zpar使用方法之Chinese Word Segmentation
第一步在这里:
http://people.sutd.edu.sg/~yue_zhang/doc/doc/qs.html
你可以找到这句话,

所以在命令行中分别敲入
make zpar
make zpar.zh(中文)
make zpar.en(英文)
这时会生成一个dist文件夹 在里面你可以找到(如果做了英文的 还会有一个zpar.en)

之后进http://people.sutd.edu.sg/~yue_zhang/doc/doc/segmentor.html
这里做的是分词
第二步如何编译:

如何编译:敲入make segmentor
你将在dist目录下看到生成一个文件夹segmentor
在这里会有
这两个文件 train是用来训练模型的 segmentor是用来用训练好的模型做分词的
第三步那么如何训练模型呢?
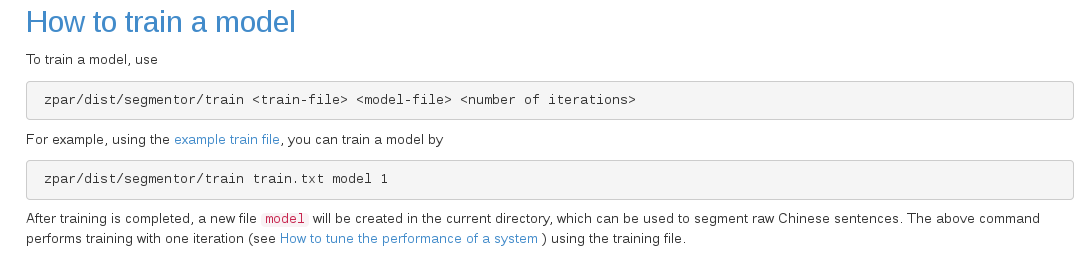
由于train 和segmentor是两个可执行文件 所以要进入到所生成他们的目录下给定好输入文本的位置 生成模型的位置以及名称 和迭代次数

这里model就是所生成模型的名称,当然也可以起别的名字,这不是一个关键字。后面的1就是迭代次数
这里的train.txt好像要utf-8编码。。。反正我直接从 下载的文本。
下载的文本。
训练结束你可以找到

例子中没给路径就应该是在zpar底下
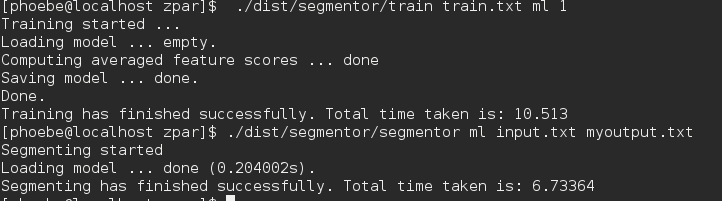
第四步如何分词:

敲入:

这里的model就是你训练出来的模型,如果你不是放在zpar下记得写出路径
太罗嗦了 就是记得把他们的路径写对
输入的文本也可以从an example input下载
这时你就可以找到你的output.txt了
应该是分好词的
第五步评估;
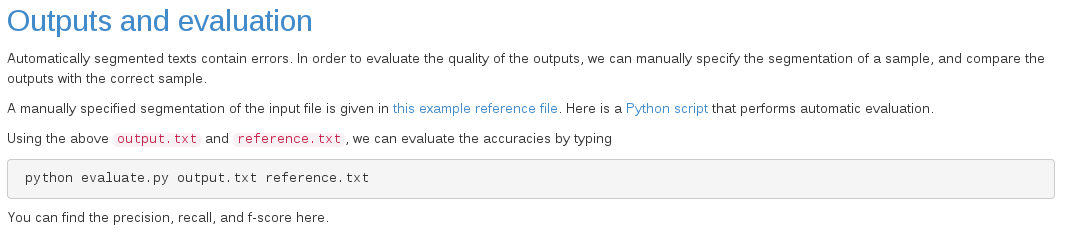
记得去下载evaluate.py这个脚本还有reference.txt
然后执行这个脚本
然后你能看到准确率 召回率 和F-score
F-score其实很简单
两个最常见的衡量指标是“准确率(precision)”(你给出的结果有多少是正确的)和“召回率(recall)”(正确的结果有多少被你给出了)
这
两个通常是此消彼长的(trade
off),很难兼得。很多时候用参数来控制,通过修改参数则能得出一个准确率和召回率的曲线(ROC),这条曲线与x和y轴围成的面积就是AUC(ROC
Area)。AUC可以综合衡量一个预测模型的好坏,这一个指标综合了precision和recall两个指标。
但AUC计算很麻烦,有人用简单的F-score来代替。F-score计算方法很简单:
F-score=(2*precision*recall)/(precision+recall)
即使不是算数平均,也不是几何平均。可以理解为几何平均的平方除以算术平均。
第六步写脚本
终于到了最后一步了。。。你去这个目录下看test.sh你会发现什么???自己去看吧。要是运行不出来这个脚本就发动你的智慧稍微改动一下。相信你能运行出来的
zpar使用方法之Chinese Word Segmentation的更多相关文章
- 长短时间记忆的中文分词 (LSTM for Chinese Word Segmentation)
翻译学长的一片论文:Long Short-Term Memory Neural Networks for Chinese Word Segmentation 传统的neural Model for C ...
- Solution for automatic update of Chinese word segmentation full-text index in NEO4J
Solution for automatic update of Chinese word segmentation full-text index in NEO4J 1. Sample data 2 ...
- onvif规范的实现:onvif开发常用调试方法 和常见的segmentation fault错误
在前几篇中,虽然已经实现了rtsp视频流的对接,但是还要做的工作还非常多,onvif本来就是一个覆盖面非常广的一个协议,每一个功能都要填充大量的函数.而且稍不注意就会出现segmentation fa ...
- Chinese word segment based on character representation learning 论文笔记
论文名和编号 摘要/引言 相关背景和工作 论文方法/模型 实验(数据集)及 分析(一些具体数据) 未来工作/不足 是否有源码 问题 原因 解决思路 优势 基于表示学习的中文分词 编号:1001-908 ...
- 论文阅读及复现 | Effective Neural Solution for Multi-Criteria Word Segmentation
主要思想 这篇文章主要是利用多个标准进行中文分词,和之前复旦的那篇文章比,它的方法更简洁,不需要复杂的结构,但比之前的方法更有效. 方法 堆叠的LSTM,最上层是CRF. 最底层是字符集的Bi-LST ...
- ANSJ中文分词使用方法
一.前言 之前做solr索引的时候就使用了ANSJ进行中文分词,用着挺好,然而当时没有写博客记录的习惯.最近又尝试了好几种JAVA下的中文分词库,个人感觉还是ANSJ好用,在这里简单总结之. 二.什么 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- ES-自然语言处理之中文分词器
前言 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块.不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性.句法树 ...
- nlp总结
中科院nlpir和海量分词(http://www.hylanda.com/)是收费的. hanlp:推荐基于CRF的模型的实现~~要看语料,很多常用词会被分错,所以需要词库支撑.目前最友好的开源工具包 ...
随机推荐
- Wow! Such Doge!---hdu4847(字符串水题)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4847 题意就是求给出的文章中共有多少个doge,不区分大小写直接用strstr做就可以了: #incl ...
- 全面介绍Windows内存管理机制及C++内存分配实例(四):内存映射文件
本文背景: 在编程中,很多Windows或C++的内存函数不知道有什么区别,更别谈有效使用:根本的原因是,没有清楚的理解操作系统的内存管理机制,本文企图通过简单的总结描述,结合实例来阐明这个机制. 本 ...
- oracle入门(6)——PL/SQL常用语法
[本文介绍] 本文不是”语法大全“,只是记录下作项目里自己常用的一些语法.方便查询. [语法] [输出] (1)输出语法 DBMS_OUTPUT.PUT_LINE( ) [定义] (1)定义变 ...
- PAT 1091 Acute Stroke [难][bfs]
1091 Acute Stroke (30 分) One important factor to identify acute stroke (急性脑卒中) is the volume of the ...
- c#在线手册汇总
1. c#中文手册(脚本之家) http://shouce.jb51.net/net/
- Python(异常处理)
一 错误和异常 程序中难免出现错误,而错误分成两种 1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正) 2.逻辑错误(逻辑错误) 什么是异常 异常就是程序运行时发 ...
- Godaddy域名因为whois信息虚假被暂时关闭
如果你收到来自 Godadddy 通过 invalidwhois@godaddy.com 发出的标题为如下内容的邮件: [Incident ID: xxxx] xxxx - DS Invalid Wh ...
- python数据描述符
Python的描述符是接触到Python核心编程中一个比较难以理解的内容,自己在学习的过程中也遇到过很多的疑惑,通过google和阅读源码,现将自己的理解和心得记录下来,也为正在为了该问题苦恼的朋友提 ...
- 来自IOS开发工程师的零基础自学HTML5经验分享
移动互联网的火爆,而Html具有跨平台.开发快的优势,越来越受到开发者的青睐.感谢IOS开发工程师“小木___Boy”’带来的HTML5学习经验分享. 一.学习途径 1.很多视频网站 比如慕课.和极客 ...
- hdu3518 Boring counting
地址:http://acm.split.hdu.edu.cn/showproblem.php?pid=3518 题目: Boring counting Time Limit: 2000/1000 MS ...