scrapy爬虫事件以及数据保存为txt,json,mysql
今天要爬取的网页是虎嗅网
我们将完成如下几个步骤:
- 创建一个新的Scrapy工程
- 定义你所需要要抽取的Item对象
- 编写一个spider来爬取某个网站并提取出所有的Item对象
- 编写一个Item Pipline来存储提取出来的Item对象
创建Scrapy工程
在任何目录下执行如下命令
scrapy startproject coolscrapy
cd coolscrapy
scrapy genspider huxiu huxiu.com
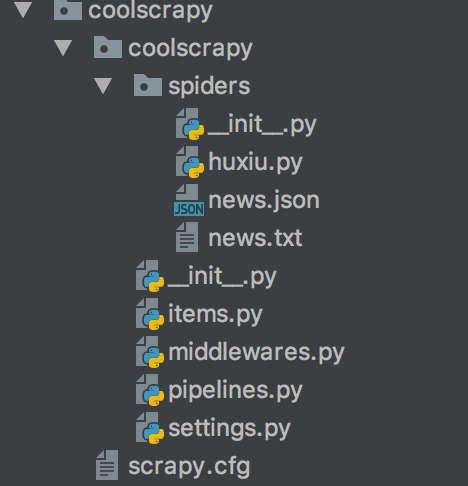
我们看看创建的工程目录结构:(news.json,news.txt是最后结果保存的)
定义Item
我们通过创建一个scrapy.Item类,并定义它的类型为scrapy.Field的属性, 我们准备将虎嗅网新闻列表的名称、链接地址和摘要爬取下来。
import scrapy class CoolscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #链接
desc = scrapy.Field() #简述
posttime = scrapy.Field() #发布时间
编写Spider
蜘蛛就是你定义的一些类,Scrapy使用它们来从一个domain(或domain组)爬取信息。 在蜘蛛类中定义了一个初始化的URL下载列表,以及怎样跟踪链接,如何解析页面内容来提取Item。
定义一个Spider,只需继承scrapy.Spider类并定于一些属性:
- name: Spider名称,必须是唯一的
- start_urls: 初始化下载链接URL
- parse(): 用来解析下载后的Response对象,该对象也是这个方法的唯一参数。 它负责解析返回页面数据并提取出相应的Item(返回Item对象),还有其他合法的链接URL(返回Request对象)。
我们打开在coolscrapy/spiders文件夹下面的huxiu.py,内容如下:
# -*- coding: utf-8 -*-
import scrapy
from coolscrapy.items import CoolscrapyItem class HuxiuSpider(scrapy.Spider):
name = "huxiu"
allowed_domains = ["huxiu.com"]
start_urls = ['http://huxiu.com/index.php'] def parse(self, response):
items = []
data = response.xpath('//div[@class="mod-info-flow"]/div/div[@class="mob-ctt"]')
for sel in data:
item = CoolscrapyItem()
if len(sel.xpath('./h2/a/text()').extract()) <= 0:
item['title'] = 'No title'
else:
item['title'] = sel.xpath('./h2/a/text()').extract()[0]
if len(sel.xpath('./h2/a/@href').extract()) <= 0:
item['link'] = 'link在哪里!!!!!!!!'
else:
item['link'] = sel.xpath('./h2/a/@href').extract()[0]
url = response.urljoin(item['link'])
if len(sel.xpath('div[@class="mob-sub"]/text()').extract()) <= 0:
item['desc'] = '啥也没有哦...'
else:
item['desc'] = sel.xpath('div[@class="mob-sub"]/text()').extract()[0]
#item['posttime'] = sel.xpath('./div[@class="mob-author"]/span/@text()').extract()[0]
print(item['title'], item['link'], item['desc'])
items.append(item)
return items
现在可以在终端运行了,是可以打印每个新闻信息的。
scrapy crawl huxiu
如果一切正常,应该可以打印出每一个新闻
处理链接
如果想继续跟踪每个新闻链接进去,看看它的详细内容的话,那么可以在parse()方法中返回一个Request对象, 然后注册一个回调函数来解析新闻详情。
下面继续编写huxiu.py
# -*- coding: utf-8 -*-
import scrapy
from coolscrapy.items import CoolscrapyItem class HuxiuSpider(scrapy.Spider):
name = "huxiu"
allowed_domains = ["huxiu.com"]
start_urls = ['http://huxiu.com/index.php'] def parse(self, response):
#items = []
data = response.xpath('//div[@class="mod-info-flow"]/div/div[@class="mob-ctt"]')
for sel in data:
item = CoolscrapyItem()
if len(sel.xpath('./h2/a/text()').extract()) <= 0:
item['title'] = 'No title'
else:
item['title'] = sel.xpath('./h2/a/text()').extract()[0]
if len(sel.xpath('./h2/a/@href').extract()) <= 0:
item['link'] = 'link在哪里!!!!!!!!'
else:
item['link'] = sel.xpath('./h2/a/@href').extract()[0]
url = response.urljoin(item['link'])
if len(sel.xpath('div[@class="mob-sub"]/text()').extract()) <= 0:
item['desc'] = '啥也没有哦...'
else:
item['desc'] = sel.xpath('div[@class="mob-sub"]/text()').extract()[0]
#item['posttime'] = sel.xpath('./div[@class="mob-author"]/span/@text()').extract()[0]
print(item['title'], item['link'], item['desc'])
#items.append(item)
#return items
yield scrapy.Request(url,callback=self.parse_article) def parse_article(self,response):
detail = response.xpath('//div[@class="article-wrap"]')
item = CoolscrapyItem()
item['title'] = detail.xpath('./h1/text()')[0].extract().strip()
item['link'] = response.url
item['posttime'] = detail.xpath('./div/div[@class="column-link-box"]/span[1]/text()')[0].extract()
print(item['title'],item['link'],item['posttime'])
yield item
现在parse只提取感兴趣的链接,然后将链接内容解析交给另外的方法去处理了。 你可以基于这个构建更加复杂的爬虫程序了。
导出抓取数据
最简单的保存抓取数据的方式是使用json格式的文件保存在本地,像下面这样运行:
scrapey crawl huxiu -o items.json
一般构建爬虫系统,建议自己编写Item Pipeline
数据保存为TXT/JSON/MySql
1.数据保存为TXT
打开Pipeline.py
import codecs
import os
import json
import pymysql class CoolscrapyPipeline(object):#需要在setting.py里设置'coolscrapy.piplines.CoolscrapyPipeline':300
def process_item(self, item, spider):
# 获取当前工作目录
base_dir = os.getcwd()
fiename = base_dir + '/news.txt'
# 从内存以追加的方式打开文件,并写入对应的数据
with open(fiename, 'a') as f:
f.write(item['title'] + '\n')
f.write(item['link'] + '\n')
f.write(item['posttime'] + '\n\n')
return item
2.保存为json格式
在Pipeline.py里面新建一个类
#以下两种写法保存json格式,需要在settings里面设置'coolscrapy.pipelines.JsonPipeline': 200 class JsonPipeline(object):
def __init__(self):
self.file = codecs.open('logs.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close() class JsonPipeline(object):
def process_item(self, item, spider):
base_dir = os.getcwd()
filename = base_dir + '/news.json'
# 打开json文件,向里面以dumps的方式吸入数据
# 注意需要有一个参数ensure_ascii=False ,不然数据会直接为utf编码的方式存入比如
# :“/xe15”
with codecs.open(filename, 'a') as f:
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(line)
return item
上面是两种写法,都是一样的
3.保存到mysql
保存到数据库需要建立表格newsDB,详情请参考http://www.cnblogs.com/freeman818/p/7223161.html
在Pipeline.py里面新建一个类
class mysqlPipeline(object):
def process_item(self,item,spider):
'''
将爬取的信息保存到mysql
'''
# 将item里的数据拿出来
title = item['title']
link = item['link']
posttime = item['posttime'] # 和本地的newsDB数据库建立连接
db = pymysql.connect(
host='localhost', # 连接的是本地数据库
user='root', # 自己的mysql用户名
passwd='', # 自己的密码
db='newsDB', # 数据库的名字
charset='utf8mb4', # 默认的编码方式:
cursorclass=pymysql.cursors.DictCursor)
try:
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO NEWS(title,link,posttime) \
VALUES ('%s', '%s', '%s')" % (title,link,posttime)
# 执行SQL语句
cursor.execute(sql)
# 提交修改
db.commit()
finally:
# 关闭连接
db.close()
return item
编写Settings.py
我们需要在Settings.py将我们写好的PIPELINE添加进去,
scrapy才能够跑起来
这里只需要增加一个dict格式的ITEM_PIPELINES,
数字value可以自定义,数字越小的优先处理
ITEM_PIPELINES={'coolscrapy.pipelines.CoolscrapyPipeline':300,
'coolscrapy.pipelines.JsonPipeline': 200,
'coolscrapy.pipelines.mysqlPipeline': 100,
}
下面让程序跑起来
scrape crawl huxiu
看看结果:
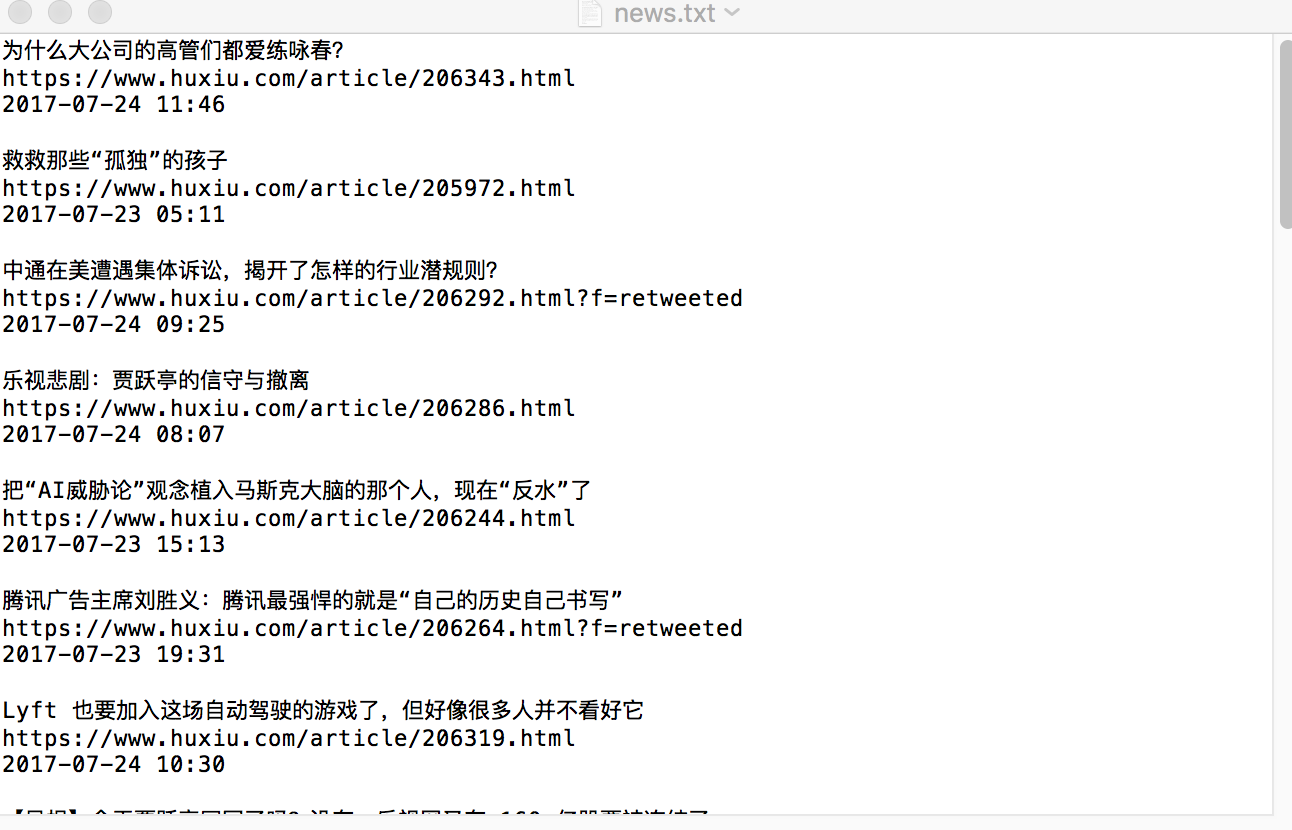
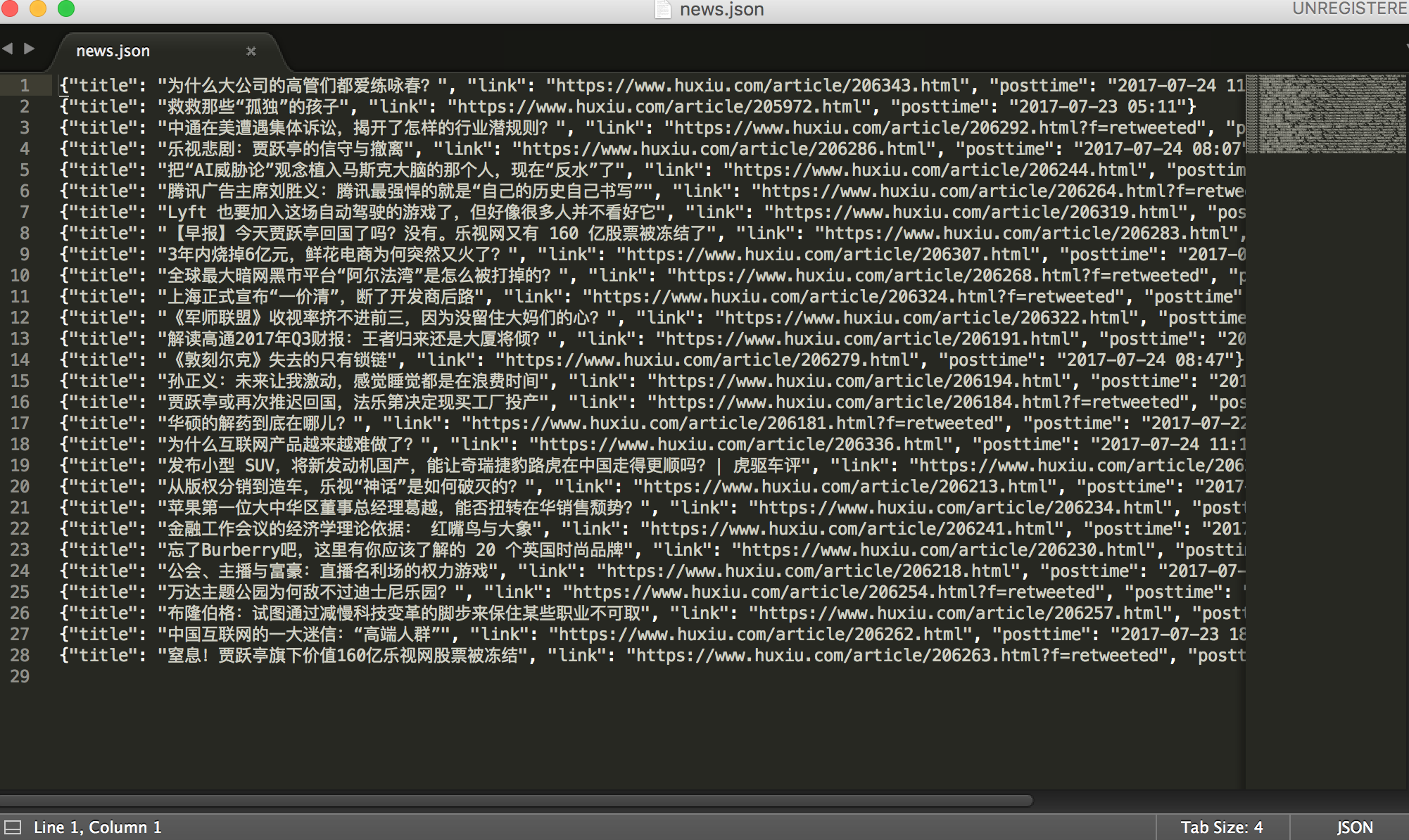
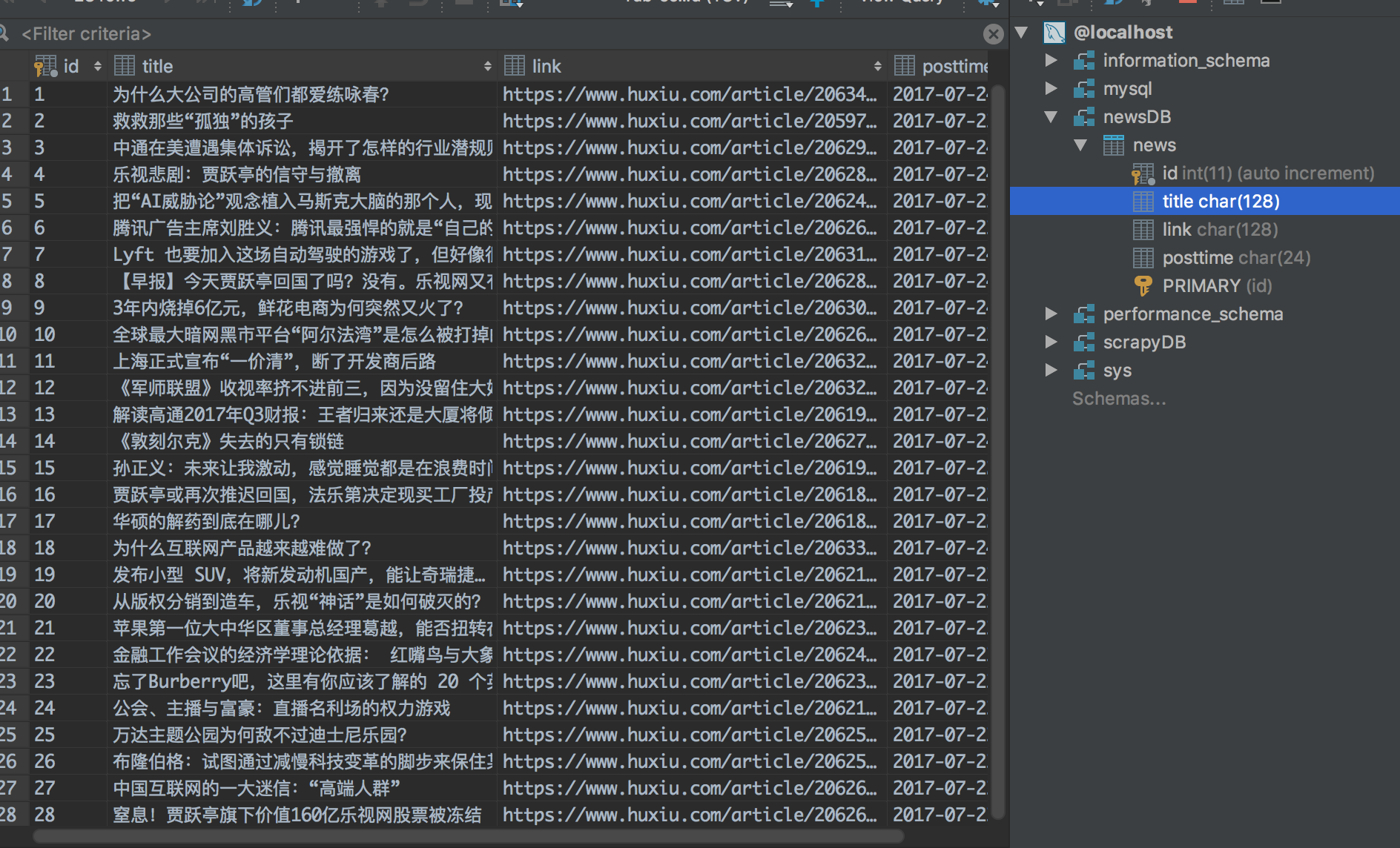
好了,这次就到这里。代码要自己敲才会慢慢熟练。
scrapy爬虫事件以及数据保存为txt,json,mysql的更多相关文章
- python3+Scrapy爬虫使用pipeline数据保存到文本和数据库,数据少或者数据重复问题
爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据或者数据少问题.那为什么会造成这种结果呢? 其原因是由于Spider的速率比较快,而scapy操作数据库操作比较慢,导致pipelin ...
- python爬虫:将数据保存到本地
一.python语句存储 1.with open()语句 with open(name,mode,encoding) as file: file.write() name:包含文件名称的字符串; mo ...
- Python将数据保存为txt文件的方法
f = open('name.txt',mode='w') #打开文件,若文件不存在系统自动创建. #参数name 文件名,mode 模式. #w 只能操作写入 r 只能读取 a 向文件追加 #w+ ...
- spark sql中将数据保存成parquet,json格式
val df = sqlContext.load("/opt/modules/spark1.3.1/examples/src/main/resources/people.json" ...
- scrapy爬虫保存数据
1.数据保存为TXT 打开Pipeline.py import codecs import os import json import pymysql class CoolscrapyPipeline ...
- 图像特征的提取(gaussian,gabor,frangi,hessian,Morphology...)及将图片保存为txt文件
# -*- coding: utf-8 -*- #2018-2-19 14:30:30#Author:Fourmi_gsj import cv2 import numpy as np import p ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 二十一 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 # -*- coding: utf-8 -*- # Define your ite ...
- scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据 爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中. items.py class DoubanspiderItem( ...
随机推荐
- Hibernate学习6—Hibernate 映射类型
第一节:基本类型映射 com.cy.model.Book.java: package com.cy.model; import java.sql.Blob; import java.util.Date ...
- Java-Runoob-高级教程:Java 泛型
ylbtech-Java-Runoob-高级教程:Java 泛型 1.返回顶部 1. Java 泛型 Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检 ...
- centos开机提示CPU无法识别的问题
centos版本和对应cpu兼容性,官方网址: https://access.redhat.com/support/policy/intel Red Hat Enterprise Linux Vers ...
- ALSA声卡11_从零编写之调试——学习笔记
1.调试 (1)把程序拷贝到服务器上进行编译 (2)把程序放到内核上面去 重新配置内核,吧原来的声卡驱动程序去掉 a. 修改语法错误 11th_myalsa b. 配置内核去掉原来的声卡驱动 -> ...
- 嵌入式Linux驱动和固件有何区别?供应商是如何用固件压缩成本的?
作为一个驱动开发者, 你可能发现你面对一个设备必须在它能支持工作前下载固件到它里面. 硬件市场的许多地方的竞争是如此得强烈, 以至于甚至一点用作设备控制固件的 EEPROM 的成本制造商都不愿意花费. ...
- 5月12日上课笔记-js 弹出框、函数、程序调试、基本事件、浏览器对象模型
一.弹出框 a.提示框 alert(); b.输入框 prompt(); c.确认框 confirm(); var flag= confirm("确认删除吗?"); 二.js程序调 ...
- video2gift环境安装(Theano等)
pip install Theano http://deeplearning.net/software/theano/install_centos6.html pip install moviepy ...
- bat执行sqlplus语句,省去@xx.sql过程
bat文件中执行写sqlplus连接,再@调用自己,sql登录成功后,会忽略掉第一行sqlplus xxx,转而执行下方的sql语句 --------------------------------- ...
- URL传参时中文参数乱码的解决方法
URL传参时,中文参数乱码的解决: 今天在工作中遇到了这样的一个问题,在页面之间跳转时,我将中文的参数放入到url中,使用location进行跳转传参,但是发现接收到的参数值是乱码.我的代码是这样写的 ...
- Console2支援中文顯示的正式設定法
1.用regedit找到HKEY_CURRENT_USER\Console,把底下的Console2 command window機碼給砍了.2.Console2的View功能表中,有個Console ...