016:Explain
一. Explain
1.explain说明
explain是解释SQL语句的执行计划,即显示该SQL语句怎么执行的
- 使用
explain的时候,也可以使用desc
- 使用
5.6 版本支持
DML语句进行explain解释5.6 版本开始支持
JSON格式的输出
注意:EXPLAIN查看的是执行计划,做SQL解析,不会去真的执行;且到5.7以后子查询也不会去执行。
(gcdb@localhost) 14:30:50 [mytest]> explain SELECT
-> t.TABLE_SCHEMA,
-> t.TABLE_NAME,
-> s.INDEX_NAME,
-> CARDINALITY,
-> TABLE_ROWS,
-> CARDINALITY / TABLE_ROWS AS SELECTIVITY
-> FROM
-> information_schema.TABLES t,
-> (SELECT
-> table_schema, table_name, index_name, cardinality
-> FROM
-> information_schema.STATISTICS
-> WHERE
-> (table_schema , table_name, index_name, seq_in_index) IN (SELECT
-> table_schema, table_name, index_name, MAX(seq_in_index)
-> FROM
-> information_schema.STATISTICS
-> GROUP BY table_schema , table_name , index_name)) s
-> WHERE
-> t.table_schema = s.table_schema
-> AND t.table_schema = 'employees'
-> AND t.table_name = s.table_name
-> ORDER BY SELECTIVITY;
+----+--------------------+------------+------------+------+---------------+--------------+---------+------+------+----------+--------------------------------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+------+---------------+--------------+---------+------+------+----------+--------------------------------------------------------------------------------------------+
| 1 | PRIMARY | t | NULL | ALL | NULL | TABLE_SCHEMA | NULL | NULL | NULL | NULL | Using where; Open_full_table; Scanned 1 database; Using temporary; Using filesort |
| 1 | PRIMARY | STATISTICS | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using where; Open_full_table; Scanned all databases; Using join buffer (Block Nested Loop) |
| 3 | DEPENDENT SUBQUERY | STATISTICS | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Open_frm_only; Scanned all databases; Using temporary; Using filesort |
+----+--------------------+------------+------------+------+---------------+--------------+---------+------+------+----------+--------------------------------------------------------------------------------------------+
3 rows in set, 1 warning (0.00 sec) -- 有warnings,这里相当于提供一个信息返回
(gcdb@localhost) 14:31:37 [mytest]> show warnings \G; -- 即将被弃用
*************************** 1. row ***************************
Level: Warning
Code: 1681
Message: 'EXTENDED' is deprecated and will be removed in a future release.
*************************** 2. row *************************** -- 显示真正的执行语句
Level: Note
Code: 1003
Message: /* select#1 */ select `t`.`TABLE_SCHEMA` AS `TABLE_SCHEMA`,`t`.`TABLE_NAME` AS `TABLE_NAME`,`information_schema`.`STATISTICS`.`INDEX_NAME` AS `index_name`,`information_schema`.`STATISTICS`.`CARDINALITY` AS `cardinality`,`t`.`TABLE_ROWS` AS `TABLE_ROWS`,(`information_schema`.`STATISTICS`.`CARDINALITY` / `t`.`TABLE_ROWS`) AS `SELECTIVITY` from `information_schema`.`TABLES` `t` join `information_schema`.`STATISTICS` where ((`information_schema`.`STATISTICS`.`TABLE_NAME` = `t`.`TABLE_NAME`) and (`information_schema`.`STATISTICS`.`TABLE_SCHEMA` = `t`.`TABLE_SCHEMA`) and (`t`.`TABLE_SCHEMA` = 'employees') and <in_optimizer>((`information_schema`.`STATISTICS`.`TABLE_SCHEMA`,`information_schema`.`STATISTICS`.`TABLE_NAME`,`information_schema`.`STATISTICS`.`INDEX_NAME`,`information_schema`.`STATISTICS`.`SEQ_IN_INDEX`),<exists>(/* select#3 */ select 1,1,1,1 from `information_schema`.`STATISTICS` group by `information_schema`.`STATISTICS`.`TABLE_SCHEMA`,`information_schema`.`STATISTICS`.`TABLE_NAME`,`information_schema`.`STATISTICS`.`INDEX_NAME` having (((<cache>(`information_schema`.`STATISTICS`.`TABLE_SCHEMA`) = `information_schema`.`STATISTICS`.`TABLE_SCHEMA`) or <cache>(isnull(`information_schema`.`STATISTICS`.`TABLE_SCHEMA`))) and ((<cache>(`information_schema`.`STATISTICS`.`TABLE_NAME`) = `information_schema`.`STATISTICS`.`TABLE_NAME`) or <cache>(isnull(`information_schema`.`STATISTICS`.`TABLE_NAME`))) and ((<cache>(`information_schema`.`STATISTICS`.`INDEX_NAME`) = `information_schema`.`STATISTICS`.`INDEX_NAME`) or <cache>(isnull(`information_schema`.`STATISTICS`.`INDEX_NAME`))) and ((<cache>(`information_schema`.`STATISTICS`.`SEQ_IN_INDEX`) = max(`information_schema`.`STATISTICS`.`SEQ_IN_INDEX`)) or isnull(max(`information_schema`.`STATISTICS`.`SEQ_IN_INDEX`))) and <is_not_null_test>(`information_schema`.`STATISTICS`.`TABLE_SCHEMA`) and <is_not_null_test>(`information_schema`.`STATISTICS`.`TABLE_NAME`) and <is_not_null_test>(`information_schema`.`STATISTICS`.`INDEX_NAME`) and <is_not_null_test>(max(`information_schema`.`STATISTICS`.`SEQ_IN_INDEX`)))))) order by `SELECTIVITY`
2 rows in set (0.00 sec)
- 参数FORMAT
- 使用
format=json不仅仅是为了格式化输出效果,还有其他有用的显示信息。 - 且当5.6版本后,使用
MySQL Workbench,可以使用visual Explain方式显示详细的图示信息。
- 使用
(gcdb@localhost) 16:24:02 [information_schema]> explain format=json SELECT table_schema, table_name, index_name, MAX(seq_in_index) FROM information_schema.STATISTICS GROUP BY table_schema , table_name , index_name \G;
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "12.50"
},
"grouping_operation": {
"using_temporary_table": true,
"using_filesort": true,
"cost_info": {
"sort_cost": "2.00"
},
"table": {
"table_name": "STATISTICS",
"access_type": "ALL",
"open_frm_only": true,
"scanned_databases": "all",
"used_columns": [
"TABLE_CATALOG",
"TABLE_SCHEMA",
"TABLE_NAME",
"NON_UNIQUE",
"INDEX_SCHEMA",
"INDEX_NAME",
"SEQ_IN_INDEX",
"COLUMN_NAME",
"COLLATION",
"CARDINALITY",
"SUB_PART",
"PACKED",
"NULLABLE",
"INDEX_TYPE",
"COMMENT",
"INDEX_COMMENT"
]
}
}
}
}
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
(gcdb@localhost) 16:25:29 [information_schema]>
2.Explain输出介绍
| 列 | 含义 |
|---|---|
| id | 执行计划的id标志 |
| select_type | SELECT的类型 |
| table | 输出记录的表 |
| partitions | 符合的分区,[PARTITIONS] |
| type | JOIN的类型 |
| possible_keys | 优化器可能使用到的索引 |
| key | 优化器实际选择的索引 |
| key_len | 使用索引的字节长度 |
| ref | 进行比较的索引列 |
| rows | 优化器预估的记录数量 |
| filtered | 根据条件过滤得到的记录的百分比[EXTENDED] |
| extra | 额外的显示选项 |
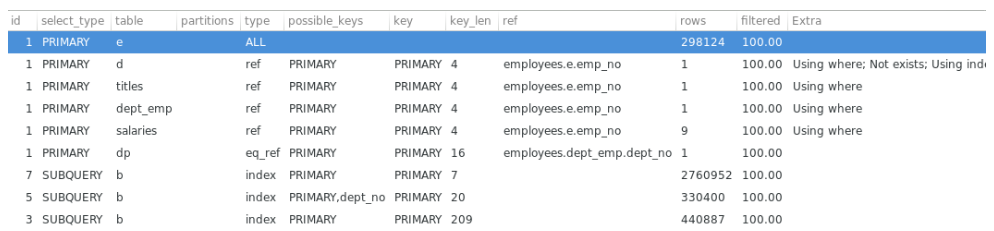
2.1. id
是指包含一组数字,表示查询中执行select子句或操作表的顺序。
口诀:
id相等的从上往下看,id不等的从下往上看。但是在某些场合也不一定适用
2.2. select_type
| select_type | 含义 |
|---|---|
| SIMPLE | 简单SELECT(不使用UNION或子查询等) |
| PRIMARY | 最外层的select |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,依赖于外面的查询 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个SELECT |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,依赖于外面的查询 |
| DERIVED | 派生表的SELECT(FROM子句的子查询) |
| MATERIALIZED | 物化子查询 |
| UNCACHEABLE SUBQUERY | 不会被缓存的并且对于外部查询的每行都要重新计算的子查询 |
| UNCACHEABLE UNION | 属于不能被缓存的 UNION中的第二个或后面的SELECT语句 |
- MATERIALIZED
- 产生中间
临时表(实体) - 临时表自动
创建索引并和其他表进行关联,提高性能 - 和子查询的区别是,优化器将可以进行
MATERIALIZED的语句自动改写成join,并自动创建索引
- 产生中间
2.3. table
- 通常是用户操作的用户表
<unionM, N>UNION得到的结果表<derivedN>排生表,由id=N的语句产生<subqueryN>由子查询物化产生的表,由id=N的语句产生
2.4. type
按照图上箭头的顺序来看,成本(cost)是从小到大
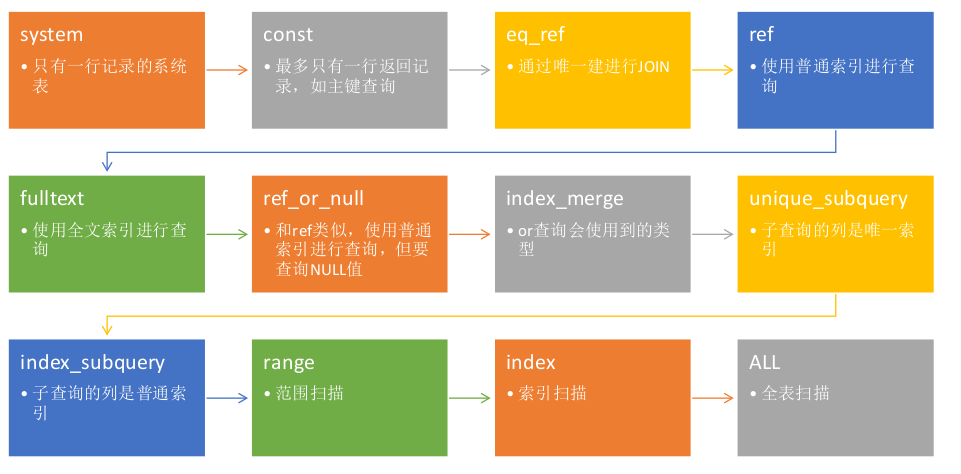
2.5. extra

- Using filesort:可以使用复合索引将filesort进行优化。提高性能
- Using index:比如使用覆盖索引
- Using where: 使用where过滤条件
Extra的信息是可以作为优化的提示,但是更多的是优化器优化的一种说明
016:Explain的更多相关文章
- MYSQL数据库性能调优之三:explain分析慢查询
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句.使用方法,在select语句前加上explain就可以了. 一.explain ...
- explain之二:Explain 结果解读与实践,分析诊断工具之二
MySQL的EXPLAIN命令用于SQL语句的查询执行计划(QEP).这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的.这条命令并没有提供任何调整建议,但它能够提供重要的信息 ...
- Hive底层原理:explain执行计划详解
不懂hive中的explain,说明hive还没入门,学会explain,能够给我们工作中使用hive带来极大的便利! 理论 本节将介绍 explain 的用法及参数介绍 HIVE提供了EXPLAIN ...
- MySQL:explain 和 慢查询日志
1. 执行SQL时显示执行情况 explain + SQL语句 2. 强制使用索引 select * from t force index (a) where a between 1 ...
- MongoDB分析工具之一:explain()语句分析工具
explain(),语句分析工具 MongoDB 3.0之后,explain的返回与使用方法与之前版本有了很大的变化,介于3.0之后的优秀特色和我们目前所使用给的是3.0.7版本,本文仅针对Mongo ...
- mysql:explain分析sql
对于执行较慢的sql,可以使用explain命令查看这些sql的执行计划.查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看 mysql> explain ...
- mysql优化:explain 和 profile
此文转自:https://blog.csdn.net/hanjungua8144/article/details/84317829 一.SQL查询语句优化基本思路和原则 优化更需要优化的Query.定 ...
- Python练习题 016:猴子吃桃
[Python练习题 016] 猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个.第二天早上又将剩下的桃子吃掉一半,又多吃了一个.以后每天早上都吃了前一天剩下的一半零一个.到 ...
- No.016:3Sum Closest
问题: Given an array S of n integers, find three integers in S such that the sum is closest to a given ...
随机推荐
- Git 分布式版本控制的常见命令
Git 的作用: (1)方便多人协同开发; (2)方便版本控制 Git 分布式版本控制的主要区域及命令图,下面会详细讲解: 创建项目并将切换至项目目录下 1. 创建本地仓库: git init ...
- va_start、va_arg、va_end、va_copy 可变参函数
1.应用与原理 在C语言中,有时我们无法给出一个函数参数的列表,比如: int printf(const char *format, ...); int fprintf(FILE *s ...
- 20165202 2017-2018-2 《Java程序设计》第6周学习总结
教材学习内容总结 Ch8 String类: 程序可以直接使用,String类不能有子类 - 构造String对象 使用String类声明并创建对象 String s = new String(&quo ...
- LINUX系统下的shell命令---diff、cut、sort、uniq等
1)diff:比较两个文件或目录的不同 -b 不检查空格字符的不同 -B 不检查空白行 -c 显示全部内容,并标出不同之处 -i 不检查 ...
- zabbix安装收获-WARNING: 'aclocal-1.14' is missing on your system
zabbix server已经安装成功了,在server端也安装了一个agent,一切OK. 在另外一台pg节点上安装zabbix agent时,报错: WARNING: 'aclocal-1.14' ...
- c# 数据库批量插入数据SqlBulkCopy 示例
/// <summary> /// 批量插入数据 /// </summary> public static void SqlBulkInsert(DataTable dt, s ...
- Java基础拾遗(一)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76358391冷血之心的博客) 马上就要秋招了,新的一轮笔试面试马上 ...
- 深入理解Hystrix之文档翻译
转载请标明出处: http://blog.csdn.net/forezp/article/details/75333088 本文出自方志朋的博客 什么是Hystrix 在分布式系统中,服务与服务之间依 ...
- 求序列完美度(trie+贪心)
题目链接: 求序列完美度 题目描述 给出由n个数组成的序列s,规定第i个数s[i]到第j个数s[j]组成的子序列的完美度为该子序列中所有数的和与任意一个不在该子序列中的数进行异或运算得到的值中的最大值 ...
- Python环境准备(安装python解释器)
上篇文章介绍了Python的相关知识,本章就开始着手操作,创建第一个Python程序,在这之前,首先需要配置Python的运行环境,也就是安装python解释器 ------------- 完美的分割 ...