使用C#程序处理PowerPoint文件中的字符串
最近, 有同事偶然发现Microsoft Office PowerPoint可以被看作是一个压缩包,然后通过WinRAR解压出来一组XML文件。解压出来的文件包括:
一个索引文件名称为:[Content_Types].xml,
一个名为ppt的文件夹,在其内有两个重要的子文件夹:slides 和notesSlides
其中, [Content_Types].xml记录了每一张Slide的相对路径,每一个Slide note的相对路径。其内容如下图:
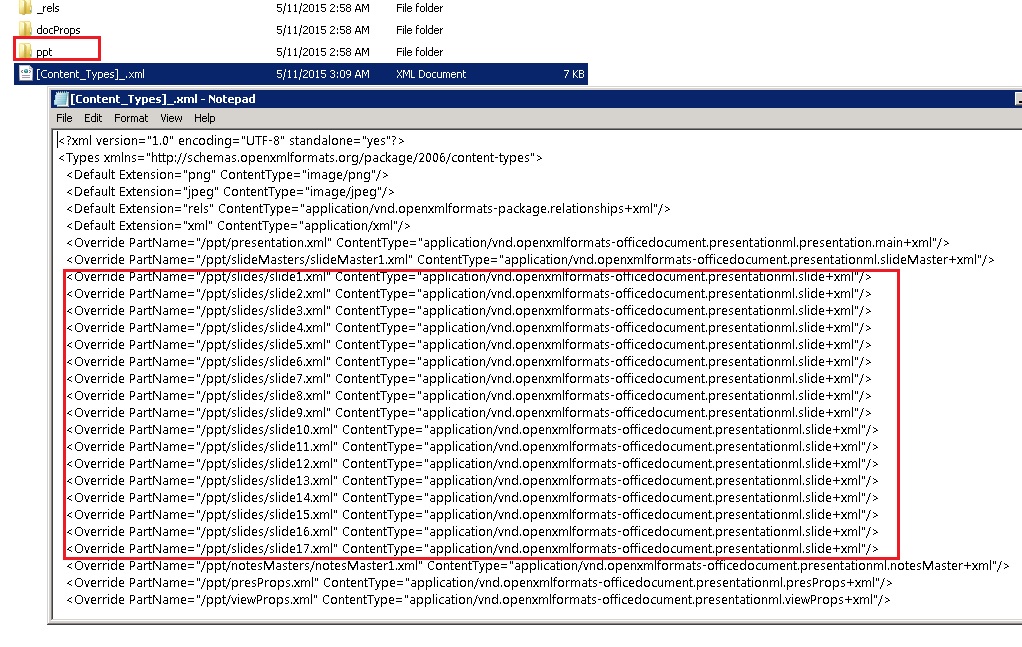
我们发现PPT中的所有内容都被记录在XML的<a:t></a:t>节点中, 所以,我们通过把所有a:t节点的内容导出,然后对内容进行修改,修改后再替换回原文件,这样将这一组文件进行压缩,生成了修改后的PowerPoint文件,该过程为PowerPoint的内容本地化提供了便捷途径。
这种做法相比较于调用Microsoft.Office.Interop.PowerPoint中的API的做法来说, 保留了原文的100%的格式,不需要后期PPT刷格式的操作。
以下是我们写的C#代码, 思路是将每张Slide的字符串导出到一个txt文件,通过trados翻译txt文件中的字符串,然后将修改后内容导入到PPT包内相应的XML文件中。
PPTZIPCommon
class PPTZIPCommon
{
/// <summary>
/// read file [Content_Types].xml
/// </summary>
/// <param name="root"></param>
/// <param name="SlideFiles">return slides </param>
/// <param name="NotesFiles">return slide notes</param>
internal static void ReadContentTypes(string root, ref List<string> SlideFiles, ref List<string> NotesFiles)
{
string ct_file = @"[Content_Types].xml";
string ct_fullName = Path.Combine(root, ct_file); if (!File.Exists(ct_fullName))
{
MessageBox.Show(string.Format("the [Content_Types].xml not exist in {0}", root));
return;
}
XmlDocument xml_doc = new XmlDocument();
xml_doc.Load(ct_fullName);
XmlElement rootElement = xml_doc.DocumentElement;
string slide_types = "application/vnd.openxmlformats-officedocument.presentationml.slide+xml";
string notes_types = "application/vnd.openxmlformats-officedocument.presentationml.notesSlide+xml"; XmlNodeList nodes = rootElement.ChildNodes;
foreach (XmlElement node in nodes)
{
if (node.Attributes["ContentType"].Value == slide_types)
{
string relatedPath = node.Attributes["PartName"].Value.Remove(, ).Replace(@"/", @"\");
string file = Path.Combine(root, relatedPath);
SlideFiles.Add(file);
}
else if (node.Attributes["ContentType"].Value == notes_types)
{
string relatedPath = node.Attributes["PartName"].Value.Remove(, ).Replace(@"/", @"\");
string file = Path.Combine(root, relatedPath);
NotesFiles.Add(file);
}
}
} internal static string GetPPTNameFromFullPath(string scanFolder)
{
int lastIndexOfSlash = scanFolder.LastIndexOf(@"\");
if (lastIndexOfSlash == scanFolder.Length - )
{
scanFolder = scanFolder.Remove(lastIndexOfSlash);
} string lastString = scanFolder.Substring(scanFolder.LastIndexOf(@"\") + );
string[] names = lastString.Split(new string[] { "." }, StringSplitOptions.RemoveEmptyEntries);
return names[];
}
}
PPTZIP
class PPTZIP
{
private static List<string> SlideFiles = new List<string>();
private static List<string> NotesFiles = new List<string>(); /// <summary>
/// collect together all the <a:t>...</a:t> strings, put it in txt file
/// txt file be saved to output\<original PPT name>_<fileName>.txt
/// </summary>
/// <param name="file">xml file that contains <a:t>...</a:t></param>
/// <param name="output">the txt file be saved to the output folder</param>
/// <param name="pptName">original PowerPoint file name</param>
private static void ReadATContent2TXT(string file, string output, string pptName)
{
StringBuilder sb = new StringBuilder();
using (StreamReader reader = new StreamReader(file))
{
string content = reader.ReadToEnd();
string pattern = @"<a:t>.[^<>]+</a:t>";
MatchCollection mc = Regex.Matches(content, pattern); for (int i = ; i < mc.Count; i++)
{
sb.AppendLine(string.Format("{0}^", mc[i].Value.Substring(, mc[i].Value.LastIndexOf("<") - )));
}
} FileInfo fi = new FileInfo(file);
string txtFile = Path.Combine(output, pptName+"_"+fi.Name + ".txt");
using (StreamWriter writer = new StreamWriter(txtFile))
{
writer.Write(sb.ToString().Trim());
writer.Flush();
writer.Close();
}
} public static void Export2TXTs(string scanFolder)
{
string ppt_name = PPTZIPCommon.GetPPTNameFromFullPath(scanFolder); PPTZIPCommon.ReadContentTypes(scanFolder, ref SlideFiles, ref NotesFiles); if (null != SlideFiles && SlideFiles.Count > )
{
foreach (var file in SlideFiles)
{
string outputfolder = Path.Combine(scanFolder, "SlideTXTs");
if (!Directory.Exists(outputfolder))
Directory.CreateDirectory(outputfolder);
string transFolder = Path.Combine(scanFolder, "SlideTXTs_Trans");
if (!Directory.Exists(transFolder))
Directory.CreateDirectory(transFolder); ReadATContent2TXT(file, outputfolder, ppt_name);
}
} if (null != NotesFiles && NotesFiles.Count > )
{
foreach (var file in NotesFiles)
{
string outputfolder = Path.Combine(scanFolder, "NotesTXTs");
if (!Directory.Exists(outputfolder))
Directory.CreateDirectory(outputfolder);
string transFolder = Path.Combine(scanFolder, "NotesTXTs_Trans");
if (!Directory.Exists(transFolder))
Directory.CreateDirectory(transFolder); ReadATContent2TXT(file, outputfolder,ppt_name);
} }
}
}
PPTZIPWriter
class PPTZIPWriter
{
private static List<string> SlideFiles = new List<string>();
private static List<string> NotesFiles = new List<string>(); private static void Replace(string file, List<string> original, List<string> translated)
{
string content = string.Empty;
using (StreamReader reader = new StreamReader(file))
{
content = reader.ReadToEnd();
for (int i = ; i < original.Count; i++)
{
content = content.Replace(string.Format("<a:t>{0}</a:t>", original[i]), string.Format("<a:t>{0}</a:t>", translated[i]));
} reader.Close();
} using (StreamWriter writer = new StreamWriter(file))
{
writer.Write(content);
writer.Flush();
writer.Close();
} } public static void Import2PPT(string scanFolder, string lan)
{
string ppt_name = PPTZIPCommon.GetPPTNameFromFullPath(scanFolder); // fullfill the two lists: SlideFiles and NotesFiles
PPTZIPCommon.ReadContentTypes(scanFolder,ref SlideFiles, ref NotesFiles); string srcFolder = "SlideTXTs";
string trgFolder = "SlideTXTs_Trans"; string srcFullPath = Path.Combine(scanFolder, srcFolder);
string trgFullPath = Path.Combine(scanFolder, trgFolder);
foreach (var file in SlideFiles)
{
ReplaceATContent(file, srcFullPath, trgFullPath, ppt_name, lan);
} string srcFolderNotes = "NotesTXTs";
string trgFolderNotes = "NotesTXTs_Trans";
string srcFullPath_trans = Path.Combine(scanFolder, srcFolderNotes);
string trgFullPath_trans = Path.Combine(scanFolder, trgFolderNotes);
foreach (var file in NotesFiles)
{
ReplaceATContent(file, srcFullPath_trans, trgFullPath_trans, ppt_name, lan);
}
} private static void ReplaceATContent(string file, string srcFolder, string trgFolder, string pptName, string lan)
{
if (!(Directory.Exists(srcFolder) && Directory.Exists(trgFolder)))
{
MessageBox.Show("SlideTXTs/NotesTXTs or SlideTXTs_Trans/NotesTXTs_Trans not exist");
return;
} FileInfo fi = new FileInfo(file);
string srcFileName = string.Format("{0}_{1}.txt",pptName,fi.Name);
string srcFileFullPath = Path.Combine(srcFolder, srcFileName); string trgFileName= string.Empty;
if(lan==string.Empty)
trgFileName = string.Format("{0}_{1}.txt", pptName, fi.Name);
else
trgFileName = string.Format("{0}_{1}_{2}.txt",pptName, fi.Name,lan);
string trgFileFullPath = Path.Combine(trgFolder, trgFileName); if (!(File.Exists(srcFileFullPath) && File.Exists(trgFileFullPath)))
{
MessageBox.Show(string.Format(@"File {0} not replaced",file));
return;
} List<string> originalString = new List<string>();
using (StreamReader reader = new StreamReader(srcFileFullPath))
{
string content = reader.ReadToEnd().Trim();
string[] strings = content.Split(new string[] { "^" }, StringSplitOptions.RemoveEmptyEntries);
for (int i = ; i < strings.Length; i++)
{
originalString.Add(strings[i].Contains("\r\n") ? strings[i].Remove(, ) : strings[i]);
}
} List<string> translatedString = new List<string>();
using (StreamReader reader = new StreamReader(trgFileFullPath))
{
string content = reader.ReadToEnd().Trim();
string[] strings = content.Split(new string[] { "^" }, StringSplitOptions.RemoveEmptyEntries);
for (int i = ; i < strings.Length; i++)
{
translatedString.Add(strings[i].Contains("\r\n") ? strings[i].Remove(, ) : strings[i]);
}
} if (originalString.Count != translatedString.Count)
{
MessageBox.Show(string.Format(@"translation string count not match:{0}",file));
return;
} Replace(file, originalString, translatedString);
}
}
使用C#程序处理PowerPoint文件中的字符串的更多相关文章
- python 小程序,替换文件中的字符串
[root@PythonPC ~]# cat passwd root:x:::root:/root:/bin/bash bin:x:::bin:/bin:/sbin/nologin daemon:x: ...
- 在文件夹中 的指定类型文件中 查找字符串(CodeBlocks+GCC编译,控制台程序,仅能在Windows上运行)
说明: 程序使用 io.h 中的 _findfirst 和 _findnext 函数遍历文件夹,故而程序只能在 Windows 下使用. 程序遍历当前文件夹,对其中的文件夹执行递归遍历.同时检查遍历到 ...
- Java基础知识强化之IO流笔记52:IO流练习之 把一个文件中的字符串排序后再写入另一个文件案例
1. 把一个文件中的字符串排序后再写入另一个文件 已知s.txt文件中有这样的一个字符串:"hcexfgijkamdnoqrzstuvwybpl" 请编写程序读取数据内容,把数据排 ...
- linux上查找文件存放地点和文件中查找字符串方法
一.查找文件存放地点 1.locate 语法:locate <filename> locate命令实际是"find -name"的另一种写法,但是查找方式跟find不同 ...
- Objective-C 【从文件中读写字符串(直接读写/通过NSURL读写)】
———————————————————————————————————————————从文件中读写字符串(直接读写/通过NSURL读写) #import <Foundation/Foundati ...
- Linux命令行批量替换多文件中的字符串【转】
Linux命令行批量替换多文件中的字符串[转自百度文库] 一种是Mahuinan法,一种是Sumly法,一种是30T法分别如下: 一.Mahuinan法: 用sed命令可以批量替换多个文件中的字符串. ...
- c++ 读取不了hdf5文件中的字符串
问题描述: 在拿到一个hdf5文件,想用c++去读取文件中的字符串,但是会报错:read failed ps: c++读取hdf5的字符串方法见:https://support.hdfgroup.or ...
- 新手C#s.Split(),s.Substring(,)以及读取txt文件中的字符串的学习2018.08.05
s.split()用于字符串分割,具有多种重载方法,可以通过指定字符或字符串分割原字符串成为字符串数组. //s.Split()用于分割字符串为字符串数组,StringSplitOptions.Rem ...
- 使用 awk 过滤文本或文件中的字符串
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分.这时正则表达式就派上用场了. 什么是正则表达式? 正则表达式可以定义为代表若干 ...
随机推荐
- canvas绘图
1.//获取canvas容器var can = document.getElementById('canvas');//创建一个画布var ctx = can.getContext('2d');2.绘 ...
- Could not parse mapping document from input stream
无法从输入流解析映射文档 1.定义的类名或属性名不对,如:*.hbm.xml文件中属性name对应的实体类name不一致.2.xml头文件中"http://www.hibernate.org ...
- ASP.NET POST XML JSON数据,发送与接收
接收端通过Request.InputStream读取:byte[] byts = new byte[Request.InputStream.Length];Request.InputStream.Re ...
- 基于事件的异步模式(EAP)
什么是EAP异步编程模式 EAP基于事件的异步模式是.net 2.0提出来的,实现了基于事件的异步模式的类将具有一个或者多个以Async为后缀的方法和对应的Completed事件,并且这些类都支持异步 ...
- AutoHotkey(AHK)
这是2009年用过的一个软件,自动键盘执行的一个东西,能提高效率,代替人工击键和鼠标操作,现在中文化很好了,如下地址是中文文档 http://ahkcn.sourceforge.net/docs/Tu ...
- MD5使用
MD5加密算法,即"Message-Digest Algorithm 5(信息-摘要算法)",它由MD2.MD3.MD4发展而来的一种单向函数算法(也就是HASH算法),它是国际著 ...
- 如何在HTML5 Canvas 里面显示 Font Awesome 图标
Font Awesome 是一套完美的图标字体,主要目的是和 Bootstrap 搭配使用. 提供的CSS 已经可以完美显示这些图标在网页里面.最新的版本4.3 里面,已经提供519 Icon ...
- Websocket 协议解析
WebSocket protocol 是HTML5一种新的协议.它是实现了浏览器与服务器全双工通信(full-duplex). 现 很多网站为了实现即时通讯,所用的技术都是轮询(po ...
- 常用的CSS定位,XPath定位和JPath定位
CSS定位 举例 描述 div#menu id为menu的div元素 div.action-btn.ok-btn class为action-btn和ok-btn的div元素 table#emailLi ...
- sql server数据库连接问题处理
下面请一字一句地看,一遍就设置成功,比你设置几十遍失败,费时会少得多. 首先,在连接数据库之前必须保证SQL Server 2012是采用SQL Server身份验证方式而不是windows身份验证方 ...