Java中java.util.concurrent包下的4中线程池代码示例
先来看下ThreadPool的类结构
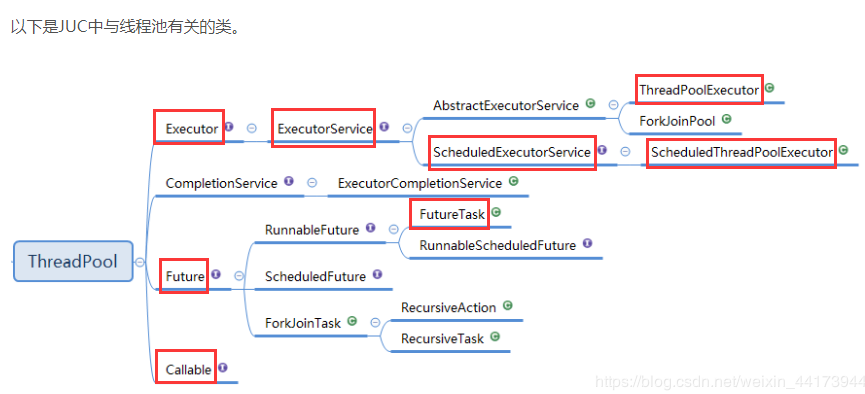
其中红色框住的是常用的接口和类(图片来自:https://blog.csdn.net/panweiwei1994/article/details/78617117?from=singlemessage)
为什么需要线程池呢?
我们在创建线程的时候,一般使用new Thread(),但是每次在启动一个线程的时候就new 一个Thread对象,会让性能变差(spring不都使用IOC管理对象了嘛)。还有其他的一些弊端:
- 可能会造成无限创建线程对象,对象之间相互竞争资源,造成过多占用资源而宕机。
- 缺乏相关功能,如定时执行、定期执行、线程中断。
使用线程池的避免这些事情:
- 重用存在的线程,减少对象创建、消亡的开销,性能佳。
- 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
- 提供定时执行、定期执行、单线程、并发数控制等功能。
线程池的种类:
java通过Executor是提供4种线程池,分别为:
1)newCachedThreadPool:创建一个可缓存的线程池,有任务来临时如果线程池中有空闲的线程,那么就使用空闲的线程执行任务(即线程是可以复用),如果没有空闲线程则创建新的线程执行任务。
2)newFixedThreadPool:创建一个定长的线程池,线程池的线程数量固定,当任务来临,但是又没有空闲线程,则把任务放入队列中等待直到有空闲线程来处理它。
3)newScheduledThreadPool:创建一个定长的线程,但是能支持定时或周期性的执行。
4)newSingleThreadPool:创建一个单线程化的线程池,线程池中只有一个唯一的线程来执行任务,保证所有任务按照指定顺序(FIFO,LIFO,优先级)执行。
示例:
1)newCachedThreadPool
/**
* 创建可缓存的线程池,线程池的线程可以重复利用,除非任务来不及处理就会创建新的线程。
*/
public static void createCachedThreadPool(){
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
//在这里使主线程停下来,让启动的线程执行完Syso操作
//并且有时间回收线程以确保下次启动的线程还是上次的线程
Thread.sleep(index * 1000);//
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
/* try {
//这里让启动的线程睡眠,保证下次启动的线程是新的线程,不是此时睡眠的。
Thread.sleep(index * 1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}*/
System.out.println(Thread.currentThread().getName() + " " + index);
}
}); }
}
执行结果:
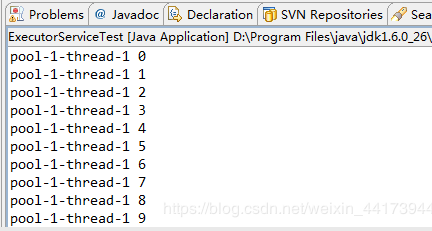
结果显示,执行for循环输出的线程都是同一个,线程重复使用了。
把注释的地方放开,并且注释上面的睡眠,执行结果:
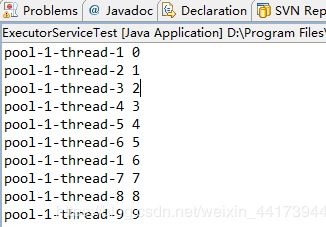
结果显示的是不同的线程名称执行的for循环,对比上面的执行结果的线程名称,可以得出结论:有任务来临时如果线程池中有空闲的线程,那么就使用空闲的线程执行任务(即线程是可以复用),如果没有空闲线程则创建新的线程执行任务。
2)newFixedThreadPool
/**
* 创建固定长度的线程池,超出的任务会在队列中进行等待,直到有线程空出来来执行。
*/
public static void createFixedThreadPool() {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + "," + index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
运行结果:
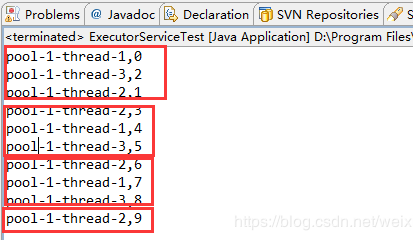
创建了固定长度是3的线程池,输出前3行之后,发现线程都在sleep(),要执行的输出任务没有找到对应的执行线程,任务就会放入队列中进行等待,等待某个线程执行完毕后,再去执行任务。(线程池中的线程也是重复使用的)
3)newScheduledThreadPool
3.1)延迟执行某个线程
public static void createScheduledThreadPoolToDelay(){
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
for(int i = 0; i < 10; i++){
final int index = i;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
scheduledThreadPool.schedule(new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " " + index + " delay 3 seconds");
}
}, 3, TimeUnit.SECONDS);
}
}
执行结果:
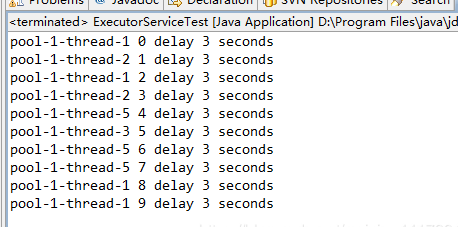
延迟3+2秒执行(3秒是newScheduledThreadPool中设置的,2秒是Thread.sleep()设置的),结果中可以看出主线程睡眠2秒并不能保证newScheduledThreadPool线程池中是使用旧线程执行任务还是新建线程执行任务,这种情况是随机的。(这点和newCachedThreadPool不一样,newCachedThreadPool是用就线程)
3.2)定期执行某个任务
public static void createScheduledThreadPoolToFixRate(){
ScheduledExecutorService exe = Executors.newScheduledThreadPool(3);
exe.scheduleAtFixedRate(new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " delay 1 seconds, and excute every 3 seconds");
}
}, 1, 3, TimeUnit.SECONDS);
}
执行结果:
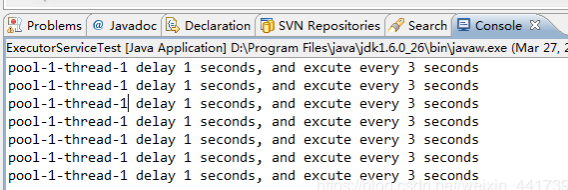
结果是延迟1s启动线程,并且之后每隔3s重复执行任务,但是用的是同一个线程。
4)newSingleThreadPool
/**
* 创建一个单线程的线程池
*/
public static void createSingleThreadPool(){
ExecutorService exe = Executors.newSingleThreadExecutor();
for(int i = 0; i < 10; i++){
final int index = i;
exe.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + ", " +index);
Thread.sleep(2000);// 让当前线程睡眠2s,发现顺序打印1~10,并且有个打印停顿2s
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
运行结果:
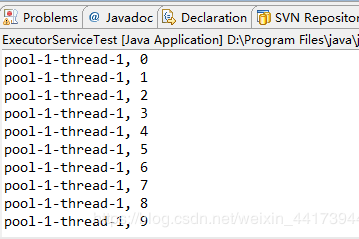
每输出一行结果就等待2s,可以看出每次输出的线程名都一样,说使用的同一个线程。单线程化的线程池中只有一个线程。
总结:
上面就是4中线程池的实现及其使用示例,和他们之间的区别。
其中newFixedThreadPool()有个坑,最好不要使用Executor.newFixedThreadPool(int nThreads)来创建线程池,因为它使用了LinkedBlockingQueue,容量是Integer.MAX_VALUE,容量太大容易造成防止所有任务都被阻塞,从而导致死锁。下面是具体源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
/**
* Creates a <tt>LinkedBlockingQueue</tt> with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
应该尽量直接使用new ThreadPoolExecutor来创建线程池,并指定阻塞队列的容量。
参考文章:https://www.cnblogs.com/zhaoyan001/p/7049627.html
Java中java.util.concurrent包下的4中线程池代码示例的更多相关文章
- java.util.concurrent包下集合类的特点与适用场景
java.util.concurrent包,此包下的集合都不允许添加null元素 序号 接口 类 特性 适用场景 1 Queue.Collection ArrayBlockingQueue 有界.阻塞 ...
- Java并发编程之java.util.concurrent包下常见类的使用
一,Condition 一个场景,两个线程数数,同时启动两个线程,线程A数1.2.3,然后线程B数4.5.6,最后线程A数7.8.9,程序结束,这涉及到线程之间的通信. public class Co ...
- java.util.concurrent包下并发锁的特点与适用场景
序号 类 备注 核心代码 适用场景 1 synchronized 同步锁 并发锁加在方法级别上,如果是单例class对象,则只能允许一个线程进入public synchronized void doX ...
- Java并发机制(8)--concurrent包下辅助类的使用
Java并发编程:concurrent包下辅助类的使用 整理自:博客园-海子-http://www.cnblogs.com/dolphin0520/p/3920397.html 1.CountDown ...
- Java中多线程的使用(超级超级详细)线程池 7
Java中多线程的使用(超级超级详细)线程池 7 什么是线程池? 线程池是一个容纳多个线程的容器,线程池中的线程可以重复使用,无需反复创建线程而消耗过多的资源 *使用多线程的好处: 1.降低消耗,减少 ...
- java.util.concurrent包
在JavaSE5中,JUC(java.util.concurrent)包出现了 在java.util.concurrent包及其子包中,有了很多好玩的新东西: 1.执行器的概念和线程池的实现.Exec ...
- java.util.concurrent包API学习笔记
newFixedThreadPool 创建一个固定大小的线程池. shutdown():用于关闭启动线程,如果不调用该语句,jvm不会关闭. awaitTermination():用于等待子线程结束, ...
- 【并发编程】【JDK源码】JDK的(J.U.C)java.util.concurrent包结构
本文从JDK源码包中截取出concurrent包的所有类,对该包整体结构进行一个概述. 在JDK1.5之前,Java中要进行并发编程时,通常需要由程序员独立完成代码实现.当然也有一些开源的框架提供了这 ...
- 高并发编程基础(java.util.concurrent包常见类基础)
JDK5中添加了新的java.util.concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性,所以这种方法 ...
随机推荐
- linux下自动获取并安装软件包 apt-get 的命令介绍
apt-cache search package 搜索包 apt-cache show package 获取包的相关信息,如说明.大小.版本等 sudo apt-get install p ...
- 2、Docker基础用法
容器镜像:https://hub.docker.com/ Docker架构图: https://ruby-china.org/topics/22004 Docker使用客户端-服务器(client- ...
- 使用ffmpeg进行视频封面截取
项目需求:用户上传视频格式的文件,需要转为指定编码的MP4格式(为了适应在线播放),并且截取视频的第一帧作为封面图片(用于展示) 实现: 1.下载ffmpeg.exe 地址:http://ffmpeg ...
- 2019 面试准备 - JS 防抖与节流 (超级 重要!!!!!)
Hello 小伙伴们,如果觉得本文还不错,记得给个 star , 你们的 star 是我学习的动力!GitHub 地址 本文涉及知识点: 防抖与节流 重绘与回流 浏览器解析 URL DNS 域名解析 ...
- SQL server中如何按照某一字段中的分割符将记录拆成多条
现需要将上结果转换为下结果 上结果查询语句:SELECT TOP 1 id,domain FROM dbo.SimpleTask 下结果转换语句:SELECT a.Id,b.domain FROM ...
- day2——两数相加
// 小白一名,0算法基础,艰难尝试算法题中,若您发现本文中错误, 或有其他见解,往不吝赐教,感激不尽,拜谢. 领扣 第2题 今日算法题干//给定两个非空链表来表示两个非负整数.位数按照逆序方式存储, ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- Jquery封装的Ajax
$.get方法 语法: $.get(url,data,function(e){ //e就是服务器返回的数据 },dataType); 四个参数: url: 请求的服务器地址 data: 发送给服务器的 ...
- python基础知识点(unittest)
目录: unittest 单元测试框架 1.写用例: Testcase 2.执行:TestSuite 类 TestLoader 类 3.比对结果(期望值/实际值):断言函数 4.结果:TestText ...
- [数据算法]D1.BloomFilter
BloomFilter是一种高效的去重算法,算法的要义是散列对比. 1.原理 当一个元素加入集合时,判断这个元素是否 2.举例 例如我要对URL去重(这个在爬虫上可以用): URL1 -> 3. ...