spark-2.4.0-hadoop2.7-高可用(HA)安装部署
1. 主机规划
|
主机名称 |
IP地址 |
操作系统 |
部署软件 |
运行进程 |
备注 |
|
mini01 |
172.16.1.11【内网】 10.0.0.11 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0、spark-2.4.0-hadoop2.7【主】 |
QuorumPeerMain、 |
|
|
mini02 |
172.16.1.12【内网】 10.0.0.12 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0、spark-2.4.0-hadoop2.7【主】 |
QuorumPeerMain、 |
|
|
mini03 |
172.16.1.13【内网】 10.0.0.13 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
|
|
mini04 |
172.16.1.14【内网】 10.0.0.14 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
|
|
mini05 |
172.16.1.15【内网】 10.0.0.15 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
说明
借助zookeeper,并且启动至少两个Master节点来实现高可靠。
2. 免密码登录
实现mini01、mini02到mini01、mini02、mini03、mini04、mini05通过秘钥免密码登录。
参见文章:Hadoop2.7.6_01_部署
3. Jdk【java8】
参见文章:Hadoop2.7.6_01_部署
4. Zookeeper部署
参见文章:zookeeper-02 部署
并启动zookeeper服务
5. Spark部署步骤
5.1. Spark安装
[yun@mini01 software]$ pwd
/app/software
[yun@mini01 software]$ ll
total
-rw-r--r-- yun yun Nov : spark-2.4.-bin-hadoop2..tgz
[yun@mini01 software]$ tar xf spark-2.4.-bin-hadoop2..tgz
[yun@mini01 software]$ mv spark-2.4.-bin-hadoop2. /app/
[yun@mini01 software]$ cd /app/
[yun@mini01 ~]$ ln -s spark-2.4.-bin-hadoop2./ spark
[yun@mini01 ~]$ ll -d spark-*
drwxr-xr-x yun yun Oct : spark-2.4.-bin-hadoop2.
lrwxrwxrwx yun yun Nov : spark -> spark-2.4.-bin-hadoop2./
5.2. 环境变量修改
根据规划,该环境变量的修改包括mini01、mini02、mini03、mini04、mini05。
# 需要root权限去添加环境变量
[root@mini01 ~]# tail /etc/profile
………………
# spark环境变量
export SPARK_HOME="/app/spark"
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH [root@mini01 ~]# logout
[yun@mini01 conf]$ source /etc/profile # 重新加载该环境变量
5.3. 配置修改
[yun@mini01 conf]$ pwd
/app/spark/conf
[yun@mini01 conf]$ cp -a spark-env.sh.template spark-env.sh
[yun@mini01 conf]$ tail spark-env.sh # 修改环境变量配置
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-).
# - MKL_NUM_THREADS= Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS= Disable multi-threading of OpenBLAS # 添加配置如下
# 配置JAVA_HOME
export JAVA_HOME=/app/jdk
# -Dspark.deploy.recoverMode=ZOOKEEPER #代表发生故障使用zookeeper服务
# -Dspark.depoly.zookeeper.url=mini01:,mini02:,mini03:,mini04:,mini05: #zookeeper的连接信息
# -Dspark.deploy.zookeeper.dir=/app/zookeeper/spark #spark要在zookeeper上写数据时的保存目录
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=mini01:2181,mini02:2181,mini03:2181,mini04:2181,mini05:2181 -Dspark.deploy.zookeeper.dir=/spark"
# 每一个Worker最多可以使用的内存,我的虚拟机就2g
# 真实服务器如果有128G,你可以设置为100G
# 所以这里设置为1024m或1g
export SPARK_WORKER_MEMORY=1024m
# 每一个Worker最多可以使用的cpu core的个数,我虚拟机就一个...
# 真实服务器如果有32个,你可以设置为32个
export SPARK_WORKER_CORES=
# 提交Application的端口,默认就是这个,万一要改呢,改这里
export SPARK_MASTER_PORT= [yun@mini01 conf]$ pwd
/app/spark /conf
[yun@mini01 conf]$ cp -a slaves.template slaves
[yun@mini01 conf]$ tail slaves # 修改slaves 配置
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# # A Spark Worker will be started on each of the machines listed below.
mini03
mini04
mini05
配置说明
# -Dspark.deploy.zookeeper.dir=/app/zookeeper/spark # spark要在zookeeper上写数据时的保存目录
[yun@mini05 ~]$ zkCli.sh # 进入zookeeper命令行 【在spark启动后查看】
[zk: localhost:(CONNECTED) ] ls / # 其中的 /spark 就是 我们在spark-env.sh中的配置
[cluster, brokers, zookeeper, yarn-leader-election, hadoop-ha, admin, isr_change_notification, log_dir_event_notification, controller_epoch, spark, consumers, latest_producer_id_block, config, hbase]
[zk: localhost:(CONNECTED) ] ls /spark
[leader_election, master_status]
[zk: localhost:(CONNECTED) ] ls /spark/master_status
[worker_worker--172.16.1.13-, worker_worker--172.16.1.14-, worker_worker--172.16.1.15-]
[zk: localhost:(CONNECTED) ] ls /spark/leader_election
[_c_6c6d0c36---a05c-9414a78d79e2-latch-, _c_04ceffff-b763-454a-b3f1-7fb56f56fa84-latch-]
5.4. 分发到其他机器
分发到mini02、mini03、mini04和mini05
其中mini01和mini02作为master
[yun@mini01 ~]$ scp -pr spark-2.4.-bin-hadoop2./ yun@mini02:/app # 拷贝到mini02
[yun@mini01 ~]$ scp -pr spark-2.4.-bin-hadoop2./ yun@mini03:/app # 拷贝到mini03
[yun@mini01 ~]$ scp -pr spark-2.4.-bin-hadoop2./ yun@mini04:/app # 拷贝到mini04
[yun@mini01 ~]$ scp -pr spark-2.4.-bin-hadoop2./ yun@mini05:/app # 拷贝到mini05
在mini02、mini03、mini04和mini05上操作
[yun@mini04 ~]$ pwd
/app
[yun@mini04 ~]$ ll -d spark-2.4.-bin-hadoop2.
drwxr-xr-x yun yun Oct : spark-2.4.-bin-hadoop2.
[yun@mini04 ~]$ ln -s spark-2.4.-bin-hadoop2./ spark
[yun@mini04 ~]$ ll -d spark-*
drwxr-xr-x yun yun Oct : spark-2.4.-bin-hadoop2.
lrwxrwxrwx yun yun Nov : spark -> spark-2.4.-bin-hadoop2./
5.5. 启动spark
5.5.1. 在mini01上操作
[yun@mini01 sbin]$ pwd
/app/spark/sbin
[yun@mini01 sbin]$ ./start-all.sh # 关闭使用 stop-all.sh 脚本
[yun@mini01 sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.master.Master--mini01.out
mini03: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker--mini03.out
mini04: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker--mini04.out
mini05: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker--mini05.out
[yun@mini01 ~]$
[yun@mini01 ~]$ jps # 查看进程状态
QuorumPeerMain
Jps
Master
5.5.2. 在mini02上操作
[yun@mini02 sbin]$ pwd
/app/spark/sbin
[yun@mini02 sbin]$ ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.master.Master--mini02.out
[yun@mini02 sbin]$ jps # 查看进程状态
Master
Jps
QuorumPeerMain
5.5.3. mini03进程查看
[yun@mini03 ~]$ jps
Jps
QuorumPeerMain
Worker
5.5.4. mini04进程查看
[yun@mini04 ~]$ jps
Jps
Worker
QuorumPeerMain
5.5.5. mini05进程查看
[yun@mini05 ~]$ jps
Jps
Worker
QuorumPeerMain
5.6. 浏览器访问
http://mini01:8080/

http://mini02:8080/
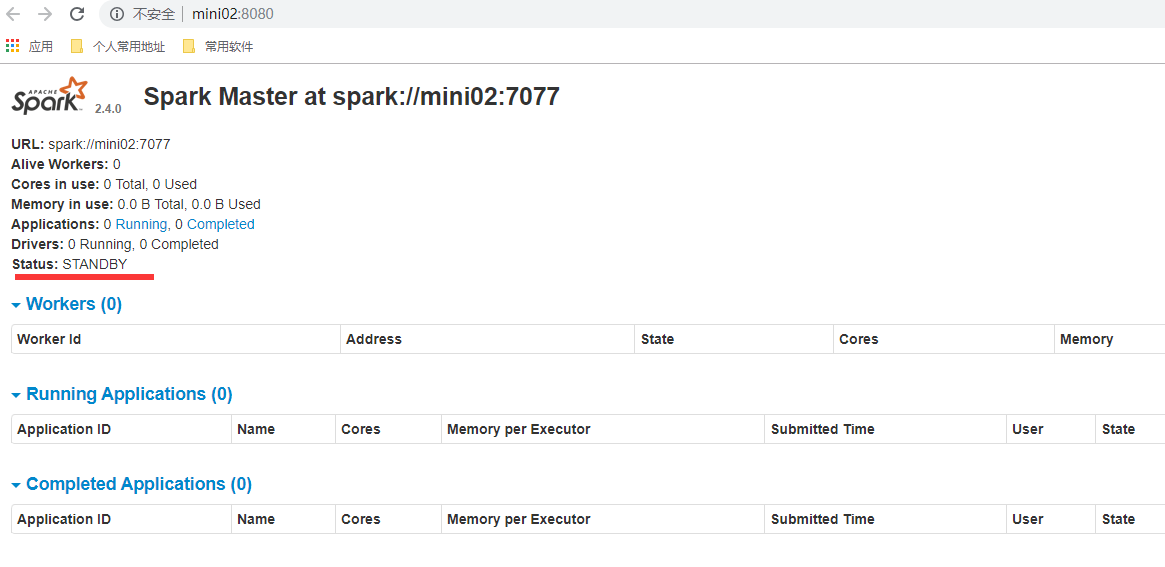
说明
如果我们停了mini01的spark master,稍等一会儿可见mini02的master状态从standby变为了alive。
此时再启动mini01的master,可见mini01的master状态是standby。
spark-2.4.0-hadoop2.7-高可用(HA)安装部署的更多相关文章
- Zabbix 6.0:原生高可用(HA)方案部署
Blog:博客园 个人 本部署文档适用于CentOS 8.X/RHEL 8.X/Anolis OS 8.X/AlmaLinux 8.X/Rockey Linux 8.X. 原生的HA方案终于来了 相比 ...
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- MySQL 高可用MHA安装部署以及故障转移详细资料汇总 转
http://blog.itpub.net/26230597/cid-87082-list-2/ 1,简介 .1mha简介 MHA,即MasterHigh Availability Manager a ...
- hadoop学习笔记(七):hadoop2.x的高可用HA(high avaliable)和联邦F(Federation)
Hadoop介绍——HA与联邦 0.1682019.06.04 13:30:55字数 820阅读 138 Hadoop 1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题: –HDFS ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- corosync+pacemaker实现高可用(HA)集群
corosync+pacemaker实现高可用(HA)集群(一) 重要概念 在准备部署HA集群前,需要对其涉及的大量的概念有一个初步的了解,这样在实际部署配置时,才不至于不知所云 资源.服务与 ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 十一.keepalived高可用服务实践部署
期中集群架构-第十一章-keepalived高可用集群章节======================================================================0 ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
随机推荐
- Python内置函数(62)——sum
英文文档: sum(iterable[, start]) Sums start and the items of an iterable from left to right and returns ...
- Linux 终端下解压文件失败问题
Linux 终端下解压文件失败: # tar -zxvf *****.tar.bz2 tar 命令出错gzip: stdin: not in gzip format tar: Child return ...
- SpringBoot基础系列-使用日志
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/9996897.html SpringBoot基础系列-使用日志 概述 SpringBoot ...
- Java集合类源码解析:ArrayList
目录 前言 源码解析 基本成员变量 添加元素 查询元素 修改元素 删除元素 为什么用 "transient" 修饰数组变量 总结 前言 今天学习一个Java集合类使用最多的类 Ar ...
- Java集合类:"随机访问" 的RandomAccess接口
引出RandomAccess接口 如果我们用Java做开发的话,最常用的容器之一就是List集合了,而List集合中用的较多的就是ArrayList 和 LinkedList 两个类,这两者也常被用来 ...
- Java开发笔记(三十二)字符型与整型相互转化
前面提到字符类型是一种新的变量类型,然而编码实践的过程中却发现,某个具体的字符值居然可以赋值给整型变量!就像下面的例子代码那样,把字符值赋给整型变量,编译器不但没报错,而且还能正常运行! // 字符允 ...
- jQuery.Ajax IE8,9 无效(CORS跨域)
今天在开发网站的时候,发现一个问题,$.ajax()在 IE8,9 浏览器不起作用,但 Chrome,Firefox ,360,IE10以上等浏览器却是可以的,网上资料很多,查询最后发现是 IE8,9 ...
- Css实现手机端页面强制横屏的方法示例
样式 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @media screen ...
- python 练习 simple_server 判断路径及返回函数
函数 routers 返回一个 urlpatterns 元组,里面包含了路径名和函数名:在 函数 application 中遍历 urlpatterns 元组,路径存在则返回函数名,不存在则返回 40 ...
- 微耕N3000注入
使用ILSpy或Reflector 反编译N3000并导出解决方案,便于搜索方法代码 使用ILDASM生成中间代码D:\app\WG\AccessControl\IL\N3000.il 操作如下:(可 ...