Stanford NLP 学习笔记2:文本处理基础(text processing)
I. 正则表达式(regular expression)
正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里)。
- ^(在字符前): 负选择,匹配除括号以外的字符。比如
[^A-W]匹配所有非大写字符;[^e^]匹配所有e和^以外的字符 - |:或者。比如a|b|c等价于
[a-c] - *:匹配大于等于0个符号前面的字符;+:匹配至少一个前面的字符;.:匹配所有单个字符;?:匹配0或1个前面的字符
- \:转义符:将特殊字符转化为简单字符。比如.匹配所有字符,.匹配.。
- 锚定符。^:匹配开头;$:匹配结尾。比如:^[a-z]匹配非小写字母开头的字符串;.$匹配所有.结尾的字符串。
匹配的错误类型:
- 一类错误(type I error):假阳性。匹配上不想匹配的字符串。比如只想匹配单词the却匹配上了other。
- 二类错误(type II error):假阴性。没有匹配上想要的字符串。比如像匹配单词the却没有匹配The。
基本上在NLP分析过程(甚至是所有机器学习问题)都是在处理这两类错误。减少一类错误(假阳性)意味着提高模型精度;减少二类错误(假阴性)意味着增加召回率。
总结:
正则表达式很强大,通配操作很方便,一般也是文本处理的第一步。在许多困难的任务中用到的机器学习分类器也会使用正则表达式作为特征。
II. 分词
文本标准化一般操作:1.断句。 2.分词。 3. 统一词格式(大小写,复数单数形式,所有格形式等)。
词根(lemma)和词形(wordform)

例子中的San Francisco可以拆开作为两个token,也可以整个作为一个token;而前后两个the只能算作一个type,而they和their也可以看成一个type
统计语料(corpus)时,一般默认用N代表tokens的数量;用V代表词汇库,即所有类型;|V|代表词汇库的大小。
Church & Gale(1990)提出|V| > O(N^1/2)
分词过程的一些问题:
- 缩写(有些包含标点符号)

- 其他语言
- 法语:

- 德语:复合名称之间没有空格

- 中文和日文:单词之间没有空格
中文分词:
中文由字符组成,每个字符一般时单音节和单字形的;平均每个单词包含2.4个字符。中文标准基线的分词算法是最大匹配算法(maximum matching algorithm)或贪婪算法(greedy algorithm)。

这里,由于中文的单词长度相对比较一致,因此这个方法效果比较好,但是这个方法对英语来说并不合适,因为英文单词长短差异很大且常长度不同的单词一般都混杂在一起使用。因此目前主流的分词算法都采用了概率模型。
III. 词标准化和词干提取
- 标准化
信息提取的时候,indexed text和query terms需要有相同的格式。比如U.S.A --> USA
上述处理可以通过删除词内.号实现。
非对称推广(asymmetric expansion):比如:

但是实际操作中为了降低时间复杂性等考虑一般还是会采用对称推广。 - 大小写折叠(Case Folding):将所有大写字符转换成小写字符
可能的例外:句中间的大写字符,比如General Motors;缩写单词的大写字符,比如Fed(Federal reserve bank) - 词形还原(lemmatization)
将词的变体转换为原型词根(寻找不同变体的共同词头)。比如:
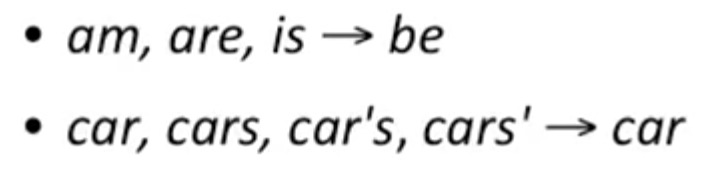
构词(morphology):词素(morpheme)是指构成词的最小的有语法意义单位。由词干(stem)和词缀(affix)组成。

其中方框内的就是词干,而圆圈内的就是词缀。 - 词干化(stemming)
在信息提取时将词转换成其词干形式,而词干化就是将词的词缀去除留下词干(这一过程时语言依赖的,不同语言的词干化规则不同)。比如:

最著名的词干分析器是Porter's algorithm:这是由一系列按顺序排列的词干化规则组成

IV. 分句
将文本分成按边界一个个单句。!和?是很清晰的句子边界标志,但是.号不是。.号可以作为句子边界,缩写标志(Inc.和Dr.等)以及浮点数(.2%和4.3等)。因此在判断.号是否为边界的时候可以采用包括决策树,正则表达式,SVM,logistic regression , neural network等分类器来进行判断。
由于决策树只需通过if-else进行判断,所以利用决策树作为分类器十分直观易懂。决策树的关键在于选取特征。比如提取.号相关的文本特征:

但是除非特征数很少,否则很难手动进行决策树的构建,因为对于大部分数字型特征都需要设定阈值。所以一般都是通过机器学习的方式从语料自动学习来生成结构。
传送门:https://www.youtube.com/watch?v=di0N3kXfGYg
Stanford NLP 学习笔记2:文本处理基础(text processing)的更多相关文章
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- Stanford NLP学习笔记1:课程介绍
Stanford NLP课程简介 1. NLP应用例子 问答系统: IBM Watson 信息提取(information extraction) 情感分析 机器翻译 2. NLP应用当前进展 很成熟 ...
- stanford NLP学习笔记3:最小编辑距离(Minimum Edit Distance)
I. 最小编辑距离的定义 最小编辑距离旨在定义两个字符串之间的相似度(word similarity).定义相似度可以用于拼写纠错,计算生物学上的序列比对,机器翻译,信息提取,语音识别等. 编辑距离就 ...
- Linux 学习笔记之超详细基础linux命令 Part 13
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 12---------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 4
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 3----------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 2
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 1----------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 1
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 说明:主要是在REHL Server 6操作系统下进行的测试 --字符界面虚拟终端与图形界面之间的切 方法:[ ...
- 【学习笔记】jQuery的基础学习
[学习笔记]jQuery的基础学习 新建 模板 小书匠 什么是jQuery对象? jQuery 对象就是通过jQuery包装DOM对象后产生的对象.jQuery 对象是 jQuery 独有的. 如果 ...
- 【学习笔记】JavaScript的基础学习
[学习笔记]JavaScript的基础学习 一 变量 1 变量命名规则 Camel 标记法 首字母是小写的,接下来的字母都以大写字符开头.例如: var myTestValue = 0, mySeco ...
随机推荐
- JDBC的作用及重要接口
JDBC是由一系列连接(Connection).SQL语句(Statement)和结果集(ResultSet)构成的,其主要作用概括起来有如下3个方面: 建立与数据库的连接. 向数据库发起 ...
- MINIX3
这个系列minix3是好早看的源码 现在都忘记的差不多了 觉得就此扔掉可惜了 今天把他全部放在博客上 1 是想和大家一起讨论下 2 是没事看看 能够加强对一个稳定性系统的理解 加厚
- EtherType
EtherType is a two-octet field in an Ethernet frame. It is used to indicate which protocol is encaps ...
- Hyper-V安装Oracle Linux6_4 Oracle db 12c并使用rman做异机恢复
本文记录在Windows Server 2012 R2上安装Oracle Enterprise Linux 6.4以及使用RMAN进行进行异机恢复的过程. Windows服务器增加Hyper-V功能 ...
- scrollView中可以自由滚动的listview
直接在scrollView中写listview等可滚动控件会出现子控件高度计算的问题,为了解决这个问题,找到的方案是重写listview中的onmeasure方法: @Override public ...
- 两个不同的list随机组合到一个List中。
今天组长给了一个绑定任务,业务需要把一男一女随机的老师绑定到考场. 测试例子入下: package com.test; import java.util.ArrayList; import java. ...
- 2015.10.18 do while练习
/*乘法表*/ #define COLMAX 10 #define ROWMAX 12 main() { int row,column,y; row=1; printf(" ...
- js判断类型方法
在JavaScript中,有5种基本数据类型和1种复杂数据类型,基本数据类型有:Undefined, Null,Boolean, Number和String:复杂数据类型是Object,Object中 ...
- IOS开发网络数据---- AFNetworking的使用
http网络库是集XML解析,Json解析,网络图片下载,plist解析,数据流请求操作,上传,下载,缓存等网络众多功能于一身的强大的类库.最新版本支持session,xctool单元测试.网络获取数 ...
- mysql 数据库基本概念
mysql 数据库基本概念 一.数据库的集中控制优点1.降低存储数据的冗余度2.更高的数据一致性3.存储的数据可以共享4.可以建立数据库所遵循的标准5.便于数据维护完整性6.能够实现数据的安全性 二. ...