wiki中文语料的word2vec模型构建
一、利用wiki中文语料进行word2vec模型构建
1)数据获取
到wiki官网下载中文语料,下载完成后会得到命名为zhwiki-latest-pages-articles.xml.bz2的文件,里面是一个XML文件
下载地址如下:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
其中:https://dumps.wikimedia.org/zhwiki/latest/提供wiki各种文件下载,而且在不停的更新
本人已经下载并上传百度云盘,链接:https://pan.baidu.com/s/1kzMwGwVR4h0wuOYU70aUhA 提取码:2axt
然后在桌面新建wiki中文语料的word2vec模型构建文件夹,将下载的压缩文件放在内,进入wiki中文语料的word2vec模型构建文件夹,按住shift+右键,选择在此处打开命令窗口
输入jupyter notebook,新建一个名为:wiki_word2vec_test的脚本文件:
2)将XML的Wiki数据转换为text格式
使用gensim.corpora中的WikiCorpus函数来处理维基百科的数据,转换后生成的文件wiki.zh.txt
import logging
import sys
import os from gensim.corpora import WikiCorpus program = os.path.basename( sys.argv[0] )
logger = logging.getLogger(program) logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info( "running %s" % ' '.join(sys.argv) ) inp = 'zhwiki-latest-pages-articles.xml.bz2'
outp = 'wiki.zh.txt'
space = ' '
i = 0
output = open(outp, 'w', encoding='utf-8')
#gensim里的维基百科处理类WikiCorpu
wiki = WikiCorpus(inp, lemmatize=False, dictionary=[] ) #通过get_texts将维基里的每篇文章转换为1行text文本,并且去掉了标点符号等内容
for text in wiki.get_texts():
output.write( space.join(text) + '\n' )
i += 1
if ( i % 10000 == 0):
logger.info('Saved ' + str(i) + ' articles.') output.close()
logger.info('Finished Saved ' + str(i) + ' articles.')
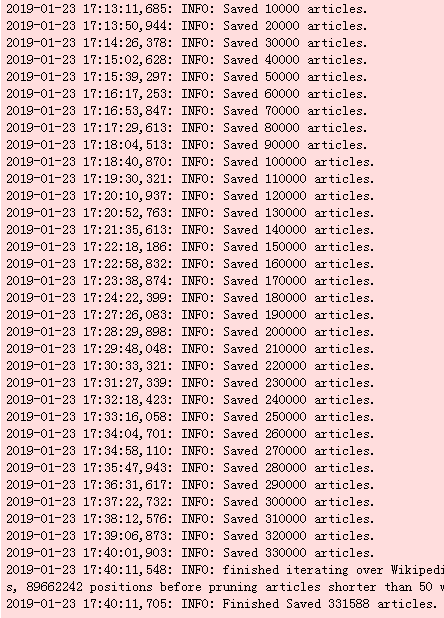
从下面的结果看27min处理了331588条数据,还是比较慢的,已经将wiki.zh.txt上传云盘,并且被压缩:
链接:https://pan.baidu.com/s/1g7d87ztvAdr8CZd2rCnvOg 提取码:42x5
3)中文繁体转简体
Wiki中文语料中包含了很多繁体字,需要转成简体字再进行处理,这里使用到了OpenCC工具进行转换
安装OpenCC:下载对应版本的OpenCC,https://bintray.com/package/files/byvoid/opencc/OpenCC,本人选择的是win 64位
下载解压后,在wiki中文语料的word2vec模型构建文件夹下打开dos窗口:
opencc -i wiki.zh.txt -o wiki.zh.simp.txt -c t2s.json
#注意可以添加上opencc的绝对路径,t2s.json也要加绝对路径

则会得到文件wiki.zh.simp.txt,即转成了简体的中文,由于文件过大,无法直接打开查看,我们使用代码查看前2行:
import codecs,sys
i = 0
f = codecs.open('wiki.zh.txt','r',encoding="utf-8")
for eachline in f:
i += 1
if (i < 3):
print(eachline)
else:
break
可以看出有很多繁体字:

我们再来看看繁体转简体后:
import codecs,sys
i = 0
f = codecs.open('wiki.zh.simp.txt','r',encoding="utf-8")
for eachline in f:
i += 1
if (i < 3):
print(eachline)
else:
break
是不是都看懂了呢?

其中的wiki.zh.simp.txt简体文件以及被我压缩,并上传至云盘:
链接:https://pan.baidu.com/s/1Gx1iWORvKvmd5AzaZY3raw 提取码:45k5
4)jieba分词
本例中采用结巴分词对字体简化后的wiki中文语料数据集进行分词。由于此语料已经去除了标点符号,因此在分词程序中无需进行清洗操作,可直接分词
若是自己采集的数据还需进行标点符号去除和去除停用词的操作
import jieba
import jieba.analyse
import codecs def prepareData(sourceFile, targetFile):
f =codecs.open(sourceFile, 'r', encoding='utf-8')
target = codecs.open(targetFile, 'w', encoding='utf-8')
print( 'open source file: '+ sourceFile )
print( 'open target file: '+ targetFile ) lineNum = 0
for eachline in f:
lineNum += 1
if lineNum % 1000 == 0:
print('---processing ', sourceFile, lineNum,' article---')
seg_list = jieba.cut(eachline, cut_all=False)
line_seg = ' '.join(seg_list)
target.write(line_seg+ '\n')
print('---Well Done!!!---' * 4)
f.close()
target.close() sourceFile = 'wiki.zh.simp.txt'
targetFile = 'wiki.zh.simp.seg.txt'
prepareData(sourceFile, targetFile)
查看分词结果文件-wiki.zh.simp.seg.txt
import codecs,sys
i = 0
f = codecs.open('wiki.zh.simp.seg.txt','r',encoding="utf-8")
for eachline in f:
i += 1
if (i < 3):
print(eachline)
else:
break

其中分词结果文件wiki.zh.simp.seg.txt已经被压缩并上传云盘:
链接:https://pan.baidu.com/s/15R75m5T2WlyjMagqkXbI6g 提取码:zr46
5)Word2Vec模型训练
分好词的文档即可进行word2vec词向量模型的训练了。文档较大,需要内存较大,具体Python代码实现如下所示:
import os
import sys
import logging
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import multiprocessing program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s',level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv)) # inp为输入语料, outp1 为输出模型, outp2为原始c版本word2vec的vector格式的模型
inp = 'wiki.zh.simp.seg.txt'
outp1 = 'wiki.zh.text.model'
outp2 = 'wiki.zh.text.vector' #训练skip-gram 模型
model = Word2Vec( LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count() )
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
摘取了最后几行代码运行信息,代码运行完成后得到如下四个文件,其中wiki.zh.text.model是建好的模型,wiki.zh.text.vector是词向量,是每个词对应的词向量,可以在此基础上作文本特征的提取以及分类

其中wiki.zh.text.mode和wiki.zh.text.vector文件已经上传云盘:
wiki.zh.text.mode:https://pan.baidu.com/s/1mlZ_5-mY3GerWnvYADt3sA 提取码:7p83
wiki.zh.text.vector:https://pan.baidu.com/s/16vEVQ79FkmVFwMPrA3G5mg 提取码:aaa5
6)模型测试
模型训练好后,来测试模型的结果
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')# 忽略警告
import sys import gensim
model = gensim.models.Word2Vec.load('wiki.zh.text.model')
#与足球最相似的
word = model.most_similar("足球")
for each in word:
print(each[0], each[1]) print('*' * 20) word = model.most_similar(positive=['皇上','国王'],negative=['皇后'])
for t in word:
print (t[0],t[1]) print(model.doesnt_match('太后 妃子 贵人 贵妃 才人'.split(' ')))
print('*' * 20) print(model.similarity('书籍','书本'))
print('*' * 20)
print(model.similarity('逛街','书本'))

7)致谢
至此,使用python对中文wiki语料的词向量建模就全部结束了,wiki.zh.text.vector中是每个词对应的词向量,可以在此基础上作文本特征的提取以及分类
本文参考:https://github.com/AimeeLee77/wiki_zh_word2vec
感谢作者的分享,为后续情感分析打下了基础
wiki中文语料的word2vec模型构建的更多相关文章
- wiki中文语料+word2vec (python3.5 windows win7)
环境: win7+python3.5 1. 下载wiki中文分词语料 使用迅雷下载会快不少,大小为1个多G https://dumps.wikimedia.org/zhwiki/late ...
- 基于CBOW网络手动实现面向中文语料的word2vec
最近在工作之余学习NLP相关的知识,对word2vec的原理进行了研究.在本篇文章中,尝试使用TensorFlow自行构建.训练出一个word2vec模型,以强化学习效果,加深理解. 一.背景知识: ...
- word2vec词向量处理中文语料
word2vec介绍 word2vec官网:https://code.google.com/p/word2vec/ word2vec是google的一个开源工具,能够根据输入的词的集合计算出词与词之间 ...
- NLP学习(4)----word2vec模型
一. 原理 哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html 负采样推导: http://www.hankcs.com/nlp/word2v ...
- 利用RNN进行中文文本分类(数据集是复旦中文语料)
利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) 1.训练词向量 数据预处理参考利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) ,现在我们有了分词 ...
- word2vec模型评估方案
1.word2vec参数详解 · sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建.· sg: 用于设置训练算 ...
- Word2Vec模型参数 详解
用gensim函数库训练Word2Vec模型有很多配置参数.这里对gensim文档的Word2Vec函数的参数说明进行翻译,以便不时之需. class gensim.models.word2vec.W ...
- 基于tensorflow的文本分类总结(数据集是复旦中文语料)
代码已上传到github:https://github.com/taishan1994/tensorflow-text-classification 往期精彩: 利用TfidfVectorizer进行 ...
- word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用了CBOW(Continuous B ...
随机推荐
- redhat yum ISO 本地源
先将ISO文件挂载起来: [root@racdb1 ~]# mount -o loop /opt/soft/rhel-server-6.8-x86_64-dvd.iso /mnt/iso [root@ ...
- 雨后清风教你如何在Windows 7中对硬盘进行分区
磁盘分区是将硬盘驱动器分成多个逻辑单元.人们通常不会选择对硬盘进行分区,但它有很多好处.主要是,通过对磁盘进行分区,您可以将操作系统与数据分开,从而减少数据损坏的可能性. 磁盘分区方法 打开“计算机管 ...
- WMware workstation中几种网络连接的说明 【转】
博客来源:WMware workstation中几种网络连接的说明 VMware workstation中几种网络连接的说明 WMware workstation中网络连接包括,桥接模式.NAT模式. ...
- Centos7.5 部署postfix邮件系统
1. Postfix 1.1 邮件服务的介绍 电子邮件是—种用电子手段提供信息交换的通信方式,是互联网应用最广的服务.通过网络的电子邮件系统,用户可以以非常低廉的价格(不管发送到哪里,都只需负担网费) ...
- Extjs 判断对象是非为null或者为空字符串
Ext.isEmpty(str,[allowEmptyString]) 如果str为 null undefined a zero-length array a zero-length string ( ...
- kaptcha验证码的使用
使用kaptcha可以方便的配置: 验证码的字体 验证码字体的大小 验证码字体的字体颜色 验证码内容的范围(数字,字母,中文汉字!) 验证码图片的大小,边框,边框粗细,边框颜色 验证码的干扰线(可以自 ...
- centos下 telnet访问百度
先在命令行输入以下命令: telnet www.baidu.com 80 点击确认之后出现如下界面 然后接着输入以下两行命令 GET /index.html HTTP/1.1 Host: www.ba ...
- Django视图(views)
1.FBV (基于函数的视图) 实例 url.py url(r'^add_publicer/',views.add_publicer) def add_publicer(request): if re ...
- Nginx(三)------nginx 反向代理
Nginx 服务器的反向代理服务是其最常用的重要功能,由反向代理服务也可以衍生出很多与此相关的 Nginx 服务器重要功能,比如后面会介绍的负载均衡.本篇博客我们会先介绍 Nginx 的反向代理,当然 ...
- .Net Core应用框架Util介绍(三)
上篇介绍了Util的开发环境,并让你把Demo运行起来.本文将介绍该Demo的前端Angular运行机制以及目录结构. 目录结构 在VS上打开Util Demo,会看见如下的目录结构. 现代前端通常采 ...