基于密度峰值的聚类(DPCA)
1、背景介绍
密度峰值算法(Clustering by fast search and find of density peaks)由Alex Rodriguez和Alessandro Laio于2014年提出,并将论文发表在Science上。Science上的这篇文章《Clustering by fast search and find of density peaks》主要讲的是一种基于密度的聚类方法,基于密度的聚类方法的主要思想是寻找被低密度区域分离的高密度区域。 密度峰值算法(DPCA)基于这样的假设:(1)类簇中心点的密度大于周围邻居点的密度;(2)类簇中心点与更高密度点之间的距离相对较大。因此,DPCA主要有两个需要计算的量:第一,局部密度;第二,与高密度点之间的距离。
2、局部密度
数据对象的局部密度
定义为:
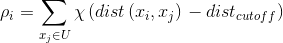
其中,表示截断距离
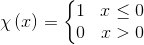 ,这个公式的含义是说找到与第
,这个公式的含义是说找到与第个数据点之间的距离小于截断距离
的数据点的个数,并将其作为第i个数据点真的密度。
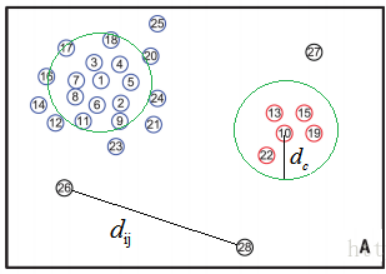
3、定义聚类中心距离
密度峰聚类算法的巧妙之处:就是在于聚类中心距离 δi的选定。根据局部密度的定义,我们可以计算出上图中每个点的密度,依照密度确定聚类中心距离 δi。
1.首先将每个点的密度从大到小排列: ρi > ρj > ρk > ….;密度最大的点的聚类中心距离与其他点的聚类中心距离的确定方法是不一样的;
2.先确定密度最大的点的聚类中心距离–i点是密度最大的点,它的聚类中心距离δiδi等于与i点最远的那个点n到点i的直线距离 d(i,n);
3. 再确定其他点的聚类中心距离——其他点的聚类中心距离是等于在密度大于该点的点集合中,与该点距离最小的的那个距离。例如i、j、k的密度都比n点的密度大,且j点离n点最近,则n点的聚类中心距离等于d(j,n);
4. 依次确定所有的聚类中心距离δ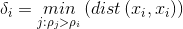
4、聚类效果
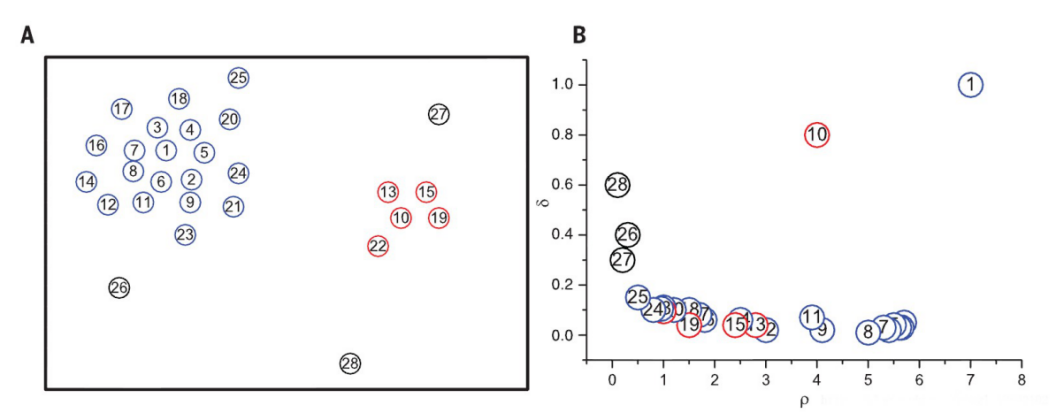
将所有点的聚类中心密度都统计出来后,将其值按 δi和pi作为坐标轴作图可以得到如图所示结果。可以看到图中1,10两个聚类中心同时远离坐标轴。普通点则是靠近p轴,异常点靠近 δ轴。
5、基于python的实现:
python代码如下,其中要引入numpy等一些包,pycharm中引入包还是比较简单的。
# -*- coding:utf- -*-
# -*- python3.
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors min_distance = 4.6 # 邻域半径
points_number = # 随机点个数 # 计算各点间距离、各点点密度(局部密度)大小
def get_point_density(datas,labers,min_distance,points_number):
# 将numpy.ndarray格式转为list格式,并定义元组大小
data = datas.tolist()
laber = labers.tolist()
distance_all = np.random.rand(points_number,points_number)
point_density = np.random.rand(points_number) # 计算得到各点间距离
for i in range(points_number):
for n in range(points_number):
distance_all[i][n] = np.sqrt(np.square(data[i][]-data[n][])+np.square(data[i][]-data[n][]))
print('距离数组:\n',distance_all,'\n') # 计算得到各点的点密度
for i in range(points_number):
x =
for n in range(points_number):
if distance_all[i][n] > and distance_all[i][n]< min_distance:
x = x+
point_density[i] = x
print('点密度数组:', point_density, '\n')
return distance_all, point_density # 计算点密度最大的点的聚类中心距离
def get_max_distance(distance_all,point_density,laber):
point_density = point_density.tolist()
a = int(max(point_density))
# print('最大点密度',a,type(a)) b = laber[point_density.index(a)]
# print("最大点密度对应的索引:",b,type(b)) c = max(distance_all[b])
# print("最大点密度对应的聚类中心距离",c,type(c)) return c # 计算得到各点的聚类中心距离
def get_each_distance(distance_all,point_density,data,laber):
nn = []
for i in range(len(point_density)):
aa = []
for n in range(len(point_density)):
if point_density[i] < point_density[n]:
aa.append(n)
# print("大于自身点密度的索引",aa,type(aa))
ll = get_min_distance(aa,i,distance_all, point_density,data,laber)
nn.append(ll)
return nn # 获得:到点密度大于自身的最近点的距离
def get_min_distance(aa,i,distance_all, point_density,data,laber):
min_distance = []
"""
如果传入的aa为空,说明该点是点密度最大的点,该点的聚类中心距离计算方法与其他不同
"""
if aa != []:
for k in aa:
min_distance.append(distance_all[i][k])
# print('与上各点距离',min_distance,type(nn))
# print("最小距离:",min(min_distance),type(min(min_distance)),'\n')
return min(min_distance)
else:
max_distance = get_max_distance(distance_all, point_density, laber)
return max_distance def get_picture(data,laber,points_number,point_density,nn):
# 创建Figure
fig = plt.figure()
# 用来正常显示中文标签
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
# 用来正常显示负号
matplotlib.rcParams['axes.unicode_minus'] = False # 原始点的分布
ax1 = fig.add_subplot()
plt.scatter(data[:,],data[:,],c=laber)
plt.title(u'原始数据分布')
plt.sca(ax1)
for i in range(points_number):
plt.text(data[:,][i],data[:,][i],laber[i]) # 聚类后分布
ax2 = fig.add_subplot()
plt.scatter(point_density.tolist(),nn,c=laber)
plt.title(u'聚类后数据分布')
plt.sca(ax2)
for i in range(points_number):
plt.text(point_density[i],nn[i],laber[i]) plt.show() def main():
# 随机生成点坐标
data, laber = ds.make_blobs(points_number, centers=points_number, random_state=)
print('各点坐标:\n', data)
print('各点索引:', laber, '\n') # 计算各点间距离、各点点密度(局部密度)大小
distance_all, point_density = get_point_density(data, laber, min_distance, points_number)
# 得到各点的聚类中心距离
nn = get_each_distance(distance_all, point_density, data, laber)
print('最后的各点点密度:', point_density.tolist())
print('最后的各点中心距离:', nn) # 画图
get_picture(data, laber, points_number, point_density, nn)
"""
距离归一化:就把上面的nn改为:nn/max(nn)
""" if __name__ == '__main__':
main()
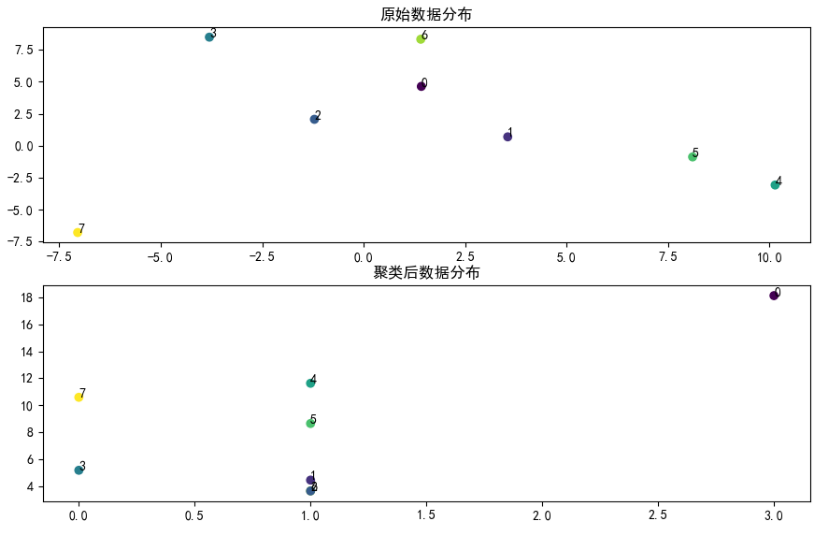
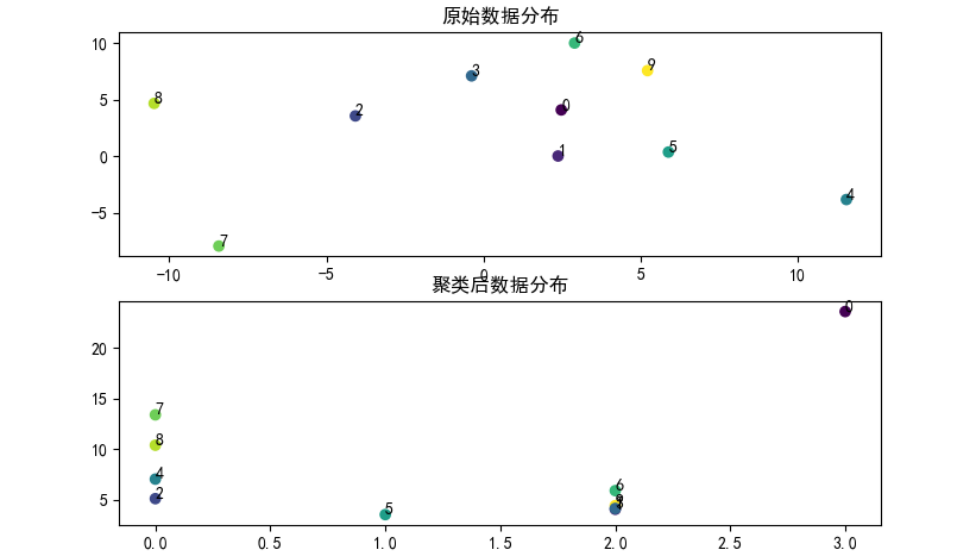
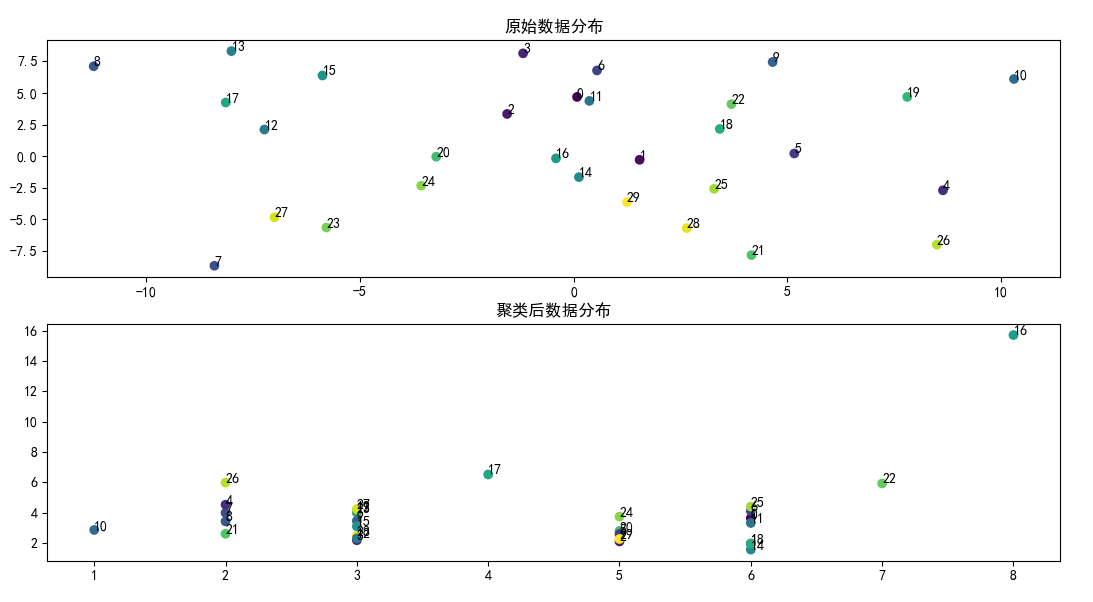
代码运行效果如下图:
基于密度峰值的聚类(DPCA)的更多相关文章
- 聚类-DBSCAN基于密度的空间聚类
1.DBSCAN介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 密度峰值聚类算法(DPC)
密度峰值聚类算法(DPC) 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 简介 基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(cl ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- 密度峰值聚类算法原理+python实现
密度峰值聚类(Density peaks clustering, DPC)来自Science上Clustering by fast search and find of density peaks ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
随机推荐
- [.NET] 《Effective C#》快速笔记(二)- .NET 资源托管
<Effective C#>快速笔记(二)- .NET 资源托管 简介 续 <Effective C#>读书笔记(一)- C# 语言习惯. .NET 中,GC 会帮助我们管理内 ...
- .Net 接入CAS 遇到的坑
关于CAS是个什么东西,就不多闲扯了,相信每个有过SSO经验的都听过CAS大名,百度百科地址: https://baike.baidu.com/item/CAS/1329561?fr=aladdin ...
- XML记一次带命名空间的xml读取
public static void ReadXML(string xmlUrl) { //判断文件是否存在 if (!File.Exists(xmlUrl)) { Console.WriteLine ...
- [Linux] awk与posix字符集
awk posix字符集[:alnum:] 文字数字字符[:alpha:] 文字字符[:digit:] 数字字符[:graph:] 非空字符(非空格.控制字符)[:lower:] 小写字符[:cntr ...
- Java基础:HashMap假死锁问题的测试、分析和总结
前言 前两天在公司的内部博客看到一个同事分享的线上服务挂掉CPU100%的文章,让我联想到HashMap在不恰当使用情况下的死循环问题,这里做个整理和总结,也顺便复习下HashMap. 直接上测试代码 ...
- Bable实现由ES6转译为ES5
Babel是一个广泛使用的转码器,可以将ES6代码转译为ES5代码,从而在现有环境下执行. 举例说明: 转译前(ES6格式)代码如下: let User = { name : '张三', age : ...
- 移动端web自适应适配布局解决方案
100%还原设计图,要注意: 看布局,分析结构. 感觉难点在于: 1.测量精度(ps测量数据): 2.文字的行高. 前段时间写个移动端适配的页面(刚接触这方面),查了一些资料,用以下方法能实现: 1. ...
- 【20190415】JavaScript-事件流与stopPropagation()、stopImmediatePropagation()的误区解析
这两天仔细看了一下MDN上关于事件流机制和相关方法的文档,发现有个很大的误区.过去我一直以为stopPropagation()就是用来阻止事件冒泡的,甚至很多博客和菜鸟教程上都是这样写的.但实际上文档 ...
- C# 使用NPOI出现超过最大字体数和单元格格式变成一样的解决
在使用NPOI写入Excel文件的时候出现“它已经超出最多允许的字体数”,查询资料发现是字体创建太多的原因,需要将常用字体创建好,传入CellStyle中.参考(http://www.cnblogs. ...
- 从.Net到Java学习第八篇——SpringBoot实现session共享和国际化
从.Net到Java学习系列目录 SpringBoot Session共享 修改pom.xml添加依赖 <!--spring session--> <dependency> & ...