机器学习:项目流程及方法(以 kaggle 实例解释)
一、项目目录
- (一)数据加载
- 基础统计
- 特征分类
- 基本分布(scatter)
- (二)数据分析
- 正态性检验
- 偏离度分析 (hist | scatter)
- 峰度分析 (hist | scatter)
- 分散度分析 (box)
- 特征本身分散度
- SalePrice 的分散度
- 方差齐次检验
- 方差分析 (bar)
- scipy.stats.f_oneway()
- pandas.Series.corr()
- 协方差分析(-1~+1)
- 协方差热图 (heatmap)
- 协方最大关联图 (pairplot)
- 正态性检验
- (三)数据处理
- 无效数据处理
- 无效特征处理
- 离群点处理
- 缺失值处理
- NaN和NA的处理函数
- 数值量:min,max,mean
- 字符量 -- 仅做类型转换
- 标准化(Normalization)处理
- 离散量编码
- One-Hot Encoding
- 分组-均值-排序数值化
- 以SalePrice为参考的数据
- 没有房价可做基准的数据处理
- 无效数据处理
- (四)机器学习
- 模型
- MXNet
- pytorch
- TensorFlow
- PaddlePaddle
- 训练
- 炼丹
- 预测
- 模型
二、数据加载
1)read_csv() 读取数据时,自动处理了 na_values 的数据
pd.read_csv(file, ... na_values=None, keep_default_na=True, ...)- na_values:遇到该参数指定的字符时,即解析为 np.NaN(float型),无论此列是数值型orobject型。
- 默认值:
'', '#N/A', '#N/A N/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan','1.#IND', '1.#QNAN', 'N/A', 'NA', 'NULL', 'NaN', 'nan'.
- keep_default_na:
- True:将csv 文件中的数字or字符串与 na_values 的 default 值进行匹配,命中即解析为 np.NaN
- False:
- na_values=[...] :与自定义的 na_values 匹配,命中即解析为 np.NaN
- na_values不赋值:不解析相关字符串,保留为原字符串,副作用:会把数值型的feature错误的认成 object 型 —— so,不可取
2)特征分类
- 目的:为了方便后续的数据处理——将 object 类型特征的字符量数据转化为 number;
一般从两个维度分类:
- object 型特征、非 object 型特征(一般是 numeric 特征)
- 离散型特征(一般为)、连续型特征
- 通常需要将离散的字符量 --(转变为)--> 离散的数值量
- pandas.read_csv() 得到的 dataframe 的column类型(df.dtypes)与特征的对应关系:
- int,float —— 数值量(连续和离散)
- object —— 字符量(离散)
- 虽然 column 是 object的,但具体里面的值是 'str'、'float'(NA值是float)
三、数据分析
1)分析的主要内容
- 正态性分析:使用 hist(直方图)和 scatter(散点图)展示
- 分散度分析:使用 box(箱线图)展示
- 方差齐次分析:
- 方差分析: 使用 bar(柱状图)展示
- 协方差分析:使用 heatmap(热图)展示
2)正态性分析
常用的方法:
正态概率纸法夏皮罗维尔克检验法(Shapiro-Wilktest)科尔莫戈罗夫检验法偏度-峰度检验法
- 偏度 - 峰度检验法
1、偏离度分析(hist | scatter)
1)偏度:统计数据分布非对称程度的数字特征。
**注:一组数据的偏度及峰度越大,该组数据的分布越不对称;
2)表征概率分布密度曲线相对于平均值不对称程度的特征数
3)偏离度是某一特征(即:某一列)自己的特性,不同于相关性(某两列之间)特性
思想:一组随机离散的数据,默认其分布是对称的;
方法:假设特征数据是随机离散的,如果改组特征数据的分布不对称,则判断改组特征数据中可能出现了异常值;
疑问:每种特征都有其存在的实际意义,这种实际意义就是一种规律,特征数据是按照其存在的实际意义进行分布的,可以看做是随机离散的吗?2、峰度分析(hist | scatter)
1)峰度:描述总体中所有取值分布形态陡缓程度的统计量。
** 注:这个统计量需要与正态分布相比较;
A)峰度 == 0:表示该总体数据分布与正态分布的陡缓程度相同;
B)峰度 > 0:表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;
C)峰度 < 0:表示该总体数据分布与正态分布相比较为平坦,为平顶峰。
D)峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大。
2)kurtosis,peakedness —— 峰度、峰态系数。
3)表征概率密度分布曲线在平均值处峰值高低的特征数。
4)峰度是和正态分布相比较而言的统计量,反映了峰部的尖度。
5)峰度大于三,峰的形状比较尖,比正态分布峰要陡峭。
6)可用峰度来检验分布的正态性。
7)在实际应用中,通常将峰度值做减 3 处理,使得正态分布的峰度0。
思想:峰度(Kurtosis)衡量实数随机变量概率分布的峰态,峰度高就意味着方差的增大是由低频度的大于或小于平均值的极端差值引起的。
方法:一组特征数据的峰度偏高高,说明该组特征数据中出现了数量较少的大于或小于平均值的极端数据;3)分散度分析(box)
- 目的:查看异常的特征值;(用于修改样本的异常特征值,或者删除异常样本)
- 方法:查看每组特征数据的分布情况,找到异常的特征数据;
- numeric 类型特征的分散度(box)
1)上四分位点:Q3,75% 位置的数据;
2)下四分位点:Q1,25% 位置的数据;
3)中位数:Q2,50% 位置的数据;一组数据中间位置的值;
4)上/下边缘:一组数据的最大值和最小值;
5)异常值:箱形图上,在 Q3 + 1.5IQR 和 Q1 - 1.5IQR 处画两条线,与中位线一样的线段,两条线段为异常值截断点。
* 也就是:x > Q3+1.5IQR 或者 x < Q1-1.5IQR,则 x 数值为异常值;
6)IQR:四分位距,IQR = Q3 - Q1- boxp(盒图)
目的:查询没有意义的特征;(用于删除无效特征)
方法:通过 SalePrice 相对于特征的分布情况,以及房价相对于特征的分布趋势,得到特征与房价的相关性,进而刷选出相关性不强的特征;分析上图
箱型图基本可以看做散点图的加强版:
散点图:可以看出基本趋势;
箱线图:可以一眼看出均值、主范围之内值的趋势,可以看出异常值的多少。
现象:几乎所有异常值都是向上异常,即超出上界(上面的那根横线);
分析:说明了所有不在随大流的售价都是高价,没有地板价、吐血价、大甩卖价的大量出现,博弈中明显卖方占优。4)方差分析(bar)



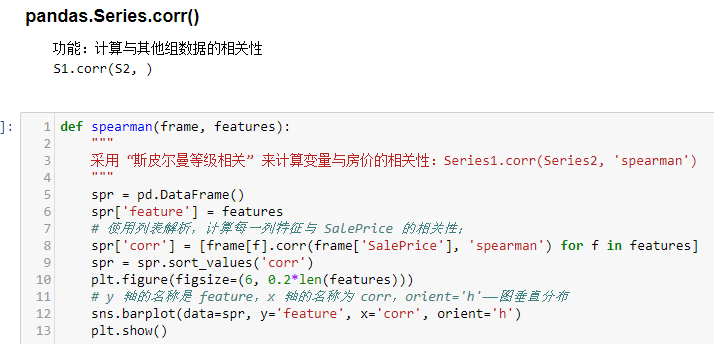
5)协方差分析







B)将数值型特征的 np.NaN 替换:min、max、mean
C)先将字符型特征的 'NA' 替换:仅做类型转换;(方便后续编码操作:将 'NA' 编码成数值型)
如果有 np.NaN 的特征值,将其从float类型的 NaN 转变为char的"NA";因为这些'NA'都是有意义的,不是缺失,而是某个特定含义值。
3)离散量编码
目的:字符量转为数值量;

注:个别特征,train 中没有 NA,但在 test 中有 NA,需要单独处理
检测 all_data 中是否还有 np.NaN
机器学习:项目流程及方法(以 kaggle 实例解释)的更多相关文章
- ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程
ng机器学习视频笔记(十六) --从图像处理谈机器学习项目流程 (转载请附上本文链接--linhxx) 一.概述 这里简单讨论图像处理的机器学习过程,主要讨论的是机器学习的项目流程.采用的业务示例是O ...
- Hands on Machine Learning with sklearn and TensorFlow —— 一个完整的机器学习项目(加州房地产)
数据集地址:https://github.com/ageron/handson-ml/tree/master/datasets 先行知识准备:NumPy,Pandas,Matplotlib的模块使用 ...
- Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型
Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型 项目主体三个部分 ui界面,中间层,数据库 按照不同的比重可以分为一下三个模型 哑铃型 橄榄型 直板型 哑铃型 开 ...
- Django 小实例S1 简易学生选课管理系统 1 项目流程梳理与数据库设计
Django 小实例S1 简易学生选课管理系统 第1章--项目流程梳理与数据库设计 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 1 项目流程梳理 ...
- Sklearn 与 TensorFlow 机器学习实战—一个完整的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目.下面是主要步骤: 项目概述. 获取数据. 发现并可视化数据,发现规律. 为机器学习算法准备数据. 选择模型,进行训练. ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- 28款GitHub最流行的开源机器学习项目,推荐GitHub上10 个开源深度学习框架
20 个顶尖的 Python 机器学习开源项目 机器学习 2015-06-08 22:44:30 发布 您的评价: 0.0 收藏 1收藏 我们在Github上的贡献者和提交者之中检查了用Python语 ...
- 3.Scikit-Learn实现完整的机器学习项目
1 完整的机器学习项目 完成项目的步骤: (1) 项目概述 (2) 获取数据 (3) 发现并可视化数据,发现规律. (4) 为机器学习算法准备数据. (5) ...
- 一个完整的机器学习项目在Python中演练(三)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
随机推荐
- Linux服务器静态路由配置
转载自:点击打开链接 静态路由是在路由器中设置的固定的路由表.除非网络管理员干预,否则静态路由不会发生变化.由于静态路由不能对网络的改变作出反映,一般用于网络规模不大.拓扑结构固定的网络中.静态路由的 ...
- shell脚本实例一
一. 什么是shell 脚本时一种解释性语言: shell脚本保存执行动作: 脚本判定命令的执行条件 脚本来实现动作的批量执行.二.如何创建 vim test.sh ##shell脚本一般都 ...
- Xen,VMware ESXi,Hyper-V和KVM等虚拟化技术的原理解析
Xen,VMware ESXi,Hyper-V和KVM等虚拟化技术的原理解析 2018年04月03日 13:51:55 阅读数:936 XEN 与 VMware ESXi,Hyper-V 以及 K ...
- (三) ffmpeg filter学习-编写自己的filter
目录 目录 什么是ffmpeg filter 如何使用ffmpeg filter 1 将输入的1920x1080缩小到960x540输出 2 为视频添加logo 3 去掉视频的logo 自己写一个过滤 ...
- 基于tensorflow的增强学习
可以通过下面的连接查看这个项目工程: https://github.com/reinforceio/tensorforce 通过这遍文章来了这个项目的使用: https://reinforce.io/ ...
- nginx and node.js配合使用 helloworld
nginx是最好的反向代理服务器. Node.js是... 好吧 ,不介绍了,猛击这里 现在小介绍下怎么用nginx和node.js配合使用. 先写个helloworld.js var http = ...
- 在FP与DDD的道路上越走越远
托辞 最近一口气读了若干本FP方面的书,可人是越来越懒了,要整理个什么东西却也没有那个精力,所以简单扔几张图,算是给自己一个提醒吧. 在此期间,我用并不纯熟的Scala和Groovy练了一把手.虽然只 ...
- flexcan controller register
/********************************************************************* * flexcan controller register ...
- ranch分析学习(三)
接着上一篇继续研究 上一篇结尾的时候,我们谈到了连接,监听两个监督树,今天我们就来看看这两个监督树和他们的工作者都是干什么的,怎么实现的.文件编号接上篇. 6. ranch_acceptors_sup ...
- IT NEWS WebSite
1.http://stackoverflow.com/ 2.google news 订阅 3.(IOS/Android/Java/Html5/JavaScript..)weekly 4.http:// ...