拓扑排序(三)之 Java详解
前面分别介绍了拓扑排序的C和C++实现,本文通过Java实现拓扑排序。
目录
1. 拓扑排序介绍
2. 拓扑排序的算法图解
3. 拓扑排序的代码说明
4. 拓扑排序的完整源码和测试程序转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
拓扑排序介绍
拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。
这样说,可能理解起来比较抽象。下面通过简单的例子进行说明!
例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
拓扑排序的算法图解
拓扑排序算法的基本步骤:
1. 构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
2. 把所有没有依赖顶点的节点放入Q;
3. 当Q还有顶点的时候,执行下面步骤:
3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
3.2 对n每一个邻接点m(n是起点,m是终点);
3.2.1 去掉边<n,m>;
3.2.2 如果m没有依赖顶点,则把m放入Q;
注:顶点A没有依赖顶点,是指不存在以A为终点的边。
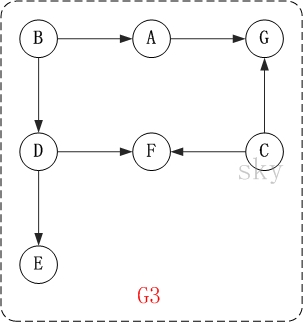
以上图为例,来对拓扑排序进行演示。

第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
(01) 将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
(02) 将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
拓扑排序的代码说明
拓扑排序是对有向无向图的排序。下面以邻接表实现的有向图来对拓扑排序进行说明。
1. 基本定义
public class ListDG {
// 邻接表中表对应的链表的顶点
private class ENode {
int ivex; // 该边所指向的顶点的位置
ENode nextEdge; // 指向下一条弧的指针
}
// 邻接表中表的顶点
private class VNode {
char data; // 顶点信息
ENode firstEdge; // 指向第一条依附该顶点的弧
};
private VNode[] mVexs; // 顶点数组
...
}
(01) ListDG是邻接表对应的结构体。 mVexs则是保存顶点信息的一维数组。
(02) VNode是邻接表顶点对应的结构体。 data是顶点所包含的数据,而firstEdge是该顶点所包含链表的表头指针。
(03) ENode是邻接表顶点所包含的链表的节点对应的结构体。 ivex是该节点所对应的顶点在vexs中的索引,而nextEdge是指向下一个节点的。
2. 拓扑排序
/*
* 拓扑排序
*
* 返回值:
* -1 -- 失败(由于内存不足等原因导致)
* 0 -- 成功排序,并输入结果
* 1 -- 失败(该有向图是有环的)
*/
public int topologicalSort() {
int index = 0;
int num = mVexs.size();
int[] ins; // 入度数组
char[] tops; // 拓扑排序结果数组,记录每个节点的排序后的序号。
Queue<Integer> queue; // 辅组队列
ins = new int[num];
tops = new char[num];
queue = new LinkedList<Integer>();
// 统计每个顶点的入度数
for(int i = 0; i < num; i++) {
ENode node = mVexs.get(i).firstEdge;
while (node != null) {
ins[node.ivex]++;
node = node.nextEdge;
}
}
// 将所有入度为0的顶点入队列
for(int i = 0; i < num; i ++)
if(ins[i] == 0)
queue.offer(i); // 入队列
while (!queue.isEmpty()) { // 队列非空
int j = queue.poll().intValue(); // 出队列。j是顶点的序号
tops[index++] = mVexs.get(j).data; // 将该顶点添加到tops中,tops是排序结果
ENode node = mVexs.get(j).firstEdge;// 获取以该顶点为起点的出边队列
// 将与"node"关联的节点的入度减1;
// 若减1之后,该节点的入度为0;则将该节点添加到队列中。
while(node != null) {
// 将节点(序号为node.ivex)的入度减1。
ins[node.ivex]--;
// 若节点的入度为0,则将其"入队列"
if( ins[node.ivex] == 0)
queue.offer(node.ivex); // 入队列
node = node.nextEdge;
}
}
if(index != num) {
System.out.printf("Graph has a cycle\n");
return 1;
}
// 打印拓扑排序结果
System.out.printf("== TopSort: ");
for(int i = 0; i < num; i ++)
System.out.printf("%c ", tops[i]);
System.out.printf("\n");
return 0;
}
说明:
(01) queue的作用就是用来存储没有依赖顶点的顶点。它与前面所说的Q相对应。
(02) tops的作用就是用来存储排序结果。它与前面所说的T相对应。
拓扑排序的完整源码和测试程序
拓扑排序(三)之 Java详解的更多相关文章
- 拓扑排序(二)之 C++详解
本章是通过C++实现拓扑排序. 目录 1. 拓扑排序介绍 2. 拓扑排序的算法图解 3. 拓扑排序的代码说明 4. 拓扑排序的完整源码和测试程序 转载请注明出处:http://www.cnblogs. ...
- Prim算法(三)之 Java详解
前面分别通过C和C++实现了普里姆,本文介绍普里姆的Java实现. 目录 1. 普里姆算法介绍 2. 普里姆算法图解 3. 普里姆算法的代码说明 4. 普里姆算法的源码 转载请注明出处:http:// ...
- Kruskal算法(三)之 Java详解
前面分别通过C和C++实现了克鲁斯卡尔,本文介绍克鲁斯卡尔的Java实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3. 克鲁斯卡尔算法图解 4. 克鲁斯卡尔算法分析 5. 克鲁斯卡尔算法的 ...
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
- 邻接表有向图(三)之 Java详解
前面分别介绍了邻接表有向图的C和C++实现,本文通过Java实现邻接表有向图. 目录 1. 邻接表有向图的介绍 2. 邻接表有向图的代码说明 3. 邻接表有向图的完整源码 转载请注明出处:http:/ ...
- 邻接矩阵有向图(三)之 Java详解
前面分别介绍了邻接矩阵有向图的C和C++实现,本文通过Java实现邻接矩阵有向图. 目录 1. 邻接矩阵有向图的介绍 2. 邻接矩阵有向图的代码说明 3. 邻接矩阵有向图的完整源码 转载请注明出处:h ...
- 邻接表无向图(三)之 Java详解
前面分别介绍了邻接表无向图的C和C++实现,本文通过Java实现邻接表无向图. 目录 1. 邻接表无向图的介绍 2. 邻接表无向图的代码说明 3. 邻接表无向图的完整源码 转载请注明出处:http:/ ...
- 邻接矩阵无向图(三)之 Java详解
前面分别介绍了邻接矩阵无向图的C和C++实现,本文通过Java实现邻接矩阵无向图. 目录 1. 邻接矩阵无向图的介绍 2. 邻接矩阵无向图的代码说明 3. 邻接矩阵无向图的完整源码 转载请注明出处:h ...
- 哈夫曼树(三)之 Java详解
前面分别通过C和C++实现了哈夫曼树,本章给出哈夫曼树的java版本. 目录 1. 哈夫曼树的介绍 2. 哈夫曼树的图文解析 3. 哈夫曼树的基本操作 4. 哈夫曼树的完整源码 转载请注明出处:htt ...
随机推荐
- 为什么page对象不适合用ThreadLocal
今天测试了下,在action中决定是否设置page,在dao层中取出分页,确实没有问题.但是,有一种情况不行,在service中查询了两次数据库,都共享这个page对象了?结果就乱了. 谁有更好解决方 ...
- 织梦CMS实现多条件筛选功能
用织梦实现筛选的功能,其实主要就是运用到了织梦的高级搜索功能,然后用ajax去post替换掉本来的结果就可以了. 其实筛选的话,主要有两个问题需要解决,一个是前台的筛选实现,一个是后台根据前台的点击, ...
- Python 之 lamda 函数
1.例子 语法:lambda [args1,argus2....]:expression map(lambda x: x*x, [y for y in range(10)]) lambda:" ...
- MySQL JDBC 出现多个 SHOW VARIABLES 语句。
一次偶然的机会,show processlist 的时候,发现有个 Client 一直在执行 "mysql-connector-java-5.1.21 ( Revision: ${bzr. ...
- mongoDB研究笔记:复制集概述
自我学习,仅供参考: 数据库总是会遇到各种失败的场景,如网络连接断开.断电等,尽管journaling日志功能也提供了数据恢复的功能,但journaling通常是针对单个节点来说的,只能保证单节点数据 ...
- Emberjs之ComputedProperty
计算属性,以下简称CP.简单概括来讲,就是在需要属性值的时候计算一个Function,并将Function返回的值保存在属性中,当第二次获取属性值时,如果发现属性并未改变则直接读取属性,如果属性依赖的 ...
- [后端人员耍前端系列]AngularJs篇:使用AngularJs打造一个简易权限系统
一.引言 上一篇博文已经向大家介绍了AngularJS核心的一些知识点,在这篇博文将介绍如何把AngularJs应用到实际项目中.本篇博文将使用AngularJS来打造一个简易的权限管理系统.下面不多 ...
- 004. Asp.Net Routing与MVC 之二: 请求如何激活Controller和Action
上篇讲到 请求到达 MvcRouteHandler ,并且透过 IRouteHandler.GetHttpHandler 获取到了真正的处理程序 MvcHandler 这次我们看看,MvcHandle ...
- 防止开发人员获取到敏感数据(SQL Server的数据加密简介)
背景 有时候,我们还真的会碰到这样的需求:防止开发人员获取到敏感数据.也许你觉得很简单,把开发和运营分开不就可以了吗?是的,如果公司有专门的运营团队的话,但对于很多小公司来说,几个人的开发团队就兼顾了 ...
- 相识Highcharts,几分钟玩转Highcharts
Highcharts是一个功能强大.开源.美观.图表丰富.兼容绝大多数浏览器的纯js图表库. 官网:http://www.hcharts.cn/ 我觉得对于刚接触一个东西的新手来说,有时候对一个东西真 ...