cdh日常维护常见问题及解决方案
为数据节点添加新硬盘
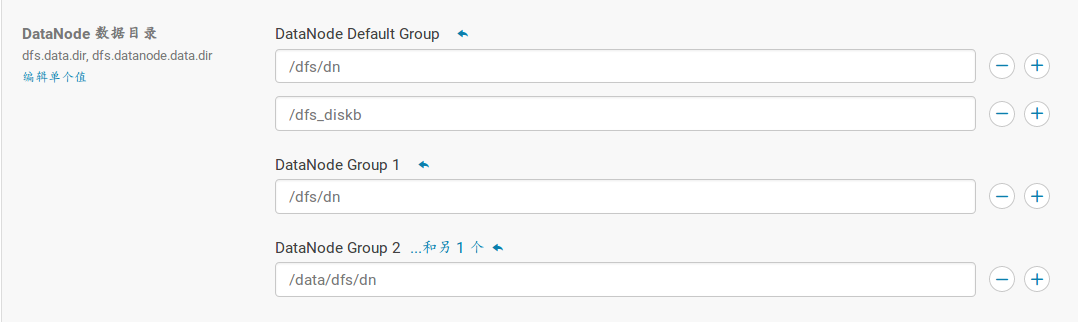
- 挂载硬盘到指定文件夹。如`/dfs_diskb`;
- 打开cloudera manager -> hdfs -> 配置 -> DataNode -> DataNode Default Group,添加新硬盘所挂载的目录,注意节点所在群;
- 重启hdfs服务。
hdfs数据平衡
在主节点(其它节点未测试)执行命令:sudo -u hdfs hdfs balancer。
集群时钟同步
- ntp服务端和外网同步:`sudo /etc/init.d/ntp restart`
- 客户端与内网ntp服务器同步`sudo ntpdate ntp_server_ip`
hive表在生成过程中产生过多的小文件导致chd报警,Concerning : The DataNode has 814,837 blocks. Warning threshold: 500,000 block(s).
- 通过命令`hadoop fsck /user/hive/warehouse/db_name`查询后发现该数据块下平均文件块仅仅为5kb,远远小于128m。
- 设置参数似的hive在存储sql执行后对执行结果中的大小较小的文件进行合并
```
hive.merge.mapfiles 在map-only job后合并文件,默认true
hive.merge.mapredfiles 在map-reduce job后合并文件,默认false
hive.merge.size.per.task 合并后每个文件的大小,默认256000000
hive.merge.smallfiles.avgsize 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
```
修改hive的配置参数
<name>mapred.max.split.size</name><value>512000000</value></property><property><name>hive.merge.mapredfiles</name><value>true</value></property><property><name>hive.exec.compress.output</name><value>true</value></property><property><name>mapred.min.split.size.per.node</name><value>100000000</value></property><property><name>hive.merge.smallfiles.avgsize</name><value>64000000 </value></property>
对于输出文件是压缩文件的,需要将表的存储格式修改为SEQUENCEFILE
NFS Gateway服务启动失败
原因:节点已经启动了nfs服务,需要关闭
命令:sudo service nfs-kernel-server stop
重启该服务,成功上线
host monitor与agent失去连接
造成该问题的原因是在root权限下启动了cloudera manager服务。可以关闭当前的cloudera manager服务,然后在非root用户下来启动cloudera manager的angent和service服务,问题解决。
cdh日常维护常见问题及解决方案的更多相关文章
- oracle 容灾库日常维护 ,健康检查脚本 以及常见问题分析
select DEST_ID, APPLIED_SCN FROM v$archive_dest select * from v$dataguard_status; SELECT gvi.thread# ...
- MapReduce On Yarn的配置详解和日常维护
MapReduce On Yarn的配置详解和日常维护 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce运维概述 MapReduce on YARN的运维主要是 ...
- XHTML CSS 常见问题和解决方案
原文地址:XHTML CSS 常见问题和解决方案 作为前端开发人员,在日常的页面制作时,不可避免的会碰上这样那样的问题,我挑选了其中的一些进行总结归档,希望对大家会有所帮助: 1.如何定义高度很小的容 ...
- Redis常见问题及解决方案
在Redis的运维使用过程中你遇到过那些问题,又是如何解决的呢?本文收集了一些Redis的常见问题以及解决方案,与大家一同探讨. 码字不易,欢迎大家转载,烦请注明出处:谢谢配合 你的Redis有big ...
- ORACLE分区表梳理系列(二)- 分区表日常维护及注意事项(红字需要留意)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- 数据库日常维护-CheckList_01历史Agent Job执行情况检查
检查Agent Job中日常维护作业或业务作业是否成功,如每天的备份.碎片整理.索引维护.历史备份文件清除等,可利用SSMS工具,通过CDC下面设置好的DB Server List,运行下面脚本一次, ...
- 《PDF.NE数据框架常见问题及解决方案-初》
<PDF.NE数据框架常见问题及解决方案-初> 1.新增数据库后,获取标识列的值: 解决方案: PDF.NET数据框架,已经为我们考略了很多,因为用PDF.NET进行数据的添加操作时 ...
- MS SQL 日常维护管理常用脚本(二)
监控数据库运行 下面是整理.收集监控数据库运行的一些常用脚本,也是MS SQL 日常维护管理常用脚本(一)的续集,欢迎大家补充.提意见. 查看数据库登录名信息 Code Snippet SELEC ...
- 2.goldengate日常维护命令(转载)
goldengate日常维护命令 发表于 2013 年 7 月 4 日 由 Asysdba 1.查看进程状态 GGSCI (PONY) 2> info all 2.查看进程详细状态,有助于排错 ...
随机推荐
- SQL表的自身关联
SQL表的自身关联 有如下两个数据表: tprt表,组合基本信息表,每个组合有对应的投管人和托管人: tmanager表,管理人信息表,管理人类别由o_type区分: 具体表信息如下所示: tprt表 ...
- MySql 8.0 C#连接报错 MySql.Data.MySqlClient.MySqlException (0x80004005): Authentication to host '12.118.224.181' for user 'root' using method 'caching_sha2_password' failed with message: Reading from t
解决方法 在连接字符串后面加上 SslMode=None
- [十二省联考2019]异或粽子 01trie
[十二省联考2019]异或粽子 01trie 链接 luogu 思路 首先求前k大的(xo[i]^xo[j])(i<j). 考场上只想到01trie,不怎么会写可持久,就写了n个01trie,和 ...
- 【做题】POI2011R1 - Plot——最小圆覆盖&倍增
原文链接 https://www.cnblogs.com/cly-none/p/loj2159.html 题意:给出\(n\)个点,你需要按编号将其划分成不超过\(m\)段连续的区间,使得所有每个区间 ...
- BZOJ 3473 字符串
思路 广义SAM的题目,先全部插入,然后每个字符串在SAM上匹配,如果发现当前sz小于k(就是前缀不满足条件),就跳fail(找前缀的后缀,就是找子串)到满足条件为止,然后一个满足条件的节点,它的所有 ...
- SetForegroundWindow Win32-API not always works on Windows-7
BIG NOTE After messing with this API for the last 2 months, the solution/s below are all not stable ...
- Generator
基本概念 Generator函数是ES6提供的一种异步编程解决办法,语法行为与传统函数完全不同. Generator函数有多种理解角度.语法上,首先可以把它理解成,Generator函数是一个状态机, ...
- krpano 常用标签
<krpano></krpano>根标签 相当于 <body> <scene></scene>一个全景图场景 <image> 图 ...
- LeetCode 05 最长回文子串
题目 给定一个字符串 s,找到 s 中最长的回文子串.你可以假设 s 的最大长度为 1000. 示例 1: 输入: "babad" 输出: "bab" 注意: ...
- 封装json输出
/** * 输出json * @param $msg * @param int $errno */ protected function printOutError($msg,$errno = 100 ...