Ubuntu安装Hadoop
系统:Ubuntu16.04
JDK:jdk-8u201
Hadoop:3.1.2
一、安装JDK
https://www.cnblogs.com/tanrong/p/10641803.html
二、安装并配置ssh免密登录
hadoop需要使用SSH的方式登陆,linux下需要安装SSH。客户端已经安装好了,一般只需要安装服务端就可以了:
在安装之前,还是先查看系统是否已经安装并且启动了ssh。
# 查看ssh安装包情况
dpkg -l | grep ssh # 查看是否启动ssh服务
ps -e | grep ssh
如果没有ssh服务,则安装ssh:
$ sudo apt-get install openssh-server
安装完成,开启服务(一般都是自动开启的,所以如果一切正常的话下面这条可以不用执行)
$ sudo /etc/init.d/ssh start
测试登陆本机 ssh localhost 输入yes,再输入密码,就应该可以登录了。但是每次输入比较繁琐,如果是集群那就是灾难了,所以要配置成免密码登陆的方式。
1. 生成公钥私钥,将在~/.ssh文件夹下生成文件id_rsa:私钥,id_rsa.pub:公钥
$ ssh -keygen -t rsa
一直回车即可
2. 导入公钥到认证文件,更改权限:
(1)导入本机:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(2)导入服务器:(我只是在本机配置的,所以这一步我没做)
首先将公钥复制到服务器:
scp ~/.ssh/id_rsa.pub xxx@host:/home/xxx/id_rsa.pub
然后,将公钥导入到认证文件,这一步的操作在服务器上进行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
最后在服务器上更改权限:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
3)测试:ssh localhost 第一次需要输入yes和密码,之后就不需要了。
三、hadoop的安装与配置
1. 官网下载:https://hadoop.apache.org/releases.html Binary download
也可以使用wget命名下载(下载目录是当前目录):
例如:version3.1.2 http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
2. 解压、移动到你想要放置的文件夹
mv ./hadoop-3.1.2.tar.gz ~/Software/hadoop tar -zvxf hadoop-3.1.2.tar.gz
3. 创建hadoop用户和组,并授予执行权限
sudo addgroup hadoop
sudo usermod -a -G hadoop xxx #将当前用户加入到hadoop组
sudo gedit /etc/sudoers #将hadoop组加入到sudoer
在 root ALL=(ALL) ALL 后
添加一行 hadoop ALL=(ALL) ALL
sudo chmod -R 755 /home/rongt/Software/hadoop sudo chown -R rongt:hadoop /home/rongt/Software/hadoop //否则ssh会拒绝访问
这些都是一般需要的操作,这篇文章还进行了其它的配置,如果遇到问题可以看看,是不是由于这些配置导致的:点这里。
4. 修改配置文件,和JDK的安装一样,可以选择修改哪个文件。这里修改 sudo gedit /etc/profile 或者 sudo gedit ~/.bashrc
export HADOOP_HOME=/home/rongt/Software/hadoop/hadoop-3.1.2
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
# 使配置文件生效
source /etc/profile
或者 source ~/.bashrc
这篇配置文章还配了很多其它配置,我暂时没有配置,遇到问题,可以做为参考。点这里。
记录一个报错 ERROR: /usr/lib/jvm/java-8-oracle/jre/bin/bin/java is not executable.
很明显路径错误,里面有两个bin,当时是因为环境变量设置错误,但是后来改了环境变量还是这样报错,考虑到是因为环境变量没有生效,于是执行了source /etc/profile但还是不行,最后重启之后解决了
5. 测试是否配置成功
hadoop version
6. hadoop单机配置(非分布式模式)
hadoop默认是非分布式模式,不需要进行其它配置。可以测试demo来观察是否配置正确。下面这个例子用来统计README.txt 文件的单词数
# 进入hadoop主目录
cd /home/rongt/Software/hadoop/hadoop-3.1.2
mkdir input
# 里面有个README.txt
cp README.txt input # 注意改成自己的Hadoop版本
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-3.1.2-sources.jar org.apache.hadoop.examples.WordCount input output
7. hadoop伪分布式配置
伪分布式只需要更改两个文件就够了,core-site.xml和hdfs-site.xml。这两个文件都在hadoop目录下的etc/hadoop中。
cd /home/rongt/Software/hadoop/hadoop-3.1.2/etc/hadoop
首先是core-site.xml,设置临时目录位置,否则默认会在/tmp/hadoo-hadoop中,这个文件夹在重启时可能被系统清除掉,所以需要改变配置路径。修改<configuration> </configuration>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/rongt/Software/hadoop/hadoop-3.1.2/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
然后就是hdfs-site.xml,伪分布式只有一个节点,所以必须配置成1。还配置了datanode和namenode的节点位置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/rongt/Software/hadoop/hadoop-3.1.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/rongt/Software/hadoop/hadoop-3.1.2/tmp/dfs/data</value>
</property>
</configuration>
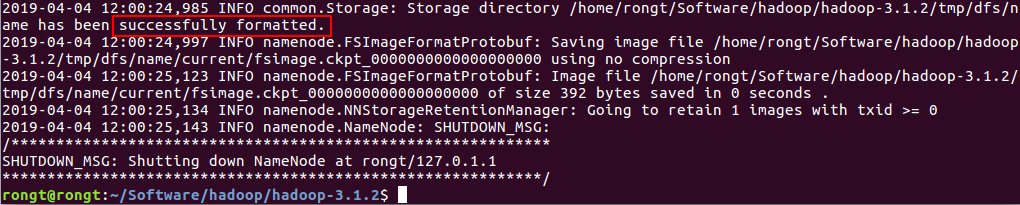
配置完成后在 /home/rongt/Software/hadoop/hadoop-3.1.2 (注意是自己的hadoop目录) 下使用以下命令 执行format命令,格式化名称节点
./bin/hdfs namenode -format
开启hdfs:./sbin/start-dfs.sh (同样注意路径)如果出现ssh认证 输入yes就可以了。
遇到报错:localhost: ERROR: JAVA_HOME is not set and could not be found.
解决方案:其实是hadoop里面hadoop-env.sh文件里面的java路径设置不对,hadoop-env.sh在/home/rongt/Software/hadoop/hadoop-3.1.2/etc/hadoop目录下,具体的修改办法如下:
# sudo gedit hdoop-env.sh 将语句
export JAVA_HOME=$JAVA_HOME
# 也有可能语句为export JAVA_HOME= (且被注释掉了) 修改为
export JAVA_HOME=/usr/lib/jvm/java-8-oracle # 自己的Java home路径,可以在终端输入$JAVA_HOME 查看 保存后退出,重新执行./sbin/start-dfs.sh
输入jps命令查看是否启动成功
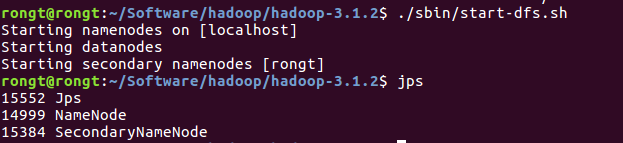

namenode和datanode都要出现才算成功??
访问http://localhost:50070 查看节点信息。 具体要看配置文件,我目前的地址是:http://rongt:50070
关闭hdfs: ./sbin/stop-dfs.sh
8. 配置yarn(非必须)
上面都是hdfs的配置,接下来就需要配置mapreduce的相关配置了,不配这个也不会影响到什么。但是缺少了资源调度,hadoop2.x版本使用yarn来进行任务调度管理,这是与1.x版本最大的不同。
在/home/rongt/Software/hadoop/hadoop-3.1.2下操作
# 并没有mapred-site.xml.template这个文件,不过直接有mapred-site.xml,所以没有执行这一步
# 我看的教程是安装2.x的,但我下的是3.1.2,这可能是版本区别吧
cp ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml sudo gedit ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动yarn(要先启动了hdfs:./sbin/start-dfs.sh)
./sbin/start-yarn.sh
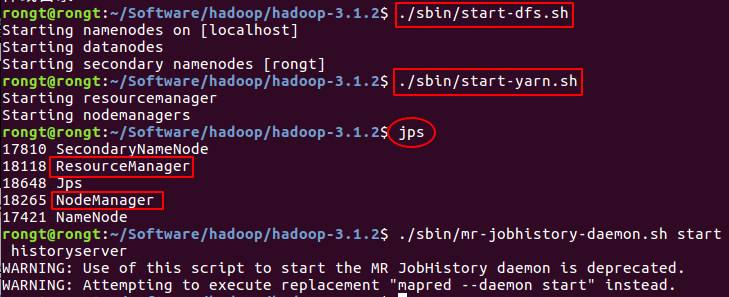
开启历史服务器,查看历史任务,这样可以在web界面中查看任务运行情况:
./sbin/mr-jobhistory-daemon.sh start historyserver
启动成功后可以在http://localhost:8088/cluster访问集群资源管理器。
不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况:http://localhost:8088/cluster 。
关闭资源管理器
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver # 关了之后 http://localhost:8088/cluster就无法访问了
9. 分布式部署,没有两台电脑,没有尝试,具体见:这里。
四、hdfs文件操作
参考链接:(在chrome书签 Hadoop - HDFS中都有)
Permission denied: user=dr.who, access=READ_EXECUTE, inode="/tmp":student:supergroup:drwx------权限问题
Permission denied: user=administrator, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
# 在linux命令前加 hdfs dfs - hdfs dfs -help # 查看 新版本要加一个 /
hadoop fs -ls / # 删除
hadoop fs -rm -r /wordCount2 # 新建
hdfs dfs -mkdir /Test # 赋权
hadoop fs -chmod 777 /wordCount2
参考:
Ubuntu16.04+hadoop2.7.3环境搭建 !!
ubuntu16.04 +Java8+ hadoop2.x单机安装
Ubuntu安装Hadoop的更多相关文章
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
- Ubuntu 安装 hadoop
安装完Linux后,我们继续(VMWare 安装 Linux http://blog.csdn.net/hanjun0612/article/details/55095955) 这里我们开始学习安装 ...
- ubuntu安装hadoop经验
安装环境: 1 linux系统 2 或(windows下)虚拟机 本文在linux系统ubuntu下尝试安装hadoop 安装前提 1 安装JDK(安装oracle公司的JDK ) (1)检查是否已安 ...
- Ubuntu 安装hadoop 伪分布式
一.安装JDK : http://www.cnblogs.com/E-star/p/4437788.html 二.配置SSH免密码登录1.安装所需软件 sudo apt-get ins ...
- ubuntu安装hadoop 若干问题的解决
问题1:安装openssh-server失败 原因: 下列软件包有未满足的依赖关系: openssh-server : 依赖: openssh-client (= 1:5.9p1-5ubuntu1) ...
- Ubuntu - 安装hadoop(简约版)
相关版本: VMware ubuntuKylin16.04 JDK :openjdk Hadoop-2.9.1 步骤: 1.SSH 配置 [ 远程登陆 ] [ 配置SSH免码登陆 ] *测试:ssh ...
- 在Ubuntu上单机安装Hadoop
最近大数据比较火,所以也想学习一下,所以在虚拟机安装Ubuntu Server,然后安装Hadoop. 以下是安装步骤: 1. 安装Java 如果是新机器,默认没有安装java,运行java –ver ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- 安装Hadoop及Spark(Ubuntu 16.04)
安装Hadoop及Spark(Ubuntu 16.04) 安装JDK 下载jdk(以jdk-8u91-linux-x64.tar.gz为例) 新建文件夹 sudo mkdir /usr/lib/jvm ...
随机推荐
- python计算素数和
计算输入两个正整数x,y(x<=y,包括x,y)素数和.函数isPrime用以判断一个数是否素数,primeSum函数返回素数和 以下为源码 def isPrime(n) : for i ...
- webpack-dev-server live reloading 技术实现
webpack-dev-server live reloading https://github.com/webpack/webpack-dev-server Use webpack with a ...
- android shape 圆圈 圆环 圆角
定义圆圈:比如角标: xml布局文件 <TextView android:id="@+id/item_order_pay_count" android:layout_widt ...
- Ubuntu更新Python3及pip3
https://blog.csdn.net/good_tang/article/details/85001211 根据这篇文章的作者给出的方法进行的操作,但是其中出了两个问题: 我在操作之后重开bas ...
- Shiro权限模型以及权限分配的两种方式
1. 顶级账户分配权限用户需要被分配相应的权限才可访问相应的资源.权限是对于资源的操作一张许可证.给用户分配资源权限需要将权限的相关信息保存到数据库.这些相关内容包含:用户信息.权限管理.用户分配的权 ...
- Saltstack自动化操作记录(1)-环境部署【转】
早期运维工作中用过稍微复杂的Puppet,下面介绍下更为简单实用的Saltstack自动化运维的使用. Saltstack知多少Saltstack是一种全新的基础设施管理方式,是一个服务器基础架构集中 ...
- hikey960编译记录
arm64内核编译命令: 1 make ARCH=arm64 hikey960-defconfig 2 make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- ...
- 浅谈《Linux就该这么学》
就在去年十月份的时候,偶尔在Linux技术群了看到别人分享的<Linux就该这么学>,好奇的就点进去看看,当时看完首页,突然发现刘遄老师说到心坎里去了,于是就仔细看了看红帽认证的讲解以及后 ...
- sortable.js 拖拽排序及配置项说明
// 拖动排序 $(function() { /*排序*/ //排序 // Simple list ]; new Sortable(list, { group: "name", a ...
- PHP-高并发和大流量的解决方案
一 高并发的概念在互联网时代,并发,高并发通常是指并发访问.也就是在某个时间点,有多少个访问同时到来. 二 高并发架构相关概念1.QPS (每秒查询率) : 每秒钟请求或者查询的数量,在互联网领域 ...