第四篇:使用 CUBLAS 库给矩阵运算提速
前言
编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时。那么有没有一些现成的 CUDA 库来调用呢?
答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库。
本文将大致介绍如何使用 CUBLAS 库,同时演示一个使用 CUBLAS 库进行矩阵乘法的例子。
CUBLAS 内容
CUBLAS 是 CUDA 专门用来解决线性代数运算的库,它分为三个级别:
Lev1. 向量相乘
Lev2. 矩阵乘向量
Lev3. 矩阵乘矩阵
同时该库还包含状态结构和一些功能函数。
CUBLAS 用法
大体分成以下几个步骤:
1. 定义 CUBLAS 库对象
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
4. 调用 CUBLAS 库函数 ( 根据 CUBLAS 手册调用需要的函数 )
5. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
6. 释放申请的显存空间以及 CUBLAS 库对象。( cudaFree 及 cublasDestroy 函数实现 )
代码示例
如下程序使用 CUBLAS 库进行矩阵乘法运算,请仔细阅读注释,尤其是 API 的参数说明:
// CUDA runtime 库 + CUBLAS 库
#include "cuda_runtime.h"
#include "cublas_v2.h" #include <time.h>
#include <iostream> using namespace std; // 定义测试矩阵的维度
int const M = ;
int const N = ; int main()
{
// 定义状态变量
cublasStatus_t status; // 在 内存 中为将要计算的矩阵开辟空间
float *h_A = (float*)malloc (N*M*sizeof(float));
float *h_B = (float*)malloc (N*M*sizeof(float)); // 在 内存 中为将要存放运算结果的矩阵开辟空间
float *h_C = (float*)malloc (M*M*sizeof(float)); // 为待运算矩阵的元素赋予 0-10 范围内的随机数
for (int i=; i<N*M; i++) {
h_A[i] = (float)(rand()%+);
h_B[i] = (float)(rand()%+); } // 打印待测试的矩阵
cout << "矩阵 A :" << endl;
for (int i=; i<N*M; i++){
cout << h_A[i] << " ";
if ((i+)%N == ) cout << endl;
}
cout << endl;
cout << "矩阵 B :" << endl;
for (int i=; i<N*M; i++){
cout << h_B[i] << " ";
if ((i+)%M == ) cout << endl;
}
cout << endl; /*
** GPU 计算矩阵相乘
*/ // 创建并初始化 CUBLAS 库对象
cublasHandle_t handle;
status = cublasCreate(&handle); if (status != CUBLAS_STATUS_SUCCESS)
{
if (status == CUBLAS_STATUS_NOT_INITIALIZED) {
cout << "CUBLAS 对象实例化出错" << endl;
}
getchar ();
return EXIT_FAILURE;
} float *d_A, *d_B, *d_C;
// 在 显存 中为将要计算的矩阵开辟空间
cudaMalloc (
(void**)&d_A, // 指向开辟的空间的指针
N*M * sizeof(float) // 需要开辟空间的字节数
);
cudaMalloc (
(void**)&d_B,
N*M * sizeof(float)
); // 在 显存 中为将要存放运算结果的矩阵开辟空间
cudaMalloc (
(void**)&d_C,
M*M * sizeof(float)
); // 将矩阵数据传递进 显存 中已经开辟好了的空间
cublasSetVector (
N*M, // 要存入显存的元素个数
sizeof(float), // 每个元素大小
h_A, // 主机端起始地址
, // 连续元素之间的存储间隔
d_A, // GPU 端起始地址
// 连续元素之间的存储间隔
);
cublasSetVector (
N*M,
sizeof(float),
h_B,
,
d_B, ); // 同步函数
cudaThreadSynchronize(); // 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。
float a=; float b=;
// 矩阵相乘。该函数必然将数组解析成列优先数组
cublasSgemm (
handle, // blas 库对象
CUBLAS_OP_T, // 矩阵 A 属性参数
CUBLAS_OP_T, // 矩阵 B 属性参数
M, // A, C 的行数
M, // B, C 的列数
N, // A 的列数和 B 的行数
&a, // 运算式的 α 值
d_A, // A 在显存中的地址
N, // lda
d_B, // B 在显存中的地址
M, // ldb
&b, // 运算式的 β 值
d_C, // C 在显存中的地址(结果矩阵)
M // ldc
); // 同步函数
cudaThreadSynchronize(); // 从 显存 中取出运算结果至 内存中去
cublasGetVector (
M*M, // 要取出元素的个数
sizeof(float), // 每个元素大小
d_C, // GPU 端起始地址
, // 连续元素之间的存储间隔
h_C, // 主机端起始地址
// 连续元素之间的存储间隔
); // 打印运算结果
cout << "计算结果的转置 ( (A*B)的转置 ):" << endl; for (int i=;i<M*M; i++){
cout << h_C[i] << " ";
if ((i+)%M == ) cout << endl;
} // 清理掉使用过的内存
free (h_A);
free (h_B);
free (h_C);
cudaFree (d_A);
cudaFree (d_B);
cudaFree (d_C); // 释放 CUBLAS 库对象
cublasDestroy (handle); getchar(); return ;
}
运行测试
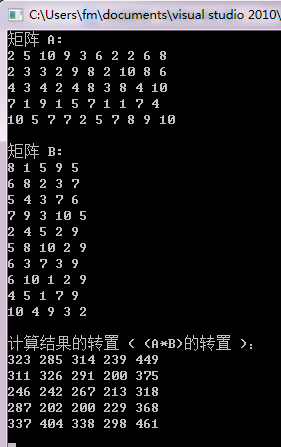
PS:矩阵元素是随机生成的
小结
1. 使用 CUDA 库固然方便,但也要仔细的参阅函数手册,其中每个参数的含义都要很清晰才不容易出错。
2. 如果程序仅使用 CUDA 库的话,用 .cpp 源码文件即可 (不用 .cu)
第四篇:使用 CUBLAS 库给矩阵运算提速的更多相关文章
- 使用 CUBLAS 库给矩阵运算提速
前言 编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时.那么有没有一些现成的 CUDA 库来调用呢? 答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库. 本文将 ...
- [置顶] android调用第三方库——第四篇——调用多个第三方库
0:前言: 在前面三篇中我们介绍了android调用第三方库的形式,在这一篇中我们介绍调用多个第三方库的Android.mk的写法,由于其他三篇介绍的很详细,这里只给出Android.mk的内容. [ ...
- 基于深度学习的人脸识别系统系列(Caffe+OpenCV+Dlib)——【四】使用CUBLAS加速计算人脸向量的余弦距离
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 【第四篇】ASP.NET MVC快速入门之完整示例(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 第四篇 Integration Services:增量加载-Updating Rows
本篇文章是Integration Services系列的第四篇,详细内容请参考原文. 回顾增量加载记住,在SSIS增量加载有三个使用案例:1.New rows-add rows to the dest ...
- 基于GBT28181:SIP协议组件开发-----------第四篇SIP注册流程eXosip2实现(一)
原创文章,引用请保证原文完整性,尊重作者劳动,原文地址http://www.cnblogs.com/qq1269122125/p/3945294.html. 上章节讲解了利用自主开发的组件SIP组件l ...
- 【译】第四篇 Integration Services:增量加载-Updating Rows
本篇文章是Integration Services系列的第四篇,详细内容请参考原文. 回顾增量加载记住,在SSIS增量加载有三个使用案例:1.New rows-add rows to the dest ...
- ESP8266开发之旅 网络篇⑨ HttpClient——ESP8266HTTPClient库的使用
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- ESP8266开发之旅 网络篇⑪ WebServer——ESP8266WebServer库的使用
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
随机推荐
- VC++编写ActiveX控件
ActiveX这门技术是通过生成“*.ocx”文件来实现的.先来了解下OCX文件,在百度百科上面对OCX是这样解释的:“.ocx是ocx控件的扩展名,OCX 是对象类别扩充组件.如果你用过Visual ...
- ItelliJ基于Gradle创建及发布Web项目(二)
上一篇介绍了IteliJ创建WEB项目的过程,这一篇介绍一下和本地WEB服务器(以Tomcat为例)的关联方法和发布流程. WEB服务器的关联 1. 点击IDE右上角的一个带有三角形标识的按钮,如下图 ...
- Node Redis 小试
Redis 是一个高性能的 key-value 数据库,为了保证效率,数据都是缓存在内存中,在执行频繁而又复杂的数据库查询条件时,可以使用 Redis 缓存一份查询结果,以提升应用性能. 背景 如果一 ...
- Python 实int型和list相互转换 现把float型列表转换为int型列表 把列表中的数字由float转换为int型
第一种方法:使用map方法 >>> list = [, ] #带有float型的列表 >>> int_list = map(int,list) #使用map转换 & ...
- Eclipse发布安卓APK包无图标的解决方法
算是一个Bug,清空项目都不行. 解决方法是卸载掉项目,重新导入.
- C/C++:C++伪函数
C++伪函数: 所谓的伪函数.就是说它不是一个真正的函数,而是一个类或者说是一个结构体. <span style="font-size:18px;"> #include ...
- jq使用自定义属性实现有title的tab切换
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- 1.3 Seven Testing Principles
1.3 Seven Testing Principles 2015-06-23 Principle 1 - Testing shows presence of defects(测试显示存在缺陷) Te ...
- Lucene用法10个小结 (zhuan)
http://www.cfanz.cn/index.PHP?c=article&a=read&id=303149 *********************************** ...
- 删除CNNIC根证书
操作方法: 1.点击IE工具菜单-->选项-->内容-->证书,在受信任的根证书颁发机构中找到CNNIC Root,将证书导出到桌面备用. 双击CNNIC ROOT查看这个证书的属性 ...