hadoop生态之mapReduce-Yarn
一、inputSplit
1.什么是block
块是以 block size 进行划分数据。 因此,如果群集中的 block size 为 128 MB,则数据集的每个块将为 128 MB,除非最后一个块小于block size(文件大小不能被 block size 完全整除)。例如下图中文件大小为513MB,513%128=1,最后一个块(e)小于block size,大小为1MB。 因此,块是以 block size 的硬切割,并且块甚至可以在逻辑记录结束之前结束(blocks can end even before a logical record ends)。
假设我们的集群中block size 是128 MB,每个逻辑记录大约100 MB(假设为巨大的记录)。所以第一个记录将完全在一个块中,因为记录大小为100 MB小于块大小128 MB。但是,第二个记录不能完全在一个块中,因此第二条记录将出现在两个块中,从块1开始,在块2中结束
2.什么是inputSplit
如果分配一个Mapper给块1,在这种情况下,Mapper不能处理第二条记录,因为块1中没有完整第二条记录。因为HDFS不知道文件块中的内容,它不知道记录会什么时候可能溢出到另一个块(because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record might spill over into another block)。InputSplit这是解决这种跨越块边界的那些记录问题,Hadoop使用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。
当MapReduce作业客户端计算InputSplit时,它会计算出块中第一个完整记录的开始位置和最后一个记录的结束位置。在最后一个记录不完整的情况下,InputSplit 包括下一个块的位置信息和完成该记录所需的数据的字节偏移(In cases where the last record in a block is incomplete, the input split includes location information for the next block and the byte offset of the data needed to complete the record)。下图显示了数据块和InputSplit之间的关系:
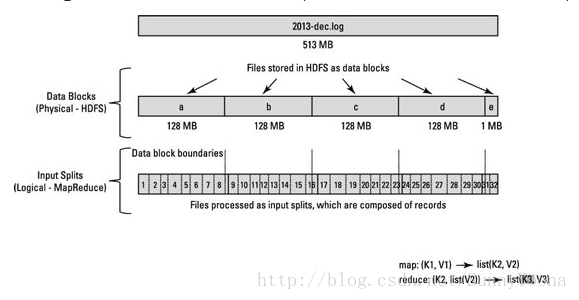
块是磁盘中的数据存储的物理块,其中InputSplit不是物理数据块。 它是一个Java类,指向块中的开始和结束位置。 因此,当Mapper尝试读取数据时,它清楚地知道从何处开始读取以及在哪里停止读取。 InputSplit的开始位置可以在块中开始,在另一个块中结束。InputSplit代表了逻辑记录边界,在MapReduce执行期间,Hadoop扫描块并创建InputSplits,并且每个InputSplit将被分配给一个Mapper进行处理。
hadoop生态之mapReduce-Yarn的更多相关文章
- Hadoop生态集群YARN详解
一,前言 Hadoop 2.0由三个子系统组成,分别是HDFS.YARN和MapReduce,其中,YARN是一个崭新的资源管理系统,而MapReduce则只是运行在YARN上的一个应用,如果把YAR ...
- Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现. (1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop生态常用数据模型
Hadoop生态常用数据模型 一.TextFile 二.SequenceFile 1.特性 2.存储结构 3.压缩结构与读取过程 4.读写操作 三.Avro 1.特性 2.数据类型 3.avro-to ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- 每天收获一点点------Hadoop之初始MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
随机推荐
- AndroidStudio使用问题记录
问题: Gradle sync failed: Connection timed out: connect Consult IDE log for more details (Help | Show ...
- Python 经典面试题汇总之框架篇
前端和框架 1.谈谈你对http协议的认识 浏览器本质,socket客户端遵循Http协议 HTTP协议本质:通过\r\n分割的规范,请求响应之后断开链接 ==> 短连接.无状态 具体: Htt ...
- sqlserver简便创建用户并授权
很多研发人员程序连接SQL Server直接用的就是SA帐号.如果对数据库管理稍微严格一点的话,就不应该给应用程序这种权限,通常应用程序只需要进行增删改查,而很少有DDL操作,因此配置帐号时应该遵循“ ...
- June 28th. 2018, Week 26th. Thursday
You cannot change the circumstances but you can change yourself. 既然改变不了环境,那就改变自己. From Jim Rohn. Rec ...
- 让自己的开源项目支持CocoaPods
测试的时候找个自己封装的方法或UI控件就可以了 这里用我刚封装的Redirect重定向的请求体为例 1, 在github上创建一个Redirect,重要:记得选择开源协议 (MIT)(如果木有GitH ...
- pycharm中运行时添加配置 及pytest模式怎么修改为run模式
会发现不是控制台输出,而是pytest模式. 修改: 当运行时,发现无法运行: 然后点击Add Configuration, 点击加号,点击Python: 选择脚本路径和解释器.点击OK即可.
- Google Chrome即将开始警告—停止支持Flash Player
Adobe 计划在 2020 年让 Flash Player 彻底退休,整个科技行业都在为这个关键时刻做准备,包括浏览器开发机构,Google 作为最主要的一员,试图尽可能顺利地完成 Flash Pl ...
- EXT 设置编辑框为只读
Ext.getCmp("processResult").setReadOnly(ture); //processResult是属性的id,setReadOnly(ture)设置 ...
- Vue中循环的反人类设计
今天学习Vue到循环那里,表示真是不能理解Vue的反人类设计 具体看代码吧! <!DOCTYPE html> <html> <head> <meta char ...
- $_SERVER['HTTP_REFERER']的使用
转载:http://www.5idev.com/p-php_server_http_referer.shtml 使用 $_SERVER['HTTP_REFERER'] 将很容易得到链接到当前页面的前一 ...