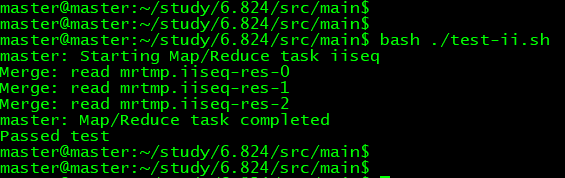
ii.go
package main import (
"os"
"strings"
"unicode"
"strconv"
)
import "fmt"
import "mapreduce" // The mapping function is called once for each piece of the input.
// In this framework, the key is the name of the file that is being processed,
// and the value is the file's contents. The return value should be a slice of
// key/value pairs, each represented by a mapreduce.KeyValue.
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
f := func(c rune) bool {
return !unicode.IsLetter(c)
}
rst := make([]mapreduce.KeyValue, ) keys := strings.FieldsFunc(value, f)
for _, key := range keys {
kv := mapreduce.KeyValue{ Key: key, Value:document}
rst = append(rst, kv)
}
return rst
} // The reduce function is called once for each key generated by Map, with a
// list of that key's string value (merged across all inputs). The return value
// should be a single output value for that key.
func reduceF(key string, values []string) string {
// Your code here (Part V).
vm := make(map[string]string)
var rst []string
for _, value := range values {
if _, ok := vm[value]; !ok {
rst = append(rst, value)
vm[value] = value
}
} vl := strings.Join(rst, ",")
return strconv.Itoa(len(rst)) + " " + vl
} // Can be run in 3 ways:
// 1) Sequential (e.g., go run wc.go master sequential x1.txt .. xN.txt)
// 2) Master (e.g., go run wc.go master localhost:7777 x1.txt .. xN.txt)
// 3) Worker (e.g., go run wc.go worker localhost:7777 localhost:7778 &)
func main() {
if len(os.Args) < {
fmt.Printf("%s: see usage comments in file\n", os.Args[])
} else if os.Args[] == "master" {
var mr *mapreduce.Master
if os.Args[] == "sequential" {
mr = mapreduce.Sequential("iiseq", os.Args[:], , mapF, reduceF)
} else {
mr = mapreduce.Distributed("iiseq", os.Args[:], , os.Args[])
}
mr.Wait()
} else {
mapreduce.RunWorker(os.Args[], os.Args[], mapF, reduceF, , nil)
}
}
上面LAB1 五部分一起测试。
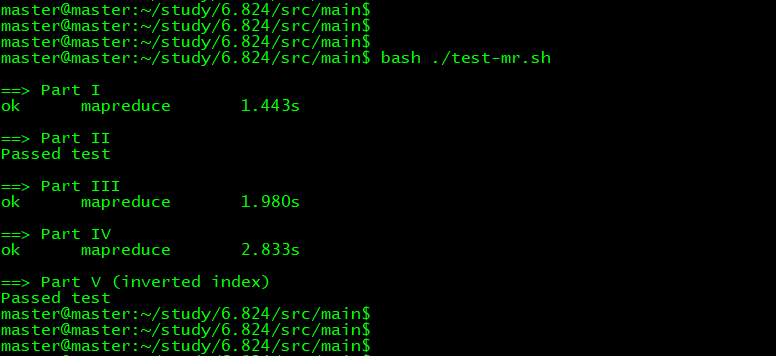
LABI 完成。
LAB1 partV的更多相关文章
- 6.828 lab1 bootload
MIT6.828 lab1地址:http://pdos.csail.mit.edu/6.828/2014/labs/lab1/ 第一个练习,主要是让我们熟悉汇编,嗯,没什么好说的. Part 1: P ...
- Machine Learning #Lab1# Linear Regression
Machine Learning Lab1 打算把Andrew Ng教授的#Machine Learning#相关的6个实验一一实现了贴出来- 预计时间长度战线会拉的比較长(毕竟JOS的7级浮屠还没搞 ...
- ucore lab1 bootloader学习笔记
---恢复内容开始--- 开机流程回忆 以Intel 80386为例,计算机加电后,CPU从物理地址0xFFFFFFF0(由初始化的CS:EIP确定,此时CS和IP的值分别是0xF000和0xFFF0 ...
- 6.824 LAB1 环境搭建
MIT 6.824 LAB1 环境搭建 vmware 虚拟机 linux ubuntu server 安装 go 官方安装步骤: 下载此压缩包并提取到 /usr/local 目录,在 /usr/l ...
- 软件测试:lab1.Junit and Eclemma
软件测试:lab1.Junit and Eclemma Task: Install Junit(4.12), Hamcrest(1.3) with Eclipse Install Eclemma wi ...
- MIT 6.824 lab1:mapreduce
这是 MIT 6.824 课程 lab1 的学习总结,记录我在学习过程中的收获和踩的坑. 我的实验环境是 windows 10,所以对lab的code 做了一些环境上的修改,如果你仅仅对code 感兴 ...
- 清华大学OS操作系统实验lab1练习知识点汇总
lab1知识点汇总 还是有很多问题,但是我觉得我需要在查看更多资料后回来再理解,学这个也学了一周了,看了大量的资料...还是它们自己的80386手册和lab的指导手册觉得最准确,现在我就把这部分知识做 ...
- JOS lab1 part2 分析
lab1的Exercise 2就是让我们熟悉gdb的si操作,并知道BIOS的几条指令在做什么就够了,所以我们也会尽可能的去分析每一行代码. 首先进入到6.8282/lab这个目录下,输入指令make ...
- MIT 操作系统实验 MIT JOS lab1
JOS lab1 首先向MIT还有K&R致敬! 没有非常好的开源环境我不可能拿到这么好的东西. 向每个与我一起交流讨论的programmer致谢!没有道友一起死磕.我也可能会中途放弃. 跟丫死 ...
随机推荐
- OO第四次作业
一.论述测试与正确性论证的差异 我认为论述测试代表从理论的角度来进行运行正确性的判断,而正确性测试则是从实践的角度来看待程序的正确性问题.两者之间有着明显的差异. 正确性论证是仅仅从代码的逻辑结构方面 ...
- Vue中通过v-for动态添加图片地址
由于组件化问题,webpake在打包以后,src目录下的assets里面存放的img图片,路径已经更换.很多入坑的前端程序员在使用的时候,可能专破头也弄不清地址是什么个情况: 这里在使用vue-cli ...
- Holer实现手机APP应用外网访问本地WEB应用
手机APP应用公网访问内网WEB应用 本地安装了WEB服务端,手机APP应用只能在局域网内访问本地WEB,怎样使手机APP应用从公网也能访问本地WEB? 本文将介绍使用holer实现的具体步骤. 1. ...
- HttpInvoker客户端动态调用Demo
private static <T> T getHttpInvokerService(String serverUrl, Class<T> serviceInterface) ...
- Vue.js模板语法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- QTCPSOCKET 客户端已连接 而服务器无响应
最近在使用qt coding一个项目时,使用到了qtcpsocket模块来编写客户端与服务器.在windows平台下还能正常工作,但是在ubuntu平台下,客户端提示已连接时,服务器却没有响应.经过排 ...
- HDU - 6127: Hard challenge(扫描线,atan)
pro:给定N个二维平面的关键点,保证两点连线不经过原点.现在让你安排一条经过原点,但是不经过关键点的直线,使得两边的和的乘积最大. sol:由于连线不经过原点,所以我们极角排序即可. 具体:因为我们 ...
- VMware 虚拟机安装-->wrf、cmaq安装
微信关注公众号 “软件安装管家” 下载并安装VMware 下面简要记载我的安装和设置步骤: 下载解压,右键以管理员方式运行 安装好了之后 双击桌面 的VMware 输入许可证密钥:AA510-2DF1 ...
- centos 7 中安装 mysql 5.7
centos 7 中安装 mysql 5.7 环境说明: 查看centos的版本:cat /etc/redhat-release 安装和配置步骤: 下载 mysql 源安装包: sudo curl - ...
- vs2015打开Dialog出现HRESULT:0x8CE0000B
关闭项目 在工程目录找到.vc.db文件删除