深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG、Inception、Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型参数设置出错的话,其实模型也往往不能运行了。
所以,我们需要首先了解模型各层的含义,比如输出尺寸和可训练参数数量。理解后,大家在设计自己的网路模型时,就可以先在纸上画出网络流程图,设置各参数,计算输出尺寸和可训练参数数量,最后就可以照此进行编码实现了。
而在keras中,当我们构建模型或拿到一个成熟模型后,往往可以通过model.summary()来观察模型各层的信息。
本文将通过一个简单的例子来进行说明。本例以keras官网的一个简单模型VGG-like模型为基础,稍加改动代码如下:
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPool2D (train_data, train_labels), (test_data, test_labels) = keras.datasets.mnist.load_data()
train_data = train_data.reshape(-1, 28, 28, 1)
print("train data type:{}, shape:{}, dim:{}".format(type(train_data), train_data.shape, train_data.ndim))
# 第一组
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第二组
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第三组
model.add(Flatten())
model.add(Dense(units=256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=10, activation='softmax')) model.summary()
本例的数据来源于mnist,这是尺寸为28*28,通道数为1,也即只有黑白两色的图片。其中卷积层的参数含义为:
- filters:表示过滤器的数量,每一个过滤器都会与对应的输入层进行卷积操作;
- kernel_size:表示过滤器的尺寸,一般为奇数值,如1,3,5,这里设置为3*3大小;
- strides:表示步长,即每一次过滤器在图片上移动的步数;
- padding:表示是否对图片边缘填充像素,一般有两个值可选,一是默认的valid,表示不填充像素,卷积后图片尺寸会变小;另一种是same,填充像素,使得输出尺寸和输入尺寸保持一致。
如果选择valid,假设输入尺寸为n * n,过滤器的大小为f * f,步长为s,则其输出图片的尺寸公式为:[(n - f)/s + 1] * [(n -f)/s + 1)],若计算结果不为整数,则向下取整;
如果选择same,假设输入尺寸为n * n,过滤器的大小为f * f,要填充的边缘像素宽度为p,则计算p的公式为:n + 2p -f +1 = n, 最后得 p = (f -1) /2。
运行上述例子,可以看到如下结果:
train data type:<class 'numpy.ndarray'>, shape:(60000, 28, 28, 1), dim:4
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 256) 262400
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 329,962
Trainable params: 329,962
Non-trainable params: 0
让我们解读下,首先mnist为输入数据,尺寸大小为 (60000, 28, 28, 1), 这是典型的NHWC结构,即(图片数量,宽度,高度,通道数);
其次我们需要关注表格中的"output shape"输出尺寸,其遵循mnist一样的结构,只不过第一位往往是None,表示图片数待定,后三位则按照上述规则进行计算;
最后关注的是"param"可训练参数数量,不同的模型层计算方法不一样:
- 对于卷积层而言,假设过滤器尺寸为f * f, 过滤器数量为n, 若开启了bias,则bias数固定为1,输入图片的通道数为c,则param计算公式= (f * f * c + 1) * n;
- 对于池化层、flatten、dropout操作而言,是不需要训练参数的,所以param为0;
- 对于全连接层而言,假设输入的列向量大小为i,输出的列向量大小为o,若开启bias,则param计算公式为=i * o + o
按照代码中划分的三组模型层次,其输出尺寸和可训练参数数量的计算方法可如下图所示:
第一组:
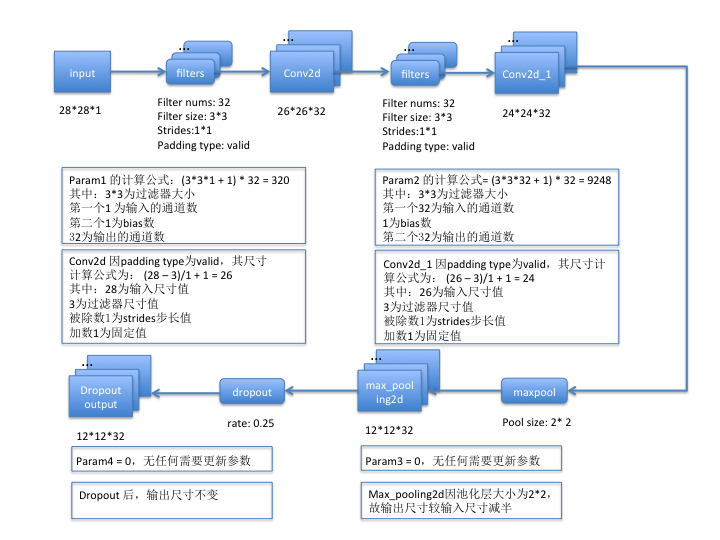
第二组:
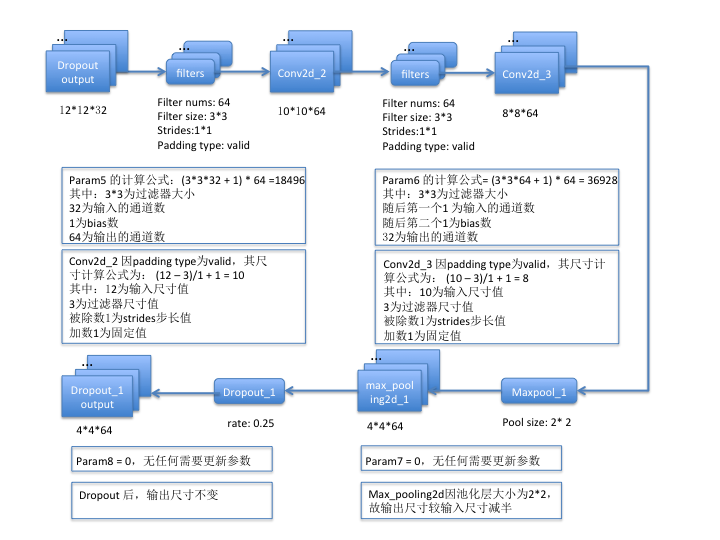
第三组:
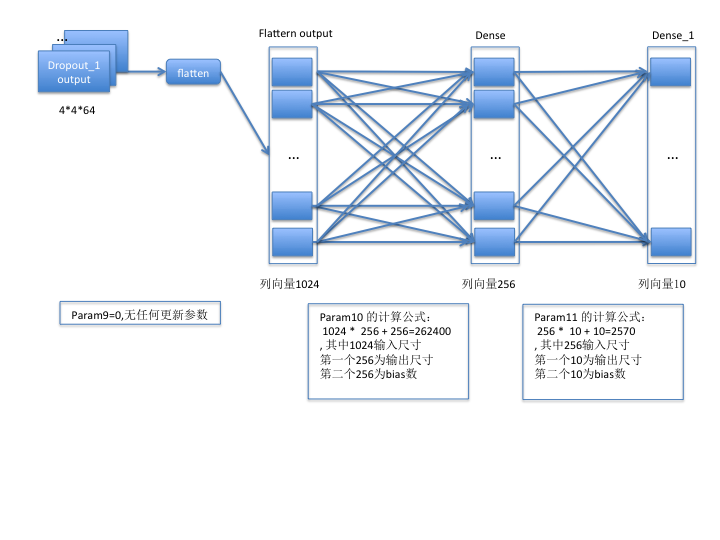
至此,模型各层的含义和相关计算方法已介绍完毕,希望此文能帮助大家更好地理解模型的构成和相关计算。
深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)的更多相关文章
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- pyhton pandas数据分析基础入门(一文看懂pandas)
//2019.07.17 pyhton中pandas数据分析基础入门(一文看懂pandas), 教你迅速入门pandas数据分析模块(后面附有入门完整代码,可以直接拷贝运行,含有详细的代码注释,可以轻 ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段.BN能带来如下优点: 加速训练过程: 可以使用较大的学习率: 允许在深层网络中使用sigmoid这 ...
- 深度学习基础系列(二)| 常见的Top-1和Top-5有什么区别?
在深度学习过程中,会经常看见各成熟网络模型在ImageNet上的Top-1准确率和Top-5准确率的介绍,如下图所示: 那Top-1 Accuracy和Top-5 Accuracy是指什么呢?区别在哪 ...
- 深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid.tanh和relu三种非线性函数,其数学表达式分别为: sigmoid: y = 1/(1 + e-x) tanh: y = (ex - e-x)/(ex + e-x) ...
随机推荐
- Spring整合JMS(一)——基于ActiveMQ实现 (转)
*注:别人那复制来的 1.1 JMS简介 JMS的全称是Java Message Service,即Java消 息服务.它主要用于在生产者和消费者之间进行消息传递,生产者负责产生消息,而消费者 ...
- HDU 4496 并查集 逆向思维
给你n个点m条边,保证已经是个连通图,问每次按顺序去掉给定的一条边,当前的连通块数量. 与其正过来思考当前这边会不会是桥,不如倒过来在n个点即n个连通块下建图,检查其连通性,就能知道个数了 /** @ ...
- css纯数字或字母换行
#div { word-wrap:break-word; word-break:break-all; }
- Linux命令学习-图形化界面命令开关闭
su root password 1, 关闭图形界面: init 3 关闭图形界面(XServer服务也会关闭) 开启图形界面: init 5 或 startx 开机时,不进入 X Window: v ...
- MYSQL5.6学习——mysqldump备份与恢复
MYSQL备份 冷备份:停止服务进行备份,即停止数据库的写入 热备份:不停止服务进行备份(在线) l mysql的MyIsam引擎只支持冷备份,InnoDB支持热备份,原因: InnoDB引擎是事务 ...
- 【BZOJ】3524: [Poi2014]Couriers
[算法]主席树 [题解]例题,记录和,数字出现超过一半就递归查找. 主席树见[算法]数据结构 #include<cstdio> #include<algorithm> #inc ...
- 【CodeForces】790 C. Bear and Company 动态规划
[题目]C. Bear and Company [题意]给定大写字母字符串,交换相邻字符代价为1,求最小代价使得字符串不含"VK"子串.n<=75. [算法]动态规划 [题解 ...
- 在eclipse安装mybatis的插件
1.在help中打开 2.搜索mybatipse 3:功能简介 1:要查找某一个方法 在dao接口中某一个方法中 按住 Ctrl键 鼠标指到方法名称上 选择open xml 就会自动跳转 ...
- Oracle笔记之约束
约束用于保证数据库中某些数据的完整性,给某一列添加一个约束可以保证不满足约束的数据是绝对不会被接受的. 约束主要有那么五种类型:非空约束.唯一约束.主键约束.外键约束.校验约束. 使用如下命令检索某个 ...
- Anaconda3的安装和汉化
下载页面 : https://www.anaconda.com/download 直接下载(Windows) : Anaconda3-5.0.0-Windows-x86_64.exe | Anacon ...