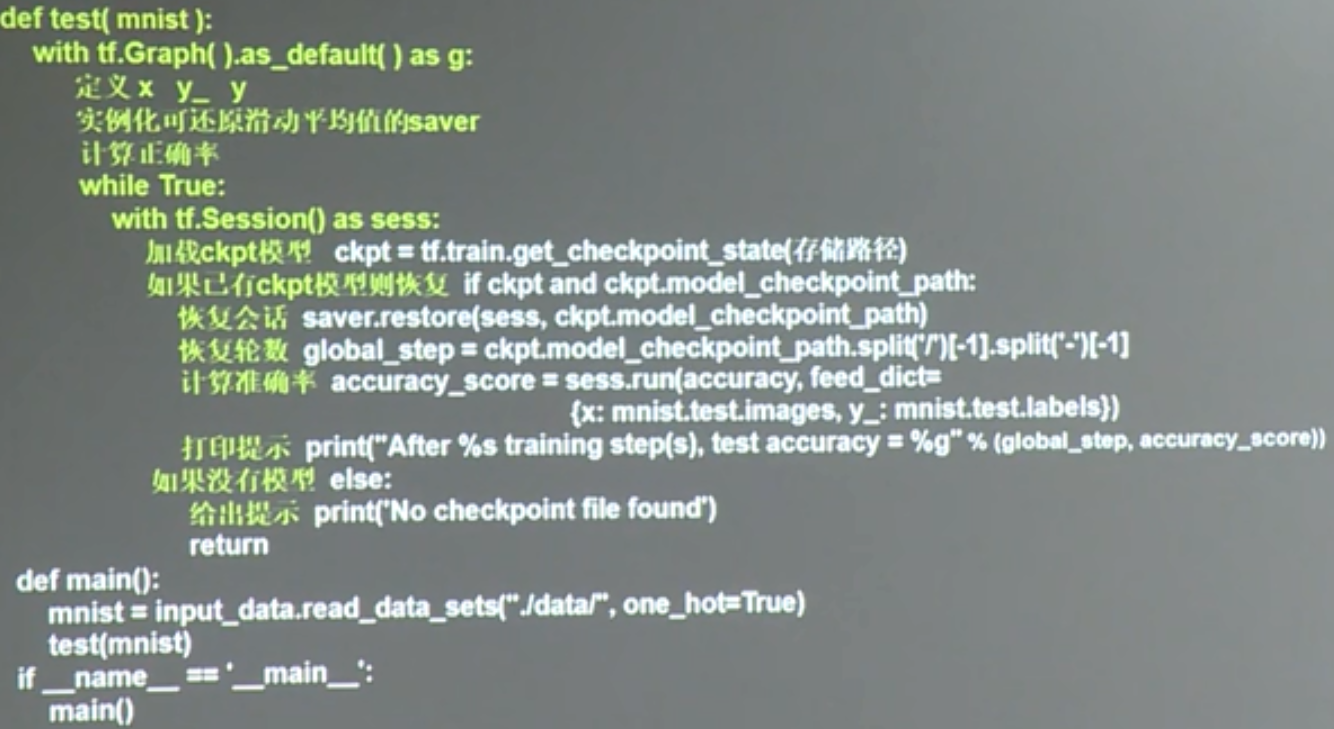
tensorFlow入门实践(二)模块化
实现过一个例子之后,对TensorFlow运行机制有了初步的了解,但脑海中还没有一个如何实现神经网络的一个架构模型。下面我们来探讨如何模块化搭建神经网络,完成数据训练和预测。
首先我们将整体架构分为两个模块:
forward.py 和 backward.py
forward.py 主要完成神经网络模型的搭建,即构建计算图

backward.py 训练出网络参数

test.py 测试模型准确率
下面是用随机生成数据来完成整个过程,如果对上面的总结理解不是很清楚的话,看着下面具体的代码,对照上面提出的框架,可以更好地理解。
generateds.py 生成数据
import numpy as np
import matplotlib.pyplot as plt
seed = 2
def generateds():
#基于seed产生随机数
rdm = np.random.RandomState(seed)
#随机数返回200列2行的矩阵,表示300组坐标点(x0,x1)作为输入数据集
X = rdm.randn(300,2)
#如果X中的2个数的平方和<2,y=1,否则y=2
#作为输入数据集的标签(正确答案)
Y_ = [int(x0*x0 + x1*x1 <2) for (x0,x1) in X]
#为方便可视化,遍历Y_中的每个元素,1为红,0为蓝
Y_c = [['red' if y else 'blue'] for y in Y_]
#对数据集X和标签Y进行形状整理,-1表示n,n行2列写为reshape(-1,2)
X = np.vstack(X).reshape(-1,2)
Y_ = np.vstack(Y_).reshape(-1,1)
#print(X)
#print(Y)
#print(Y_c)
return X,Y_,Y_c '''
if __name__ == '__main__':
X,Y_,Y_c=generateds() #用 plt.scatter画出数据集X中的点(x0.x1),Y_c表示颜色
plt.scatter(X[:,0], X[:,1],c=np.squeeze(Y_c))
plt.show()
'''
forward.py 定义向前传播过程,完成计算图的构建
#coding:utf-8
import tensorflow as tf #定义神经网络的输入、参数和输出,定义前项传播过程
def get_weight(shape, regularizer):
w = tf.Variable(tf.random_normal(shape),dtype=tf.float32)
#把每个w的正则化损失加到总损失losses中
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape):
b=tf.Variable(tf.constant(0.01, shape=shape))
return b #搭建前向传播框架
def forward(x, regularizer): w1 = get_weight([2,11], regularizer)
b1 = get_bias([11])
#(x和w1实现矩阵乘法 + b1)过非线性函数(激活函数)
y1 = tf.nn.relu(tf.matmul(x, w1) + b1) w2 = get_weight([11,1], regularizer)
b2 = get_bias([1])
#输出层不过激活函数
y = tf.matmul(y1, w2) + b2 return y
backward.py 完成网络参数训练
#coding:utf-8
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import generateds
import forward STEPS = 40000#共进行40000轮
BATCH_SIZE = 30#表示一次为喂入NN多少组数据
LEARNING_RATE_BASE = 0.001#学习率基数,学习率初始值
LEARNING_RATE_DECAY = 0.999#学习率衰减率
REGULARIZER = 0.01#参数w的loss在总losses中的比例,即正则化权重 def backward():
x = tf.placeholder(tf.float32,(None,2))
y_ = tf.placeholder(tf.float32,(None,1)) X,Y_,Y_c = generateds.generateds() y=forward.forward(x, REGULARIZER) global_step = tf.Variable(0, trainable = False) learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,300/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase = True) #定义损失函数
loss_mse = tf.reduce_mean(tf.square(y-y_))#利用均方误差
loss_total = loss_mse + tf.add_n(tf.get_collection('losses')) #定义反向传播方法:包含正则化
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss_total) with tf.Session() as sess :
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(STEPS):
start =(i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x:X[start:end], y_:Y_[start:end]})
if i % 2000 == 0:
loss_v = sess.run(loss_total, feed_dict={x:X,y_:Y_})
print('After %d steps, loss if %f '%(i,loss_v)) #xx在-3到3之间步长为0.01,yy在-3到3之间步长为0.01生成二维网格坐标点
xx, yy = np.mgrid[-3:3.01, -3:3:.01]
#将xx,yy拉直,并合并成一个2列的矩阵,得到一个网格坐标点的集合
grid = np.c_[xx.ravel(), yy.ravel()]
#将网格坐标点喂入神经网络,probs为输出
probs = sess.run(y, feed_dict={x:grid})
#将probs的shape调整成xx的样子
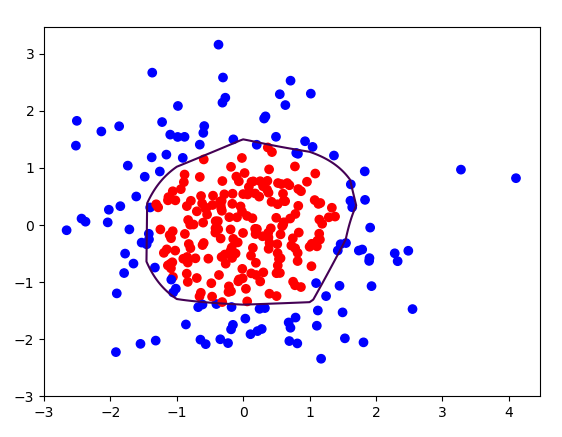
probs = probs.reshape(xx.shape) #画出离散点
plt.scatter(X[:,0], X[:,1], c=np.squeeze(Y_c))
#画出probs,0.5的曲线
plt.contour(xx, yy, probs, levels=[.5])
plt.show() if __name__ == '__main__':
backward()
输出结果:
tensorFlow入门实践(二)模块化的更多相关文章
- 【实战】Docker入门实践二:Docker服务基本操作 和 测试Hello World
操作环境 操作系统:CentOS7.2 内存:1GB CPU:2核 Docker服务常用命令 docker服务操作命令如下 service docker start #启动服务 service doc ...
- tensorFlow入门实践(三)实现lenet5(代码结构优化)
这两周我学习了北京大学曹建老师的TensorFlow笔记课程,认为老师讲的很不错的,很适合于想要在短期内上手完成一个相关项目的同学,课程在b站和MOOC平台都可以找到. 在卷积神经网络一节,课程以le ...
- tensorflow入门(二)
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt #使用numpy生成200个随机点 x_data ...
- tensorFlow入门实践(三)初识AlexNet实现结构
参考黄文坚<TensorFlow实战>一书,完成AlexNet的整体实现并展望其训练和预测过程. import tensorflow as tf batch_size = 32 num_b ...
- tensorFlow入门实践(一)
首先应用TensorFlow完成一个线性回归,了解TensorFlow的数据类型和运行机制. import tensorflow as tf import numpy as np import mat ...
- c++开发ocx入门实践二
原文:http://blog.csdn.net/yhhyhhyhhyhh/article/details/51374355 IDE:vs2010,c++,测试工具,vs自带的TstCo ...
- Django入门实践(二)
Django入门实践(二) Django模板简单实例 上篇中将html写在了views中,这种混合方式(指Template和views混在一起)不适合大型开发,而且代码不易管理和维护,下面就用Djan ...
- TensorFlow 入门之手写识别(MNIST) softmax算法 二
TensorFlow 入门之手写识别(MNIST) softmax算法 二 MNIST Fly softmax回归 softmax回归算法 TensorFlow实现softmax softmax回归算 ...
- tensorflow学习笔记二:入门基础 好教程 可用
http://www.cnblogs.com/denny402/p/5852083.html tensorflow学习笔记二:入门基础 TensorFlow用张量这种数据结构来表示所有的数据.用一 ...
随机推荐
- sqlite3如何判断一个表是否已经存在于数据库中 C++
SELECT count(*) AS cnt FROM sqlite_master WHERE type='table' AND name='table_name';cnt will return 0 ...
- 雷林鹏分享:jQuery EasyUI 数据网格 - 添加复选框
jQuery EasyUI 数据网格 - 添加复选框 本实例演示如何放置一个复选框列到数据网格(DataGrid).通过复选框,用户将可以选择 选中/取消选中 网格行数据. 为了添加一个复选框列,我们 ...
- Web API学习笔记(Python实现)
参考指南: Web API入门指南 http://www.cnblogs.com/guyun/p/4589115.html 用Python写一个简单的Web框架 http://www.cnblogs. ...
- Python自学:第三章 使用函数sort( )对列表进行临时排序
# -*- coding: GBK -*- cars = ["bmw", "audi", "toyota", "subaru&qu ...
- 关于Oracle单行函数的讲解
单行函数:对单个数值进行操作,并返回一个值. 分类:1.字符函数 1)concat(a,b) 拼接a,b两个字符串数据 2)initcap(x) 将每个单词x首字母大写 3)low ...
- 敏捷开发——User Story
敏捷开发流程: 1.我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的: 2.Scrum Team根据Product B ...
- HotSpot虚拟机对象探秘-笔记
学习目的:探讨HotSpot虚拟机在Java堆中对象分配.布局和访问的全过程. 1.对象的创建 虚拟机在执行到一条new指令时,先要检查指令的参数(将要实例化的类)是否已经被加载.解析.初始化过,如果 ...
- React文档(十九)不使用ES6
通常你会将一个React组件定义成一个普通的js类: class Greeting extends React.Component { render() { return <h1>Hell ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Win10 禁止自动更新以及禁止Windows 10升级助手(Windows 10 易升)
微软目前已经重新启用非常烦人的Windows 10升级助手,现在该助手主要帮助用户自动下载以及安装更新. 彻底禁用: 1.在开始菜单右侧的搜索框中输入关键词控制面板,然后打开控制面板后转到程序与功能里 ...